人工智能与概率建模结合的科学智能应用(偏医学影像这块)#
贝叶斯世界观: 频率学派:概率是固定的,但是是未知的。贝叶斯学派是认为数据是变化的,过去可以影响未来的计算,主观信念的衡量(a measure of subjective degree of belief)。PRML很经典
网络主要调整的就是似然P(D|θ,M),这个也是我们得到的似然观测
邱锡鹏---大模型理论与方法第二次课 (20240910)#
- language model (statistic language model) 本质上是一个序列模型,最开始和神经网络没啥关系。NLP早些年是用语法(grammer)的方式来进行生成,画语法结构树,但有些可能还是会有歧义。后续有发展叫统计语言模型,语义是在上下文中进行理解的,概率估计要基于一个大的语料集(corpus),语料集的构建一个很重要的概念是去重。n-gram模型,通过减少条件概率中的condition的影响因素,将完全的时间时刻考虑为一个划窗内的观测,可以极大的减少参数量,通过划窗的方式来对语料库中进行统计,从而得到是句子的概率。但有个问题,这里的N要取多大是个问题,之前受限于算力,可能取到5就够用了。所以只能生成比较短的东西
n-gram问题:如果出现新词的话概率会为0(language model smoothing可以解决,比较老了);domain gap;context太短导致感知能力不够?;同义词没办法做共享;这里的P暂时没考虑时序的问题;
大家能想到的生成的方式实际上不多,图像上一个是GAN一个是defusion,生成的过程实际上也是从数据当中进行采样的过程。
自回归模型,上一步的输出会作为下一步的输入,,上面所述是一种自回归模型。Q:从左到右展开和从右到左展开有什么区别。Beam Search感兴趣可以看看。
- neural language model 为了更好的建模未见过的一些东西,引出该方法。predict next token(word),语言模型本质上是预测整个模型的分布,而不是简单的做预测,神经网络有很多经验性的东西,以及直觉性的东西,所以要多去尝试。
在使用神经网络之前,要将每个词转为一个向量(词表,word vector/word embedding),时序问题要考虑同样的词是否用相同的向量来表示。利用网络可以让同义的word embedding学的比较接近。后面很多人用RNN网络来进行时序的预测
RNN不是自回归,当将上一个时刻的输出变为下一个时刻的输入的时候会变成自回归。RNN是一个隐变量的转移,RNN对于语言模型最大的优点是可以处理语言模型的变长的问题。GRU,LSTM,RNN整体的网络的形式是类似的,主要的区别在与映射函数的设计. 但RNN有long -term dependency的问题, 看不了太远,现在通常和attention模型(global交互建模)进行结合,主要把之前的长程的信息来进行选择,从而解决长程依赖问题, 网络捕获长距离依赖(long-term dependency)的能力下降。CNN为什么适合做序列建模:他本来就是滑动窗口,也可以做空间聚合。CNN比RNN难学?所以在自然语言里面主要用RNN居多。
CNN和RNN模型都隐含一个bias,所有的机器学习模型都有偏置(bias),CNN的bias在窗口这块,随着卷积层数加深会更加关注于全局,隐含偏置使先局部的,在全局的。而这些偏置在语言上未必是成立的。有些词non-local进行组合的,需要依赖于transformer进行解决。
双向RNN,将h拼到一起,具有前向和后向感知的能力。transformer出现后这些经典的网络不怎么太用了。
大语言模型的创新点在什么地方或者说本质的区别是什么?一般来说模型的参数越大,拟合的能力也就越强。之前的语言模型一般在预测下一个词,或者平滑生成语言的过程(看起来对就可以),但他不能生成特别长的句子,存在曝光偏差问题(exposure bias)。large language(knowdege) model,看起来是语言,但实际上是知识。通过预测下一个词来记住知识。
- problem
- exposure bias/techer forcing:train-test是存在不一致的,推理的时候是来自于网络本身的输出,这可能是没见过的(可能会乱掉),但训练过程一定是见到的给定的。训练和测试会有个gap(我早上吃了个鸡蛋,但是如果模型预测的是喝,再用鸡蛋取监督是不对的),因此如果某一步出小比较小的偏差,后面的输出会更加离谱,这是小模型的一个问题。当数据量上去后这个问题会得到缓解。
- softmax:因为需要对词表进行求和,以及对所有词表计算相似度,所以这里有一些加速的工作。通过对数据结构进行变换,可以加速对词的查找,sum可以做近似采样(计算梯度的时候),不一定是完整的求和。
有没有一些方法等到快速的词向量表示,word2vec,对网络进行简化,例如直接对前后进行开窗取特征,之后对特征进行平均进行近似。
inference和training的分布不一样,机器学习中称之为协变量偏移。
如何把领域知识注入到大模型之中是一个比较难的问题,并不是说是简单的微调。RAG是一个比较好的领域迁移方式。
扩散模型与生成人工智能 (20240913 第二次课)#
supervised vs unsupervised learning supervised learning Data: (x,y), x is data, y is label(给定ground truth,有标签信号), learn a function to map x->y。对于不同的任务,label的定义会不太一样,CNN将之前的全连接变成了局部连接,大家现在都在做通用场景的
unsupervised learning just data, no labels!learn some underlying hidden structure of the data。无监督本质上给定数据,你没有标签。因此只能去分析数据内在的逻辑,包括聚类,主成分分析,概率函数密度估计(density estimation)等。例如 K-means clustering。Principal Component Analysis
weakly supervised learning 弱监督,有监督信号,但监督信号不是x->y的映射关系。weak有三个概念,1. 非精准类别(有关系但更大的类别), 2. 有些数据有标签有些无标签, 3.有噪声的label。 产生伪标签的过程是属于无监督学习,但是也可以划分到weakly supervised和self supervised
self supervised learning 自监督是无标签,但是可以一些方式来生成伪标签。x, pseudo generated y, No manual labels! Learn to generate good features(reduce the data to useful/generic features.)
!!!! 这里加一个图片 supervised vs unsupervised learning
Autoregressive Model Generative Modeling: Given training data, generate new samples from same distribution. 通过对数据进行压缩,通过模型学特征分布,通过学习压缩到一个特征空间上,从而记忆数据的特征,本质上也是数据压缩的过程。生成过程是从原始的输入过程当中进行采样的过程。
因此需要对输入数据进行建模,explicit density estimation,显式的建模。implicit density estiamtion,中间是一个黑盒,隐式的去建模。
Autoregressive Models: A type of statistical model used for time series analysis.
Fully visible belief network(FVBN)
PixelRNN,RNN描述了贝叶斯概率的一个过程,逐像素的去预测实际上是有问题的,因此可以加入CNN来从特征空间上做生成过程效果会更好。
自回归的模型可以显示的计算likehood,p(x), 但是这个还是基于像素或者是局部信息,他是没有全局信息的。
因此引入了Variational Autoencoder(VAE),一次性产生所有的像素,通过引入latent code(z)的方式。Train such that features can be used to reconstruct original data。中间的这个压缩的特征完全不可描述,可以加一个分类器,给定中间特征的监督信号,给一个loss function,进行特征纬度的监督。这里没有明确的控制信号,z的可解释性的问题。利用分类器实际上做特征的正则化。Conditional VAE
扩散模型与生成人工智能 (20240920 第三次课)#
VAE中 z的可解释性的问题,为了防止z过拟合到输入的数据,我们希望z的分布更加的均匀,因此我们会加入KL散度的正则化约束,使其输出具有多样性。
Training GANs: Two-player game GAN不用显示的建模z, 而是引入discriminator Network, 他是一个分类网络。不一定非要联合训练(Discriminator Network),比较简单的方式是先训练discriminator(可以就是一个简单的分类器), 核心是要训练Generator Network。这里面的Real和Fake需要引入大量的人为的标签信息,好和坏是比较难评价的。通过引入条件信息完成生成的可控。
VQ-GAN: 先训练一个codebook(重新看ppt,可以强化其语义属性,可以是resnet或者是clip所谓的backbone),让不可解释的latent code和可解释的codebook进行近似约束。实际上训练的是生成器和判别器部分。
next token prediction没有很强的字数的概念,没有对应的conditional的一个反馈。Autoregressive model是很多工作的前提。
DDPM (Denoising Diffusion Probabilisitc Models) 一个自监督学习的方式,大多数上都是在原图上进行操作,如抠图,或者是加噪声。 sora: world simulator。最难的是运动和运动之间的关系。当有物理属性的变化的时候,生成模型会很有挑战
Diffusion model 刚开个头
邱锡鹏---大模型理论与方法第三次课 (20240924)#
17年为止,循环神经网络是在语言模型里面很常用的东西。条件概率早期主要是输入法部分的一个应用。
只有在注意力机制,或者transformer之后才有位置编码,transformer用的是多头注意力机制,这个注意力机制的概念在以前就已经出现了。transformer中的前馈网络代指的是一个纺锤形的多层感知机(中间层比输入输出大很多,FFN retial?),残差连接()和normalization是为了保证训练的稳定性(Add & Norm),如果层数太多,不加这个可能会训不出来,
用relu函数的点也是在这里,如果连乘太多的会导致梯度消失,因此残差网络会在当前梯度回传的时候出现一个偏置量(1, 不会出现特别小的情况)。sigmoid会对输入的大小太大或者太小不敏感,对于深的网络很难控制值域的分布,因此可以对其进行白化的操作(layer normalization),让其靠近中心点,这样对于其他激活函数的选择会比较友好。
参数矩阵是有一个条件数的概念,最大特征值和最小特征值的比值,反应对输入信号的敏感程度,输入信号的扰动的问题。对于层数比较多的网络,在初始化完一般就是一个比较不稳定的系统,因此没办法预先调整好,只能在每一层中进行动态的调整。
由于CNN对于图像来讲可以对其缩放不敏感,因此可以统一到一个固定的kernal上。语言模型是变长的,所以不方便在语言模型中用CNN。
RNN网络会考虑上一个状态的引变量和当前输入,只可以看到上一个状态,会有遗忘的问题,可以一定程度解决变长的问题。注意力机制中的i和j之间的weight是动态计算的,二元的关系是有一元的特征的组合(), 任意的三元函数f(x,y,z)一定可以写成h(g(x,y),z)的形式,只要建模n元素之间任意两元素之间的关系就好了。语言可以看成一个成分语法树,另一种经典的树结构每个节点都是一个词语。
逆变换采样定理,网络参数是确定的,在高斯或者均匀分布上进行采样,可以通过一个复杂的映射得到目标空间上的一个采样(PDF)
自制力机制 注意力中有三个特征,Query,Key,Value。 Query和Key,softmax变成一个分布,有点类似于每个value的权重的意思。写程序的时候会把Batch提出来,
L是文本的长度,d是文本的特征 为什么这种注意力机制: (B,L,d)(B,d,L)=(B,L,L)(B,L,d)=(B,L,d) 这样可以直接在用于下一层,矩阵操作的灵活的程度
softmax打开去做矩阵的结合律,linear attention,这也是大家主要想加速的点,如果训练超级大的模型可能会用linear attention。

元素i和j之间的关系只和Qi和Kj有关,而Kj的改变不会影响,可以建模上下文无关的文法,但是无法建模上下文有关的文法。因此引入softmax可以让其变成不独立的关系建模,softmax函数让的改变可以影响
从左到右自回归生成是以单词为纬度进行生成,担心维度爆炸,很难直接生成出来。自回归生成靠从左到右生成,非自回归生成有个拆解的问题。
交叉注意力机制 一般俩说,K和V是绑定的,Q是单独的,可以是另外的信号。Q是一个可以学的参数,以Q的方式聚类,Q-former。
一般注意力机制要加掩码(mask), 在神经网络总很难做到信号直接消除,因此会在attention上加softmax(变为-无穷),这是因为补0导致的原因(输入长度的统一),要把对应位置屏蔽掉。在训练过程中往往可以通过掩码的方式将输入的批处理掉(将上三角掩码掉,看起来是时序的,从t-1预测t),可以一次性的进行L-1步骤的推理。但是在推理的时候我们不知道未来的所有信息,所以只能单步的进行推理。
注意力机制会让每个词语的特征趋同,实际上是因为一些不重要的词的累积会导致弱化关键的key部分的贡献,最后层数变多之后会导致词语特征趋同。注意力机制实际上是会看所有的信息的,因此如果想去掉某个信息需要从第一层信息去掉。transformer无关的信息模型也是在利用,有多余关系的错配,是利用海量的数据去消除不相关的影响。
当输入元素比较少的时候,弹头注意力的维度有限。这个和人的直觉是相反的,输入信息有限,已有的注意力机制,则最终会变成很少的特征的线性组合。
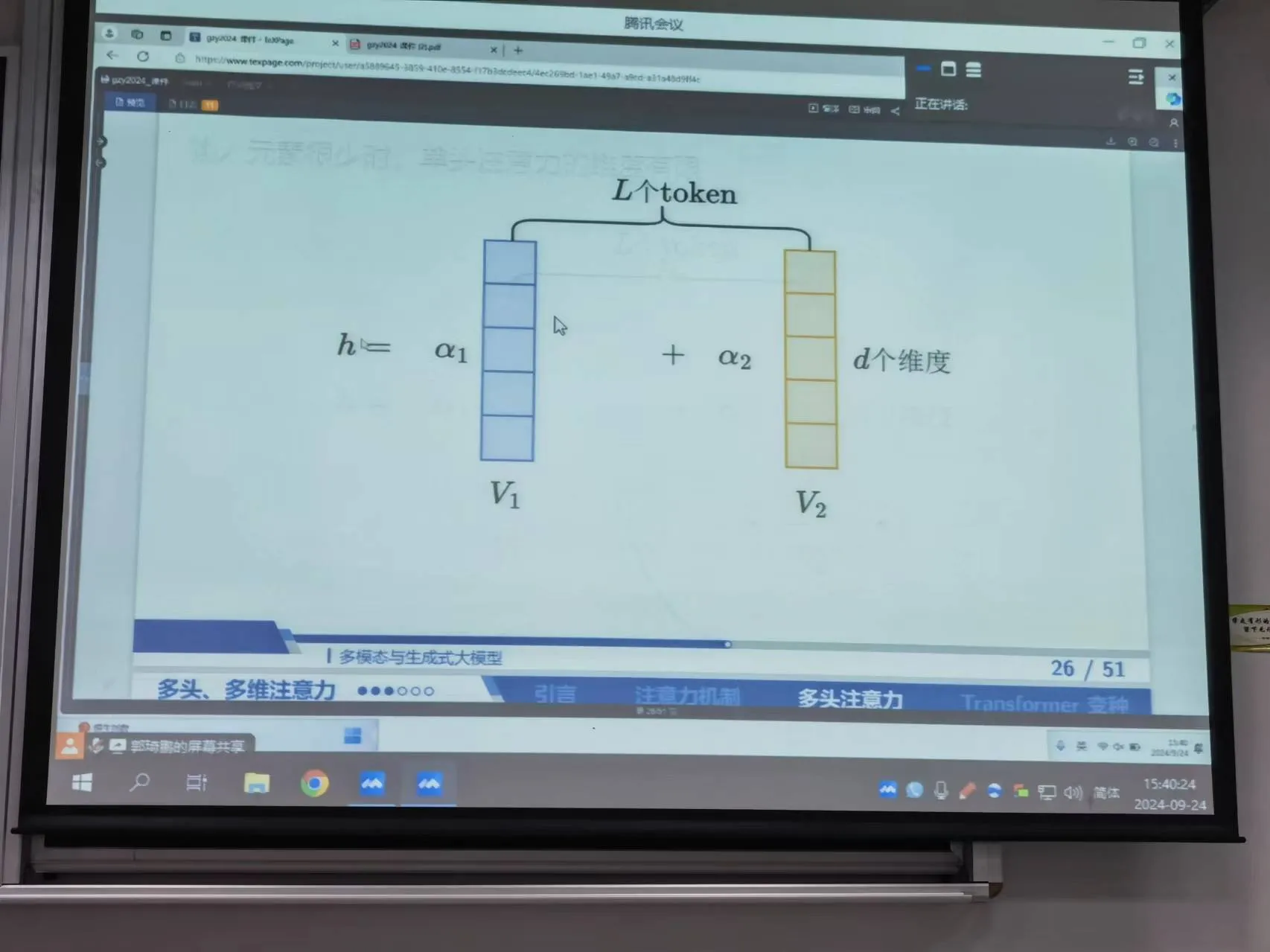
因此可以在每个维度开展注意力机制,每个value的维度都分配不同的权重,进行线性组合

但这种还是过于冗杂,因此将value分组,则组内的是同一个权值,这里是对value,key和queries分别进行分组,之后进行线性组合。这个分组一般不小于64也不会超过256。
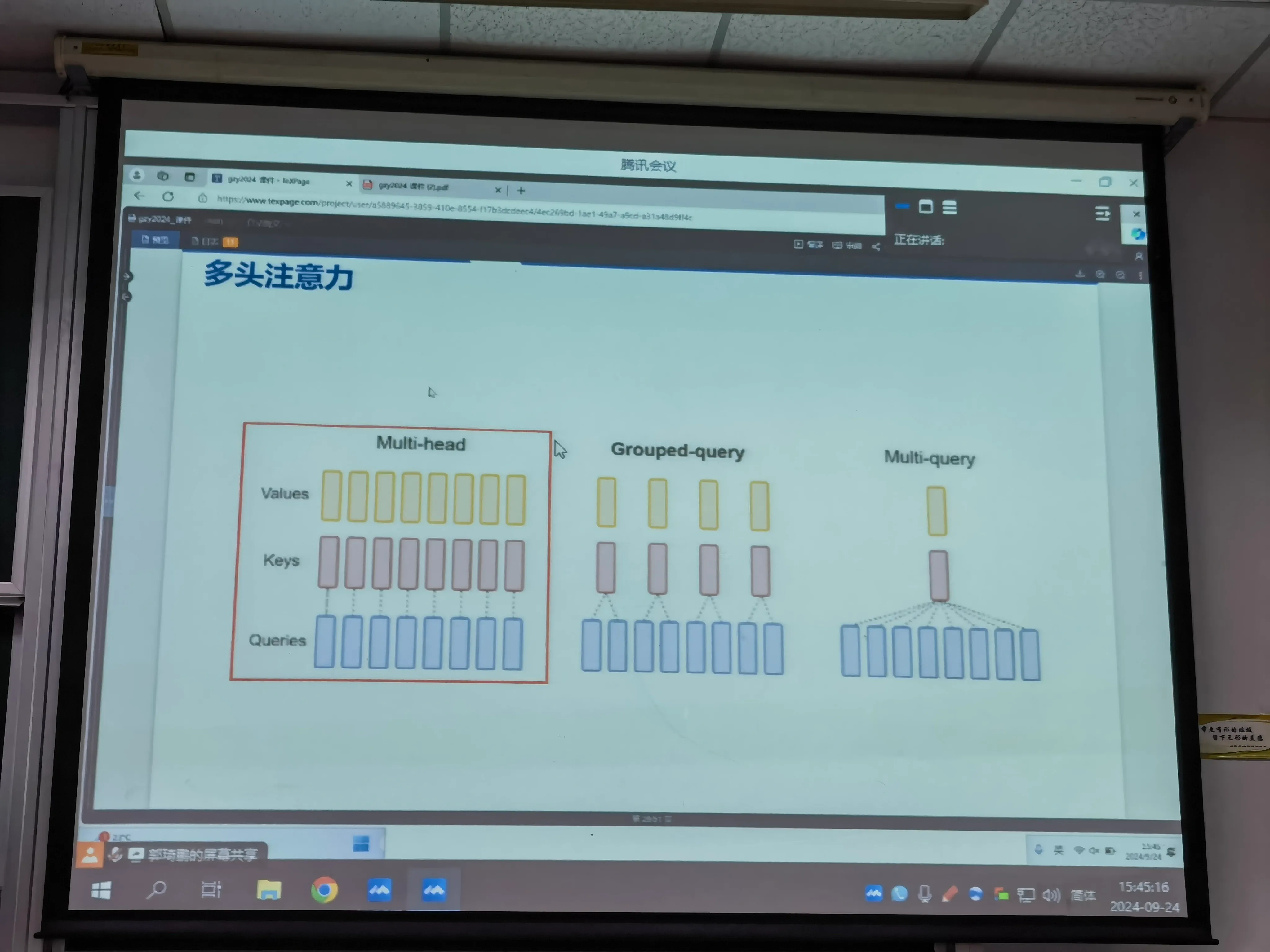
分组后,是最后拼接在过一个W,做分组共享,做分组共享在显存开销上有很大的改进。
Transformer打破了RNN和CNN的经典序列相对不变性。 只是拿到一个特征,可以用一个双向的transformer结构去做,训练的时候可以用完形填空的方式训练,decoder-only只是去看一侧的信息,但是有一定的兼容性的,他还是能建模条件概率当中的某一步的,如果通过全概率公式,之后屏蔽掉之前的输出。注意力可视化,不同的attention head之间会有不同的pattern。
邱锡鹏---大模型理论与方法第四次课 (20241008)#
Universed Representation Transfer learning ,先进行预训练,在transfer到downstream task(Fine tuning) Multitask learning,通过多个task任务来训练一个universed representation
从2018年开始,比较热的领域是预训练模型,也是第二代模型。找到一个预训练任务(有监督,无监督和自监督学习),把通用表示学好。自监督学习中的标签是从输入数据中构建来的(无监督的数据+监督学习的方式)。
监督学习 有大量标注数据的监督任务,例如机器翻译和机器阅读理解(可以去构造一些数据,挖空,质量不高)。Embedding和encoder都是预训练好的,context vector(Que,这块没听到)是带上下文的encoder。
无监督学习 密度估计, 现在的大语言模型都会先做tokenlizer,重新做分词。
OpenAI GPT,Generate encoder,2018年,训练decoder式的方法(transformer),或者是生成式的方法。直观上来讲只利用单向的信息(只看左侧的上下文)显得不够自然,
GPT3(Language Models are Few-Shot Leamers)的模型量很大,GPT这种大模型不太能在下游直接做fine tunning。因此从GPT3开始不再和其他模型比较,主要体现few shot的泛化性。但参数量必须要大。提出新的学习方式
自监督学习 一种监督学习和无监督学习的结合,监督式的学习方式,训练数据由无标注数据自动构建。它是不依赖标注数据,但也是可以提供标注数据的。目标是学习数据中的可泛化知识,任务变的不太重要了。
Masked Language Modeling(MLM),典型的自监督学习,为什么不能用语言模型训练transformer的encoder?encoder的一个词是看两边的,这也就注定了没办法用predict next token的方式去训练,因为encoder部分已经看到了下文,因此就没办法用语言模型的方式去训练,否则会变得简单。Bert 采用masked token的方式来训练encoder,
Seq2Seq Maksed Language Modeling,T5,VAE的方式可以即做理解(encoder)又做生成(decoder),Text-to-Text Transfer Transformer(TS)。训练encoder的方式有很多,
Denoising Autoencoder(DAE),StructBERT(直接mask掉整个sentence),文本上做对比学习是不好做的,
BERT在之后没有新的结构的原因,当蔓蔓扩展参数量的时候,生成式模型的优势就体现出来了。mask language model的任务更加简单,增加数据不能得到更大的收益了。并不能通过mask更过词的方式来记住更多的东西。因此预训练模型也偏向于往生成式的方式来走。
预训练模型的扩展
 把人的结构化知识注入到大语言模型中(Knowledge-Enriched),模型压缩(efficient LLM)
把人的结构化知识注入到大语言模型中(Knowledge-Enriched),模型压缩(efficient LLM)
跨模态语言模型 VL-BERT,image caption Video-BERT,OpenAI DELL-E,OpenAI CLIP(batch内的对比学习),
邱锡鹏---大模型理论与方法第XXX课 (20241203)#
Saycan 大模型工具调用,agent tool use 怎么样让LLM智能体完成物理世界内的具身任务
采样是手工调用出来的?强化学习理论部分要学习一下
实际控制中使用BC-Z模型(模仿学习)的效果会比Q-learning RL模型要好
工具调用 大模型的训练数据是静态的,掌握知识有限且固定。通过结合实时的工具(API),可以获得最新的数据
多轮对话生成更多详细的信息,这是拷打GPT?
Q-Former可以用于模态的对齐,ViT可以完成视觉的编码
思维脸可以将复杂的任务拆解
task planning,将制定目标划分为多个子问题 tool selection。允许llm从提供的工具列表中进行选择,通过检索器进行选择,基于LLM进行选择, tool calling,工具调用,向工具服务器请求数据,调用具体API得到结果的过程 response generation,结合用户查询和知识构建全看的response,分为直接插入和信息整合法