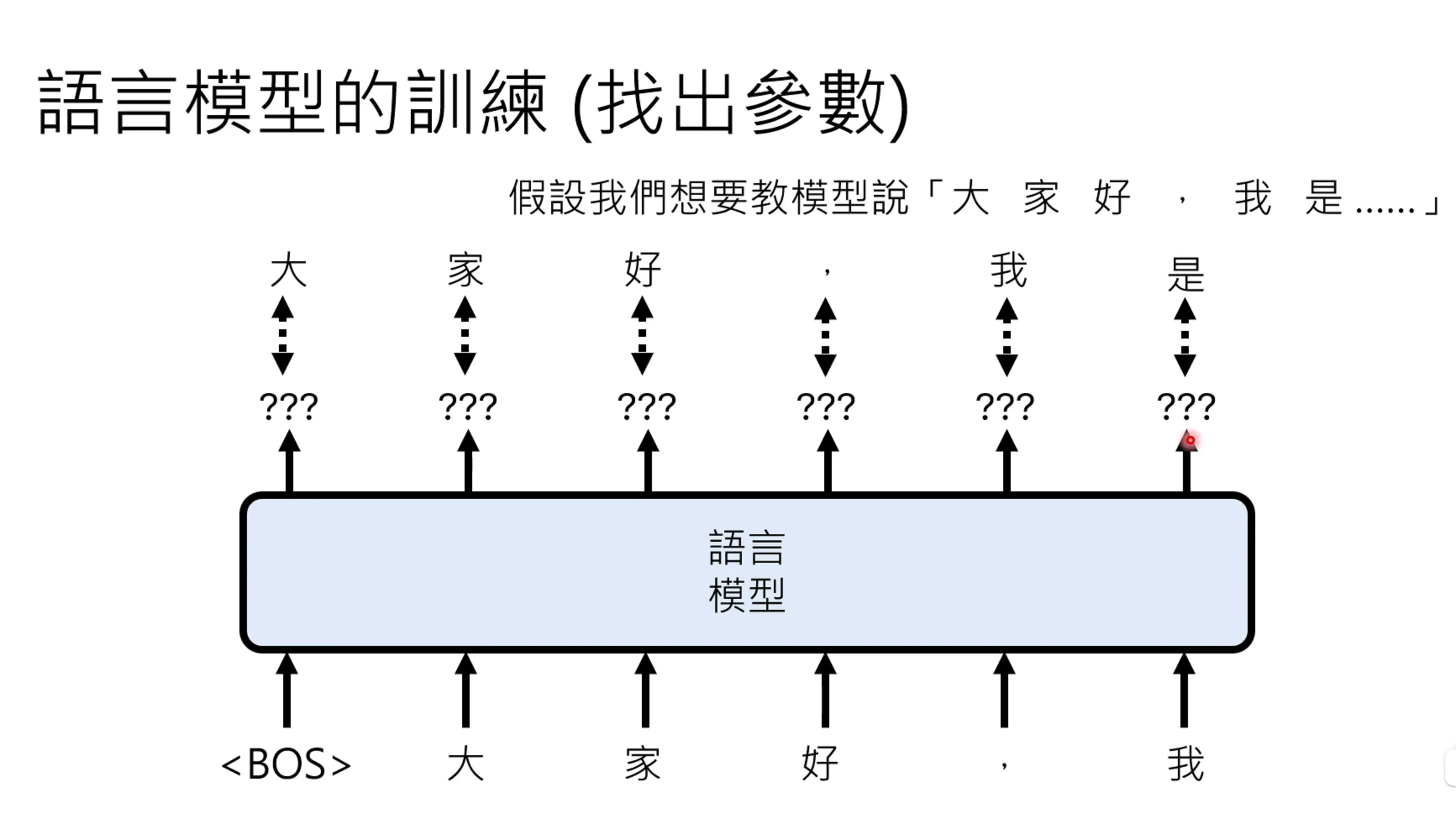
大致看了下官网上李老师的课,是包含24年的生成式人工智能,以及25年的生成式AI背景下的机器学习,这里把这两者统一,按照自己的熟悉的顺序进行整理,一transformer,模型讲解,模型训练和微调的顺序进行学习。
生成式AI时代下的机器学习2025#
AI agent的原理#
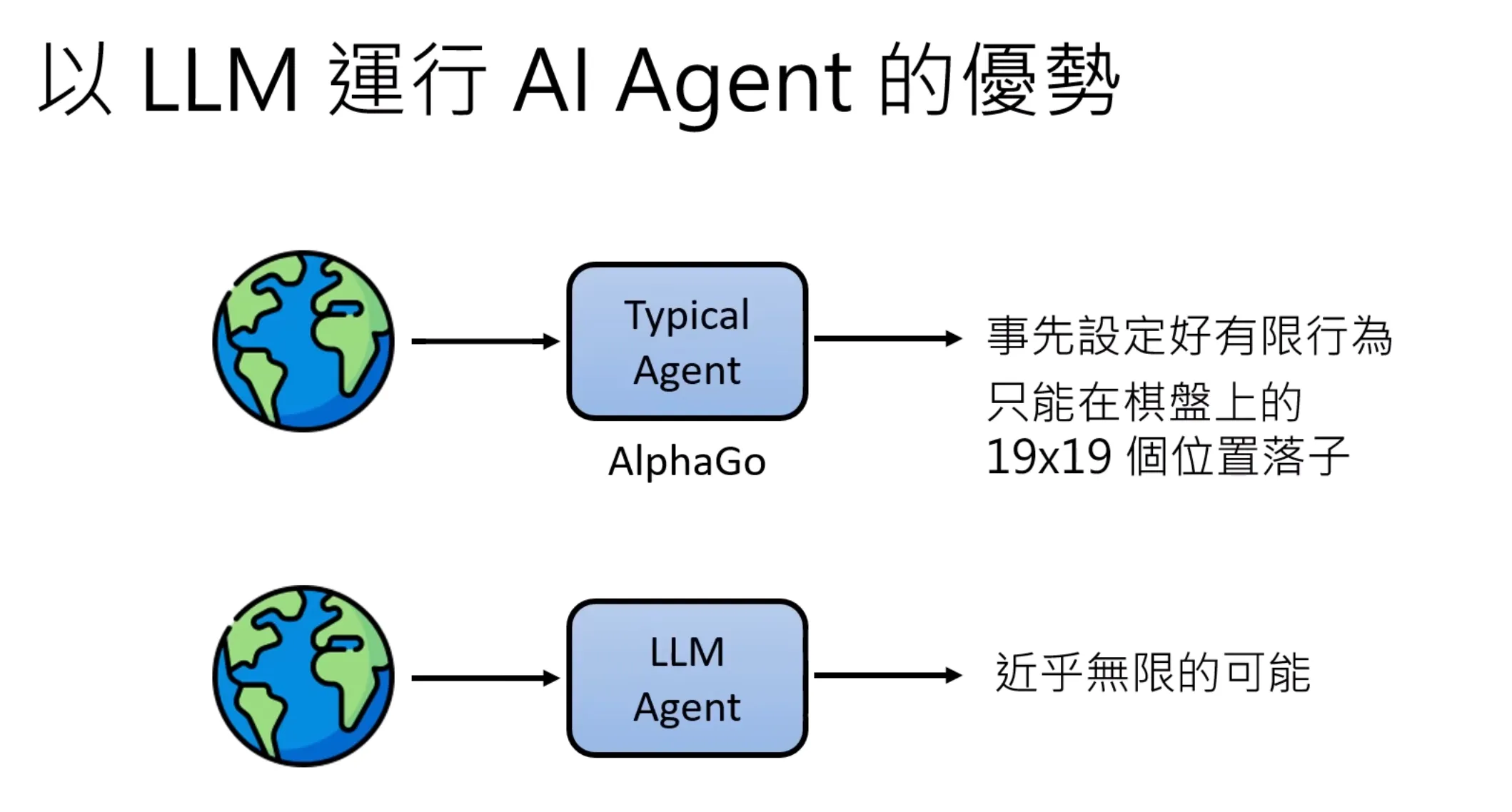
AI agent输入是一个人类基于的目标,AI agent观察当前的状况,分析目前状态来得到决策(action), 而Action回影响环境的状态,从而得到新的Observation,这个操作循环的执行下去,得到了系列的操作,直到Ai agent达成。Alpha GO就是一种AI agent,而这种例子似乎在强化学习也听过。
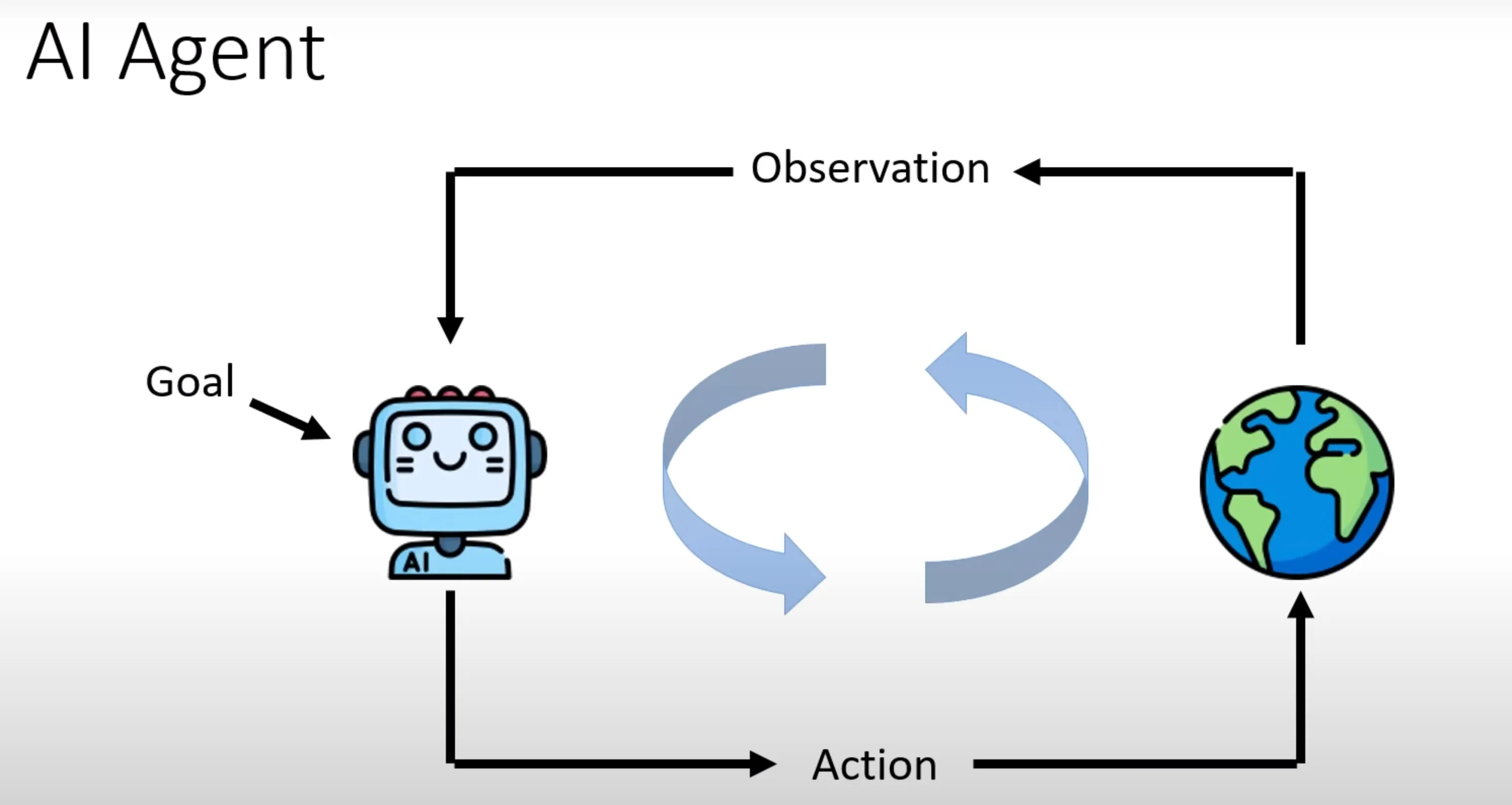
因为强化学习也是一种打造AI agent的方法,但RL方法有个局限,需要为每一个任务单独的去训练一个模型。
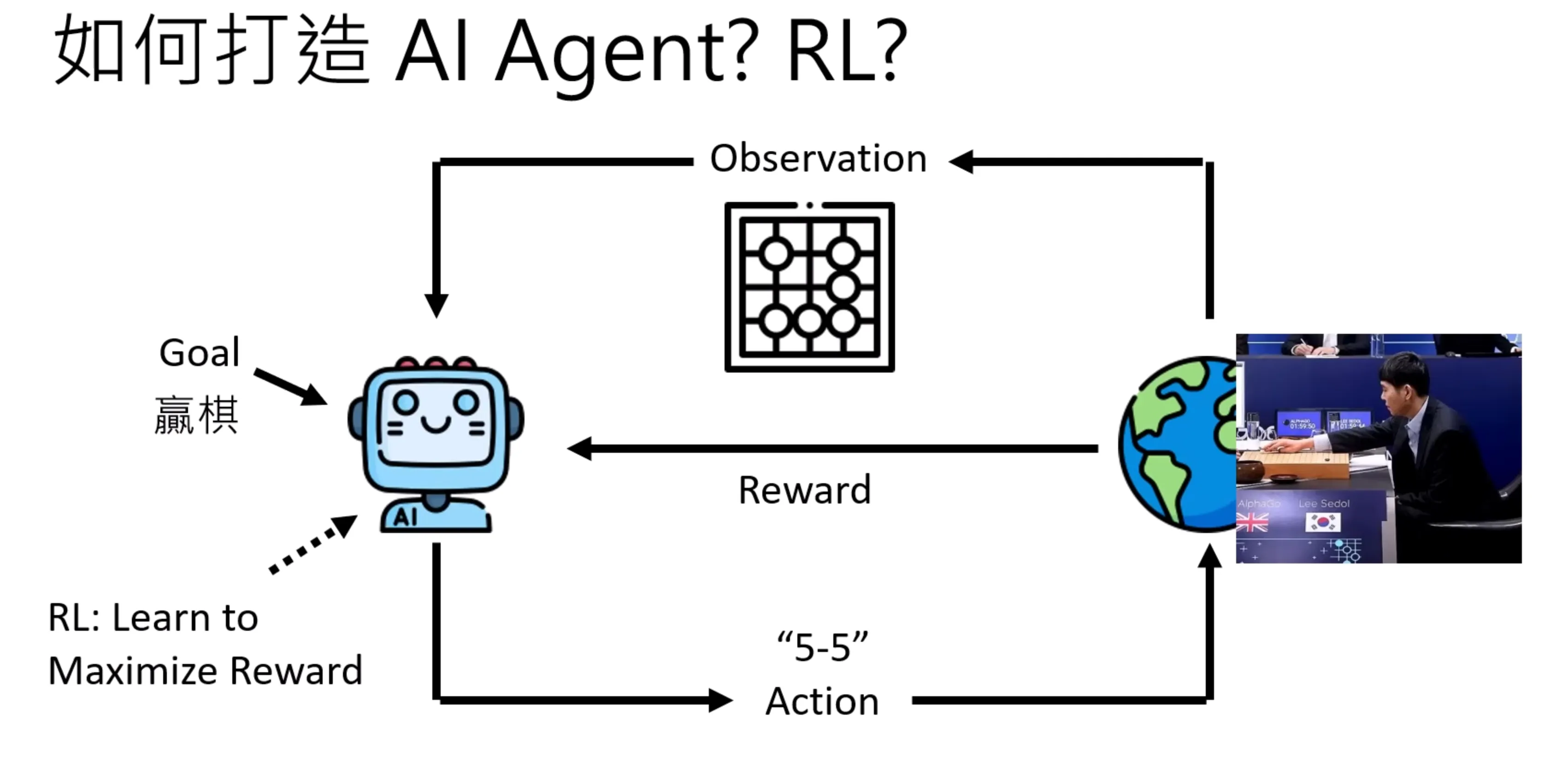
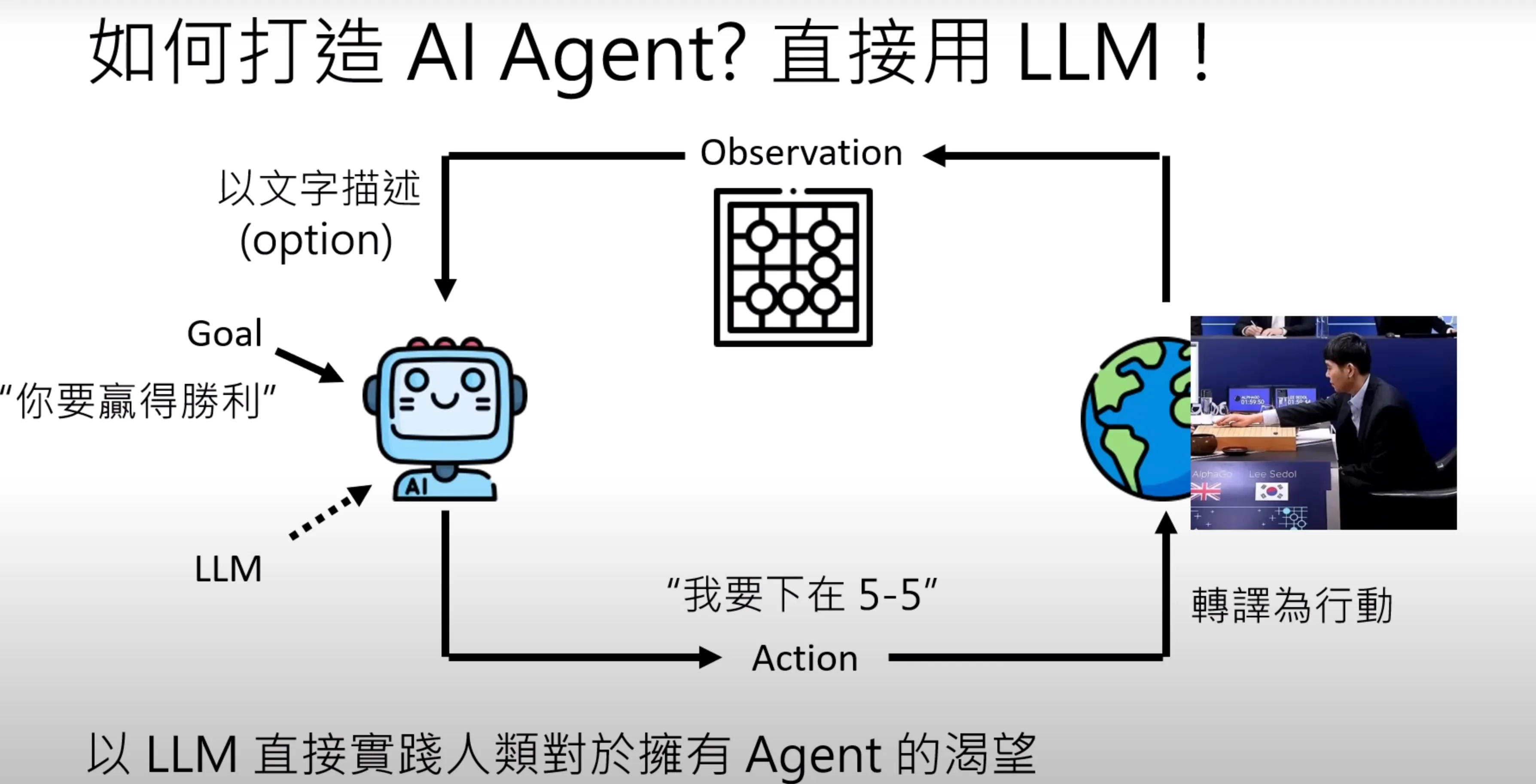
现在人们是将LLM直接作为AI的agent,直接给文字描述,让LLM去做一些事情。而之前是用强化学习的方式去训练一个model使其能够有AI agent的能力。AI agent爆红并不是因为有了和Ai agent有关的技术,而是因为LLM变强后,人们想通过LLM来实现人类拥有agent的渴望。AI Agent本质是一个控制各类工具来解决问题的代理系统。
从语言模型的角度,实际上是通过观测得到动作,再由动作影响环境得到新的观测,一直迭代下去。这个有点像一个接龙的游戏,也是在做next token predict,只不过这个token可能是action的token。这个所谓的Ai agent实际上有点像是语言模型的应用。
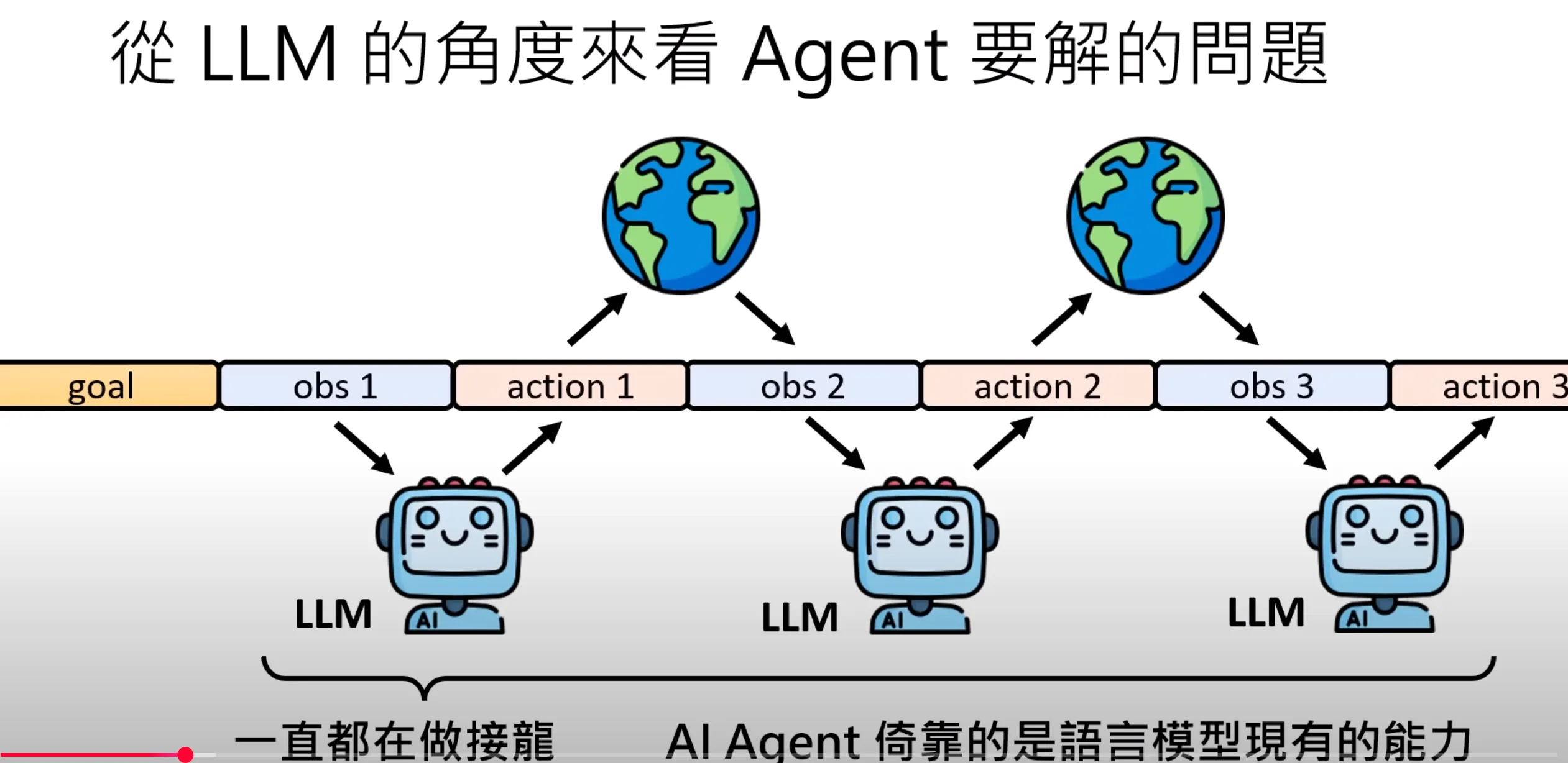 这节课后面所讲的内容都没有任何的模型被训练,都是依靠现有的语言模型的能力完成。
这节课后面所讲的内容都没有任何的模型被训练,都是依靠现有的语言模型的能力完成。
用LLM做AI agent可以让任务变得灵活,而非专有的任务。
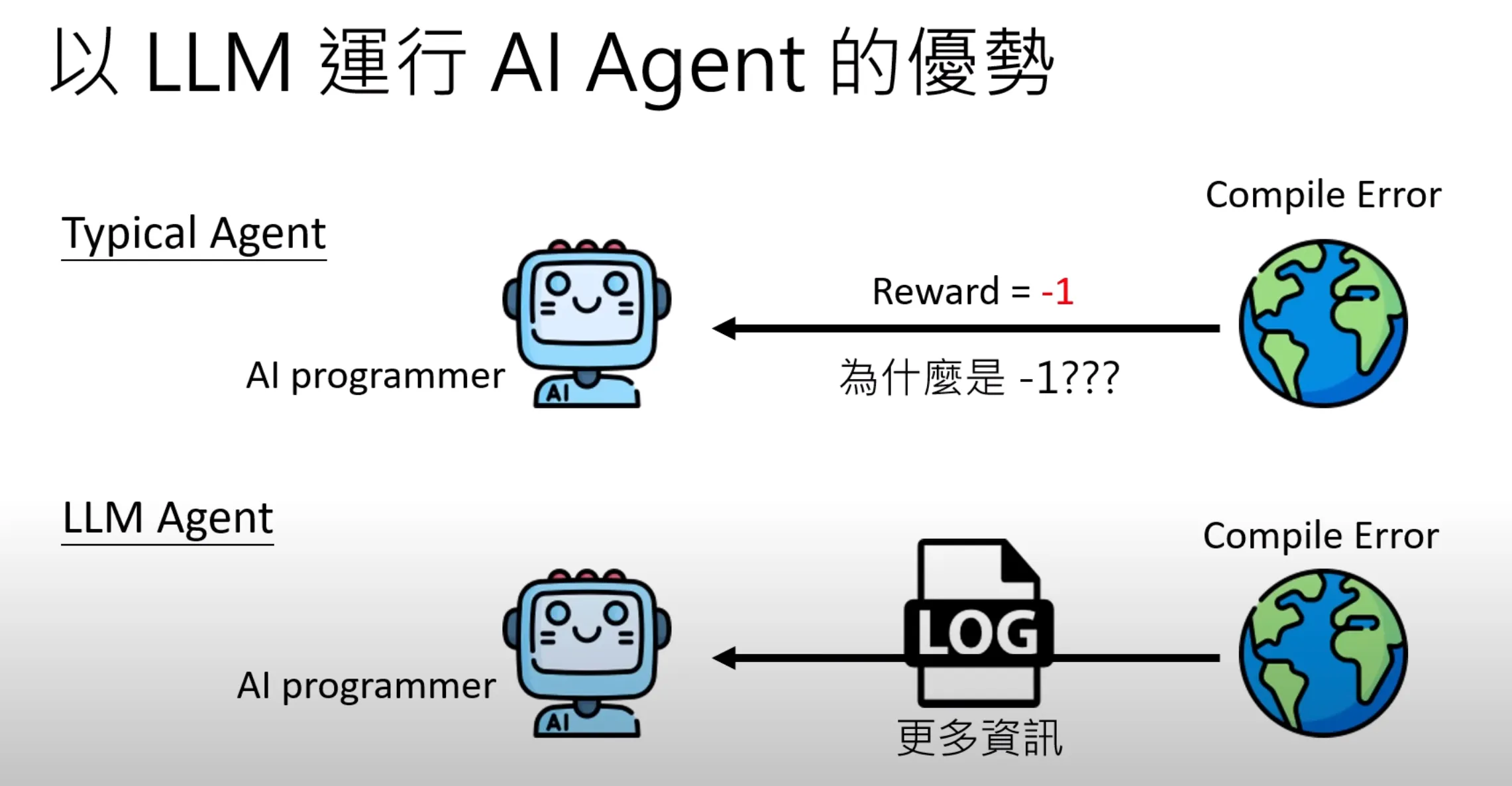
 用强化学习来进行训练,需要显示的给定一个reward,这个reward往往需要调,直接给LLM以原始信息,似乎是一种更加直接,且无损的方式。
用强化学习来进行训练,需要显示的给定一个reward,这个reward往往需要调,直接给LLM以原始信息,似乎是一种更加直接,且无损的方式。
AI agent的几个应用:操纵电脑,训练另一个AI,AI Agent,用AI做研究。之前的说法有点像一个回合制的互动,现实生活中需要及时互动,外界环境可能会变化,
根据经验调整行为#
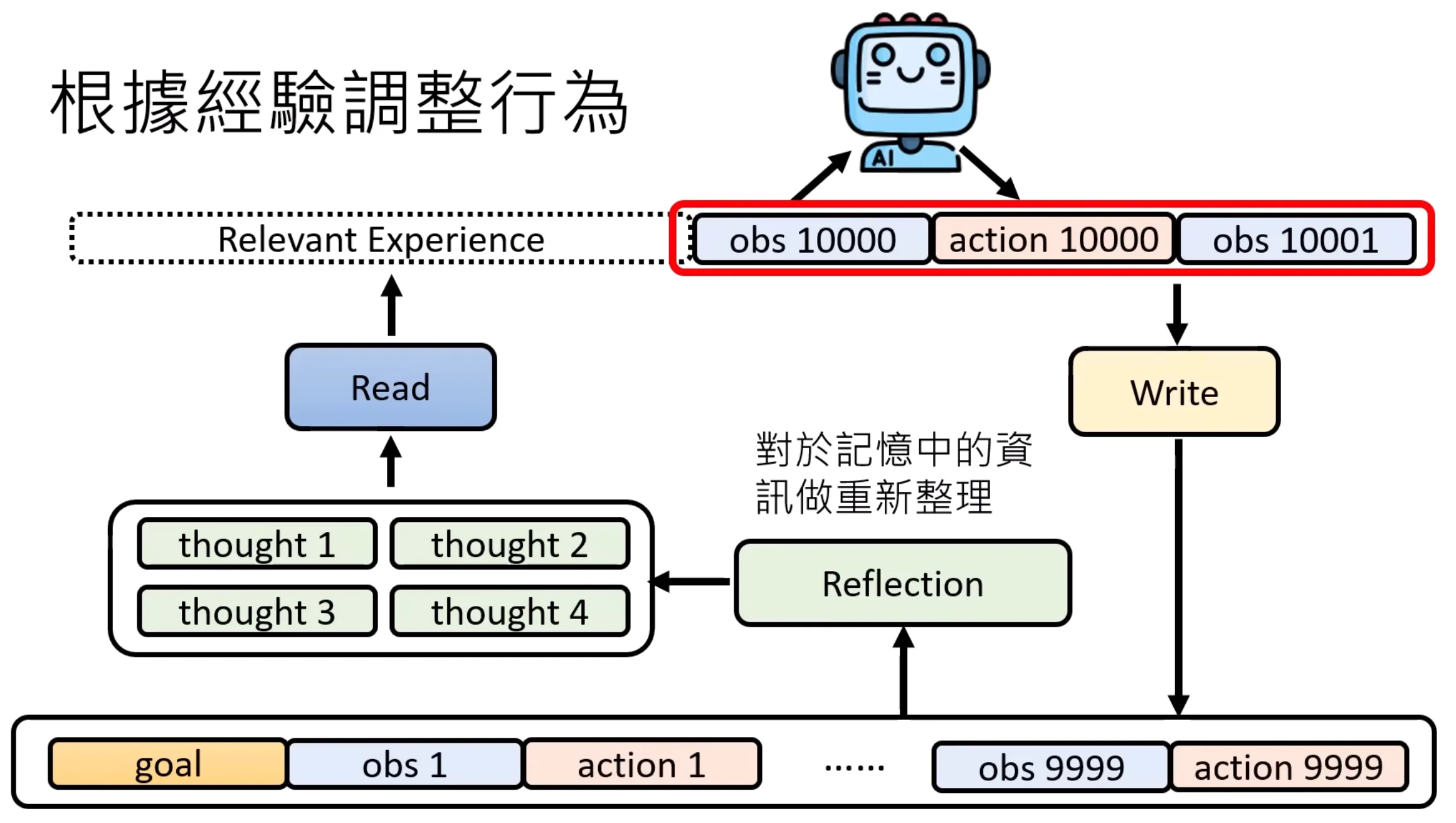
现有的语言模型可以通过回馈来调整对应的动作,而不需要去做模型参数的更新,这样有点像是根据经验调整行为。LLM是可以看到一些历史的信息的,并能够给予更多的输入给出一些更加准确的结果。但受限于算力,没办法对之前的所有信息都记录下来。因此实际上需要从Memory bank中筛选出重要的信息,而这个过程就是一个query的过程,就是从资料库中检索出相关的资讯,这个过程实际上也是一种RAG,只不过一个是自己的经验,一个需要构建外部数据库。
需要注意的是,负面的例子对于语言模型似乎没啥用,只用负面的例子是有害的。从streambench的实验结果上来看,如果混合正负样本实际上结果会比单纯只是用正样本要查,因此这也是说语言模型在训练过程中高质量的数据至关重要!!!
一个很关键的点,是要保证高质量的数据被放入记忆库中,否则memory bank会被填满,上面讲的实际上是read过程的优化,而这里是memory写入过程的优化,可以是一个AI模型,问他是否重要,从而决定是否插入memory bank中。
除此之外,还有一个reflection模组,这个是个反思的模组,针对记忆中的数据进行二次的整理,而不是直接读入。Reflection模组可能也是一个语言模型,
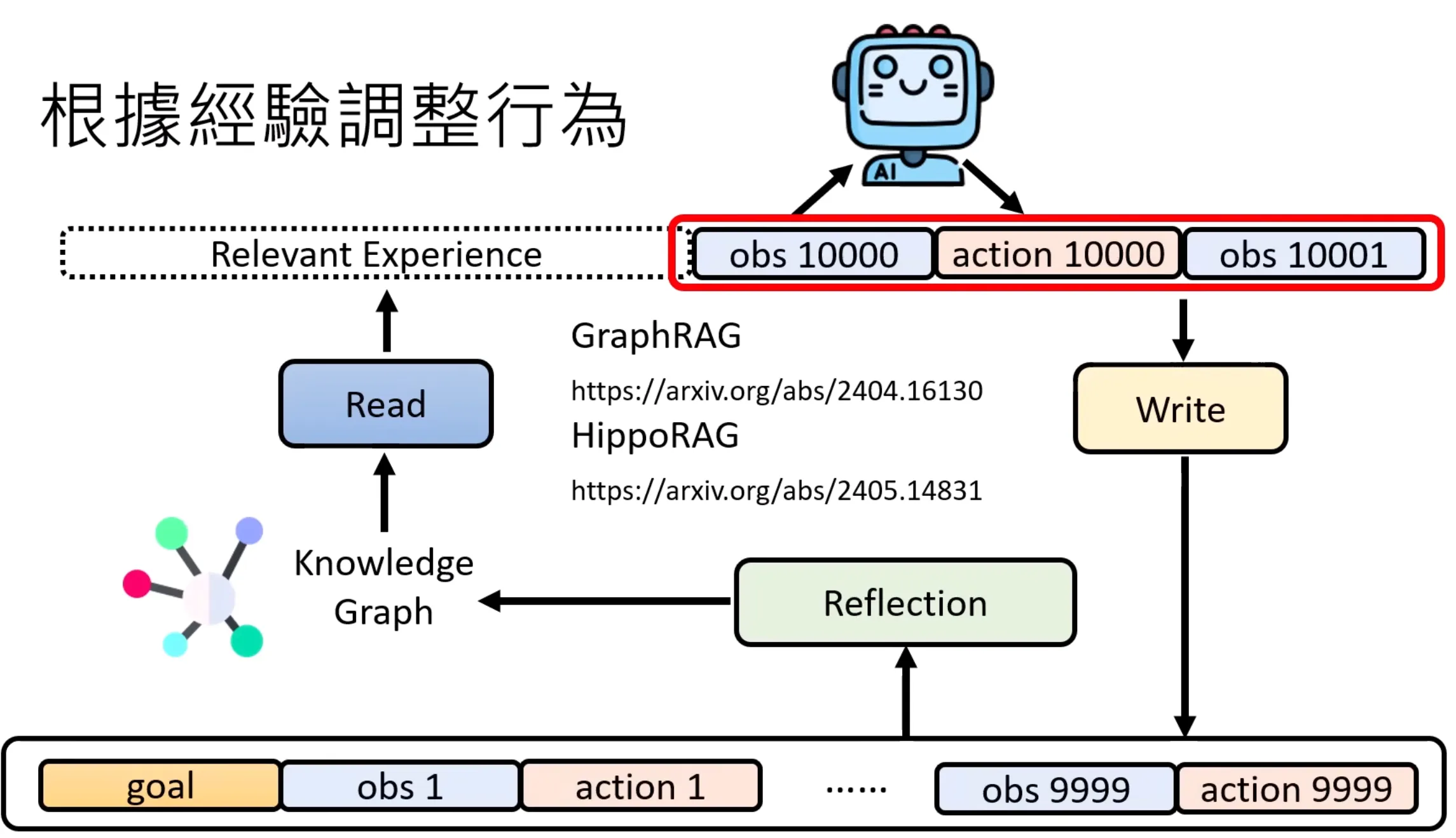
也可以对以前的经验构建Knowledge graph,将资料库变成knowledge graph,再利用knowledge graph的一些研究让RAG的操作做的更好或更有效率。
一些AI agent的研究。
语言模型使用工具#
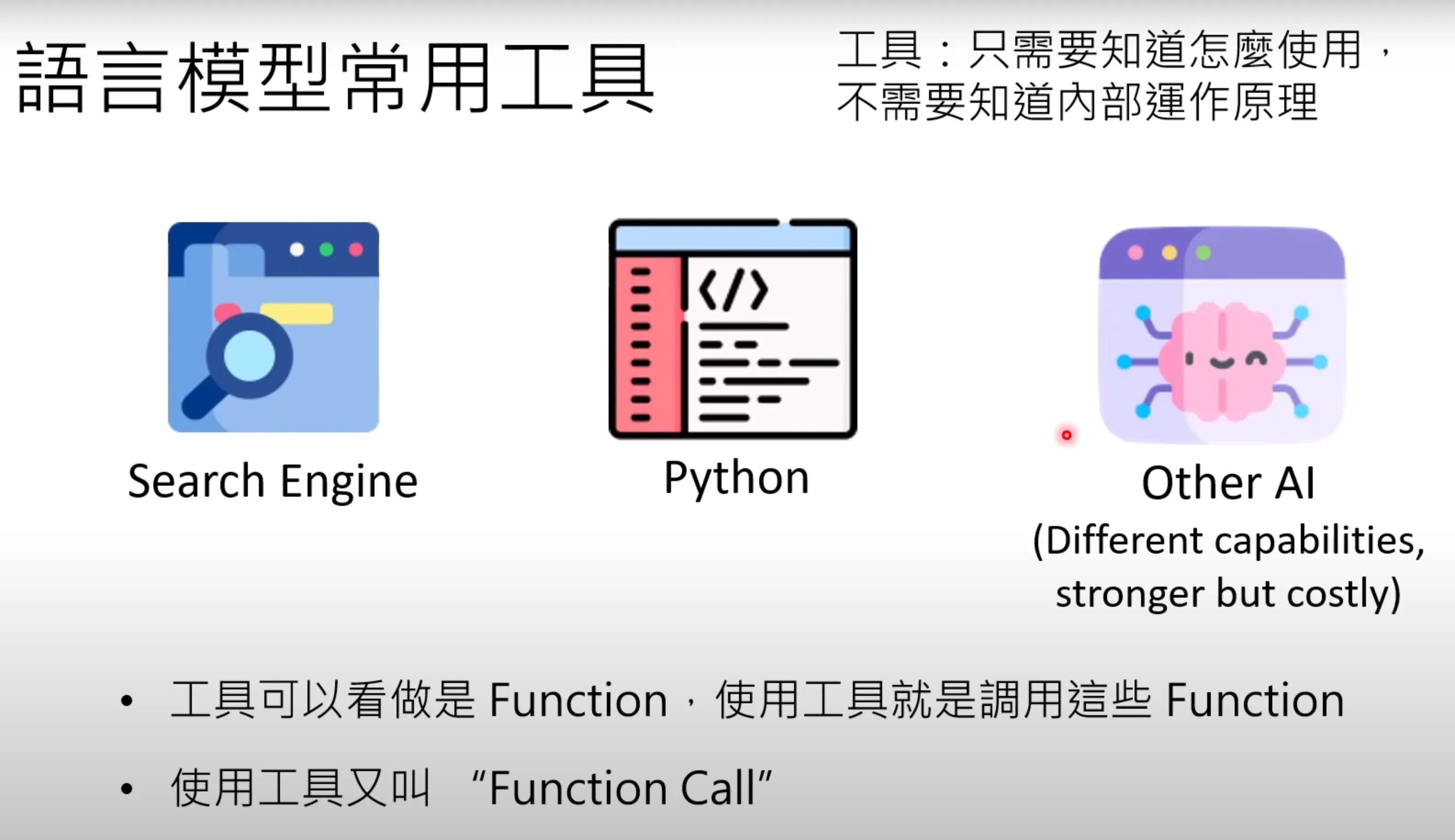
工具只需要知道怎么使用,不需要知道内部的使用原理。工具可以看成是function,使用工具就是调用这些function。
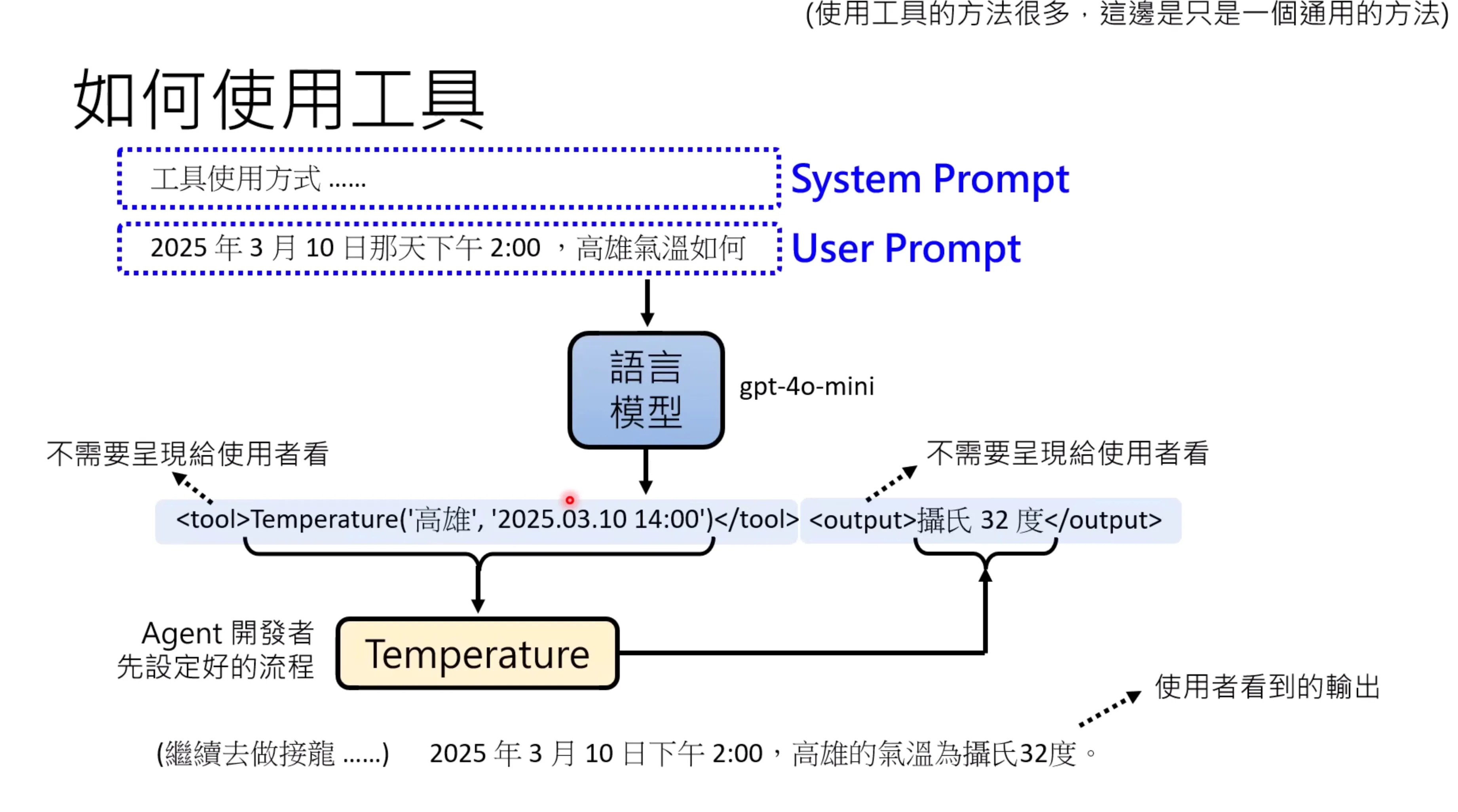
放在需要模型的文字接龙之前的prompt通常是system prompt,而用户给出的一些信息通常称为user prompt。system prompt的优先级比较高。语言模型做的实际上就是给文字接龙,是没办法直接进行call的

语言模型中比较常使用的工具的搜索引擎,Retrieval Augmented Generation(RAG) ,检索增强生成。
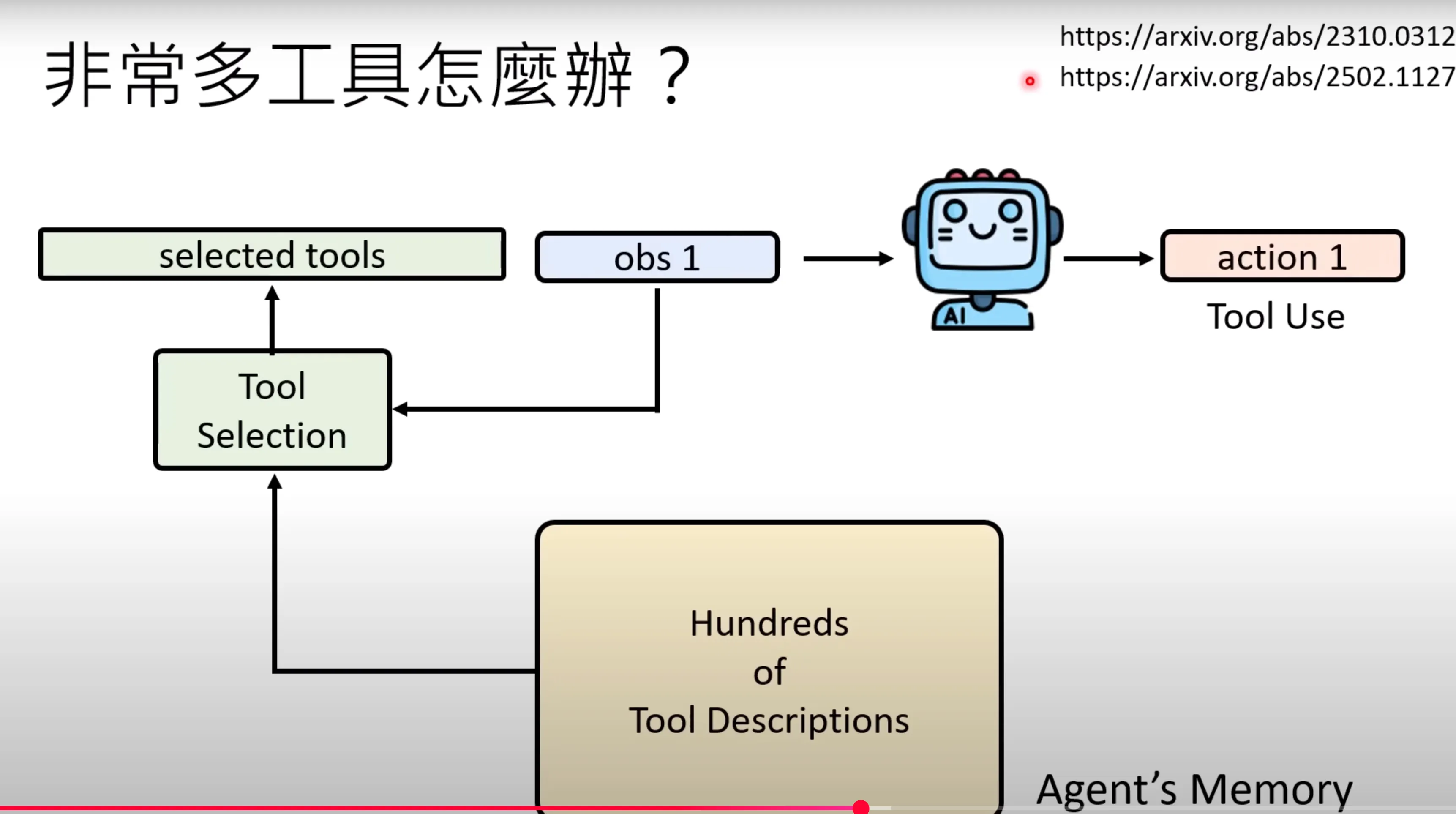
假设工具很多怎么办呢?可以采用类似于agent memory的方式,将工具的描述放在一个agent的memory中,剩下的和RAG方式很像,从工具包中选择工具。
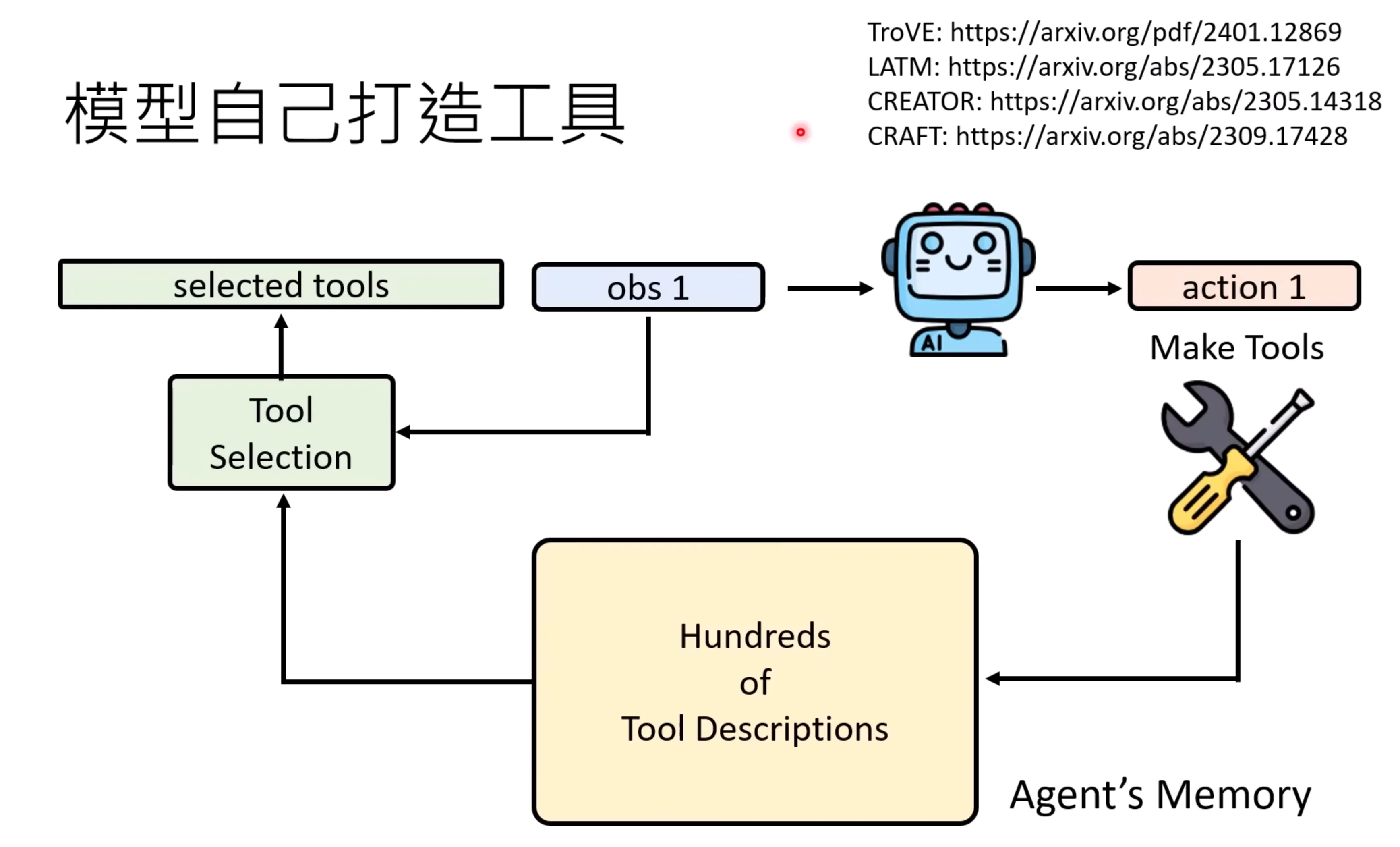
 也可以让模型自己打造工具,这也有一些研究,TroVE,LATM等,核心思想是把打造的工具放在所谓的工具库里面,从而增强其能力。和根据经验来改变行为实际上是非常类似的。
也可以让模型自己打造工具,这也有一些研究,TroVE,LATM等,核心思想是把打造的工具放在所谓的工具库里面,从而增强其能力。和根据经验来改变行为实际上是非常类似的。
外部知识对语言模型的影响#
语言模型在做RAG的时候是Internal Knowledge和External Knowledge一起决定的结果。 当外部给的结果和LLM本身的先验差距过大的时候,模型会保持原有的先验结果。模型在训练过程中给出的信心,实际上也会影响最后给你模型的输出结果。
外部知识对AI的影响,Meta Data:语言模型倾向于相信新的文章,资料的来源对于决策没有影响。
语言模型去做计划#
语言模型达到目标所执行的action可以作为一种plan,需要显示的去问他,
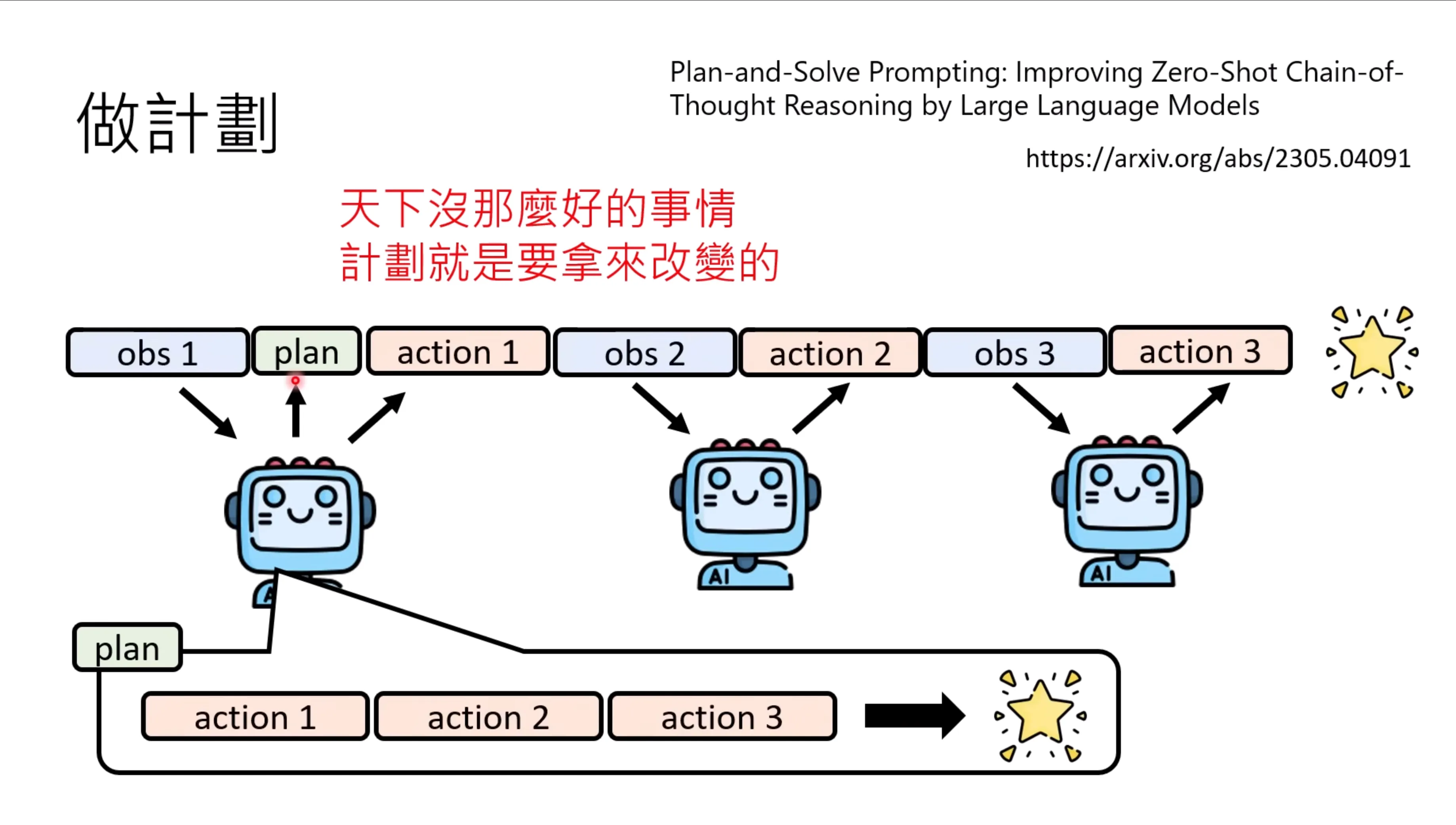 与预期不同,会导致原油的计划可能行不通。一个比较好的方式是每次看到新的observation让需要模型从新来思考计划,看要不要制定新的计划。
与预期不同,会导致原油的计划可能行不通。一个比较好的方式是每次看到新的observation让需要模型从新来思考计划,看要不要制定新的计划。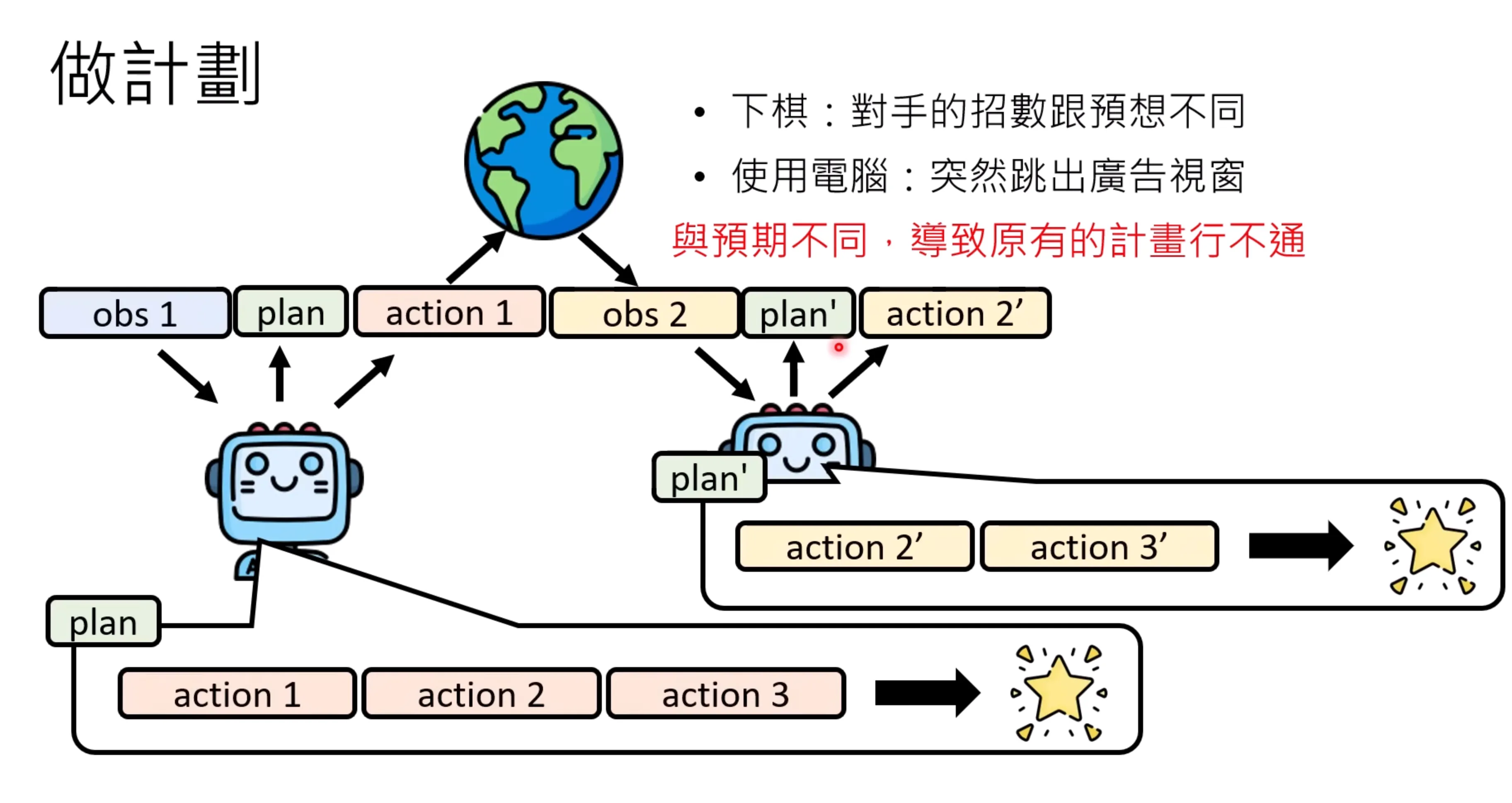
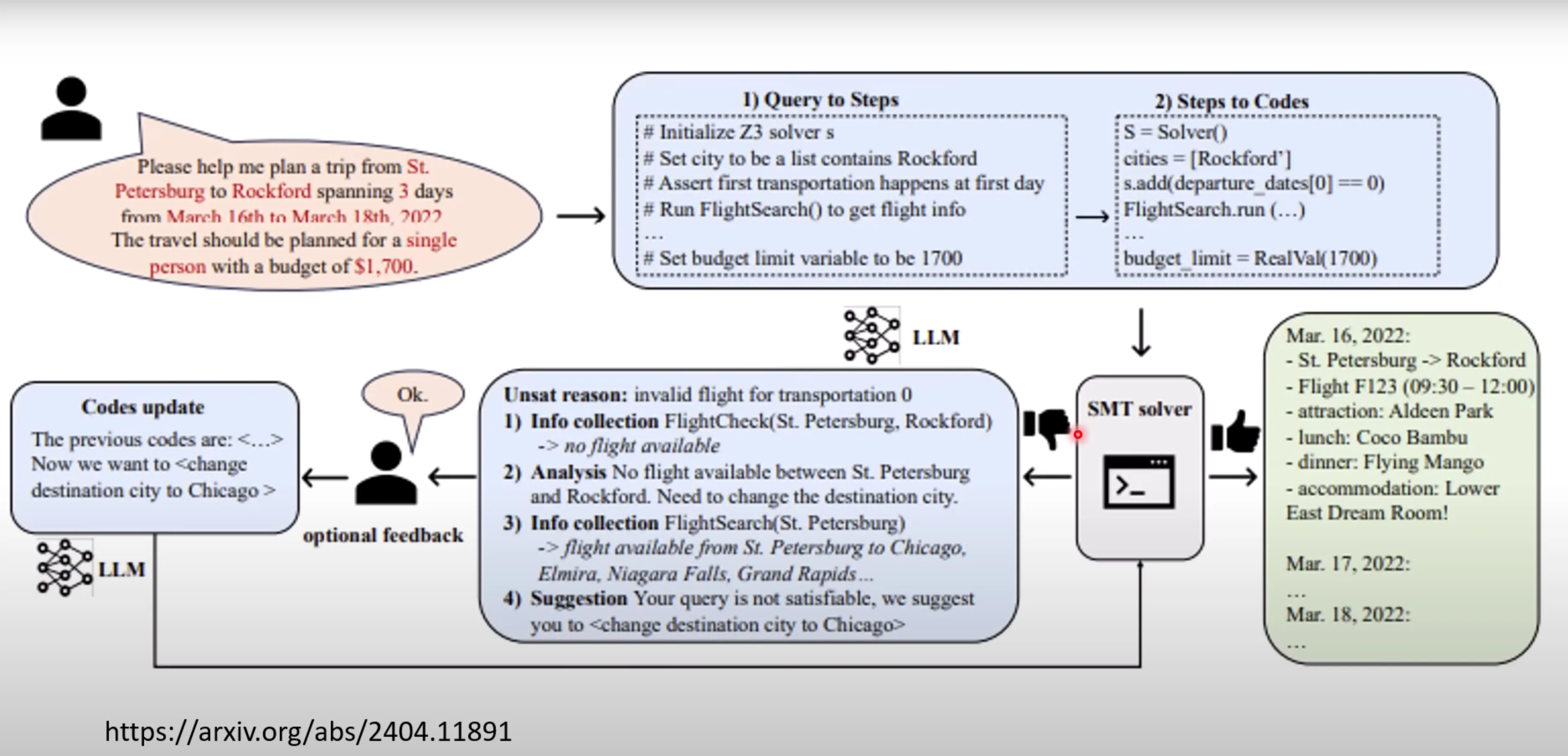
带有工具辅助后,语言模型是可以得到比较好的旅行规划结果的
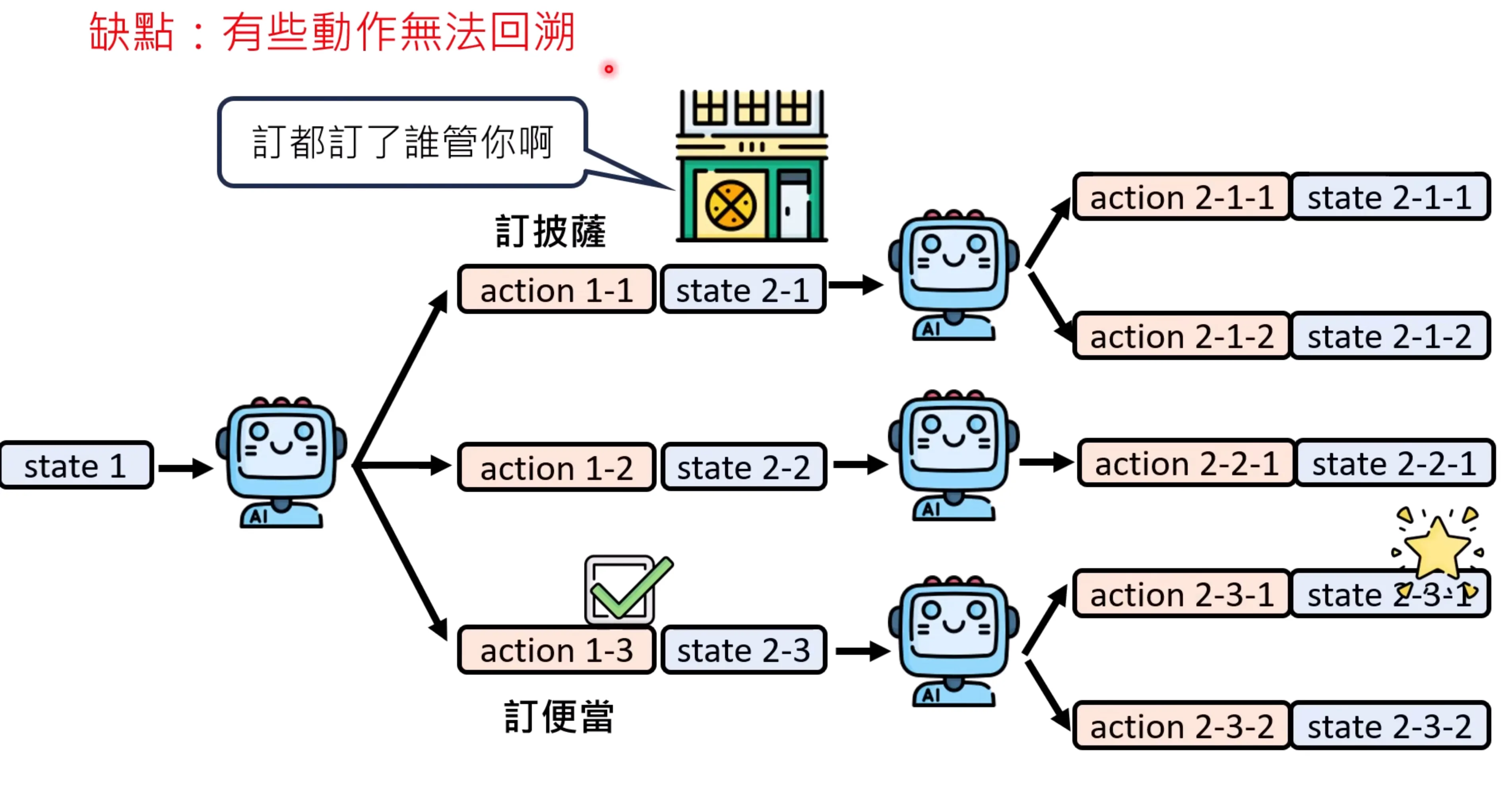
如何强化AI Agent的规划能力呢?一个简单的想法就是对所有的可能进行搜索,也就是爆搜,之后在选择一条合理的路径,但这样做是不对的,路径太长了是没办法弄的。一个可行的方法是将不可能的路径进行剪枝,让模型判断可能性,可以减少搜索路径。但有些动作是没办法进行回溯的。
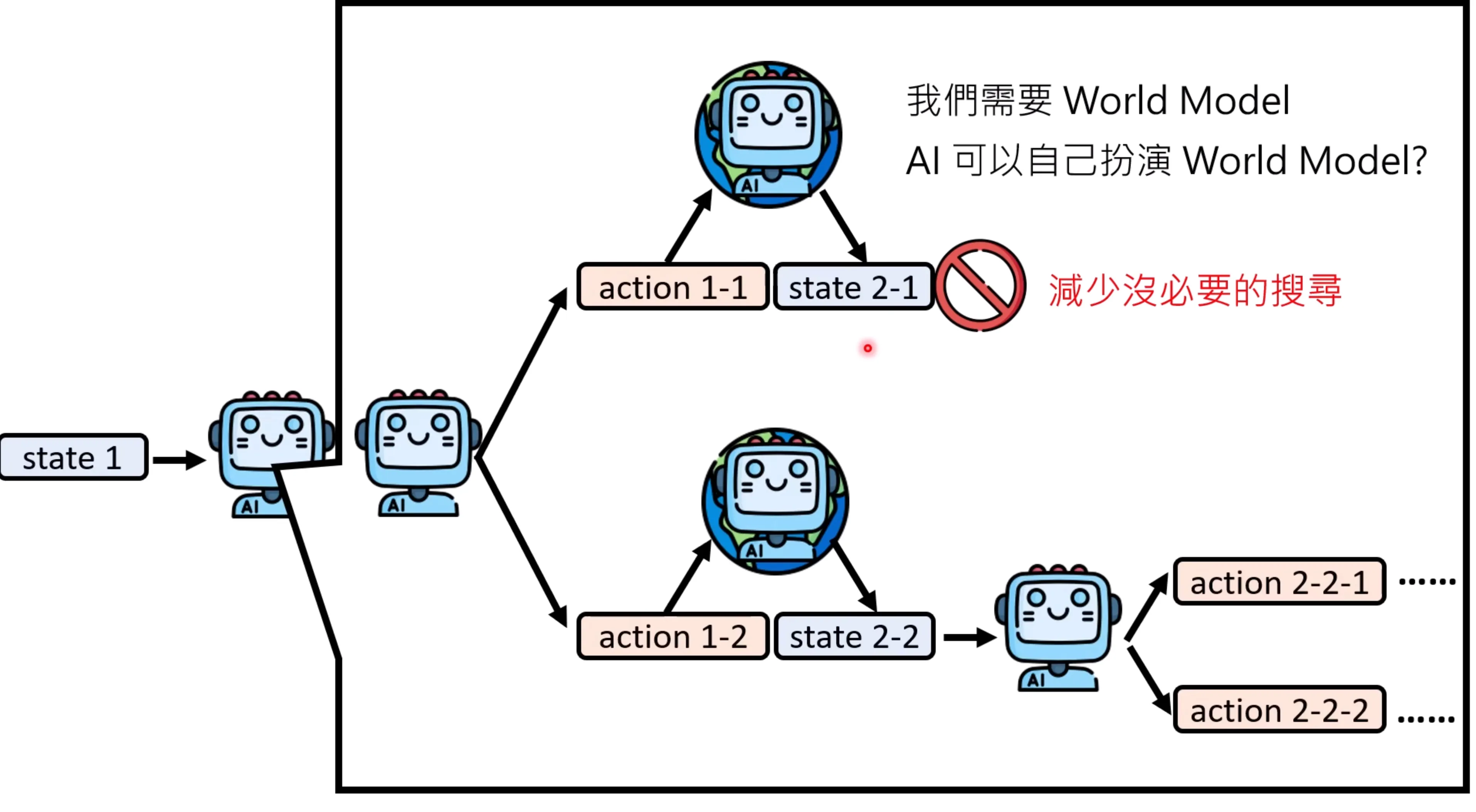
 为了减少可能的试错的可能,可以将这一系列执行的过程放在一个非真实环境下(simulation), 让模型自己去做推理,但是如何获取和环境的交互信息呢?这里就需要一个world model:
为了减少可能的试错的可能,可以将这一系列执行的过程放在一个非真实环境下(simulation), 让模型自己去做推理,但是如何获取和环境的交互信息呢?这里就需要一个world model:
思考(Reasoning)能力,如果一直在进行反思和思考会有一些问题,也要避免想太多,脑内小剧场。
大语言模型内部运作机制#
今天说的方法未必可以用在最新的大语言模型中当中,因为多数文献很多都是对于小型模型的分析。

一个神经元在做什么#
生成式AI做的事情,给定sequence 到预测下一个token,token可以是字可以是像素,也可以是语音采样。而实际的输出实际上是一个分布,表示下一个token,是任何一个token(字,像素等)的几率有多大。
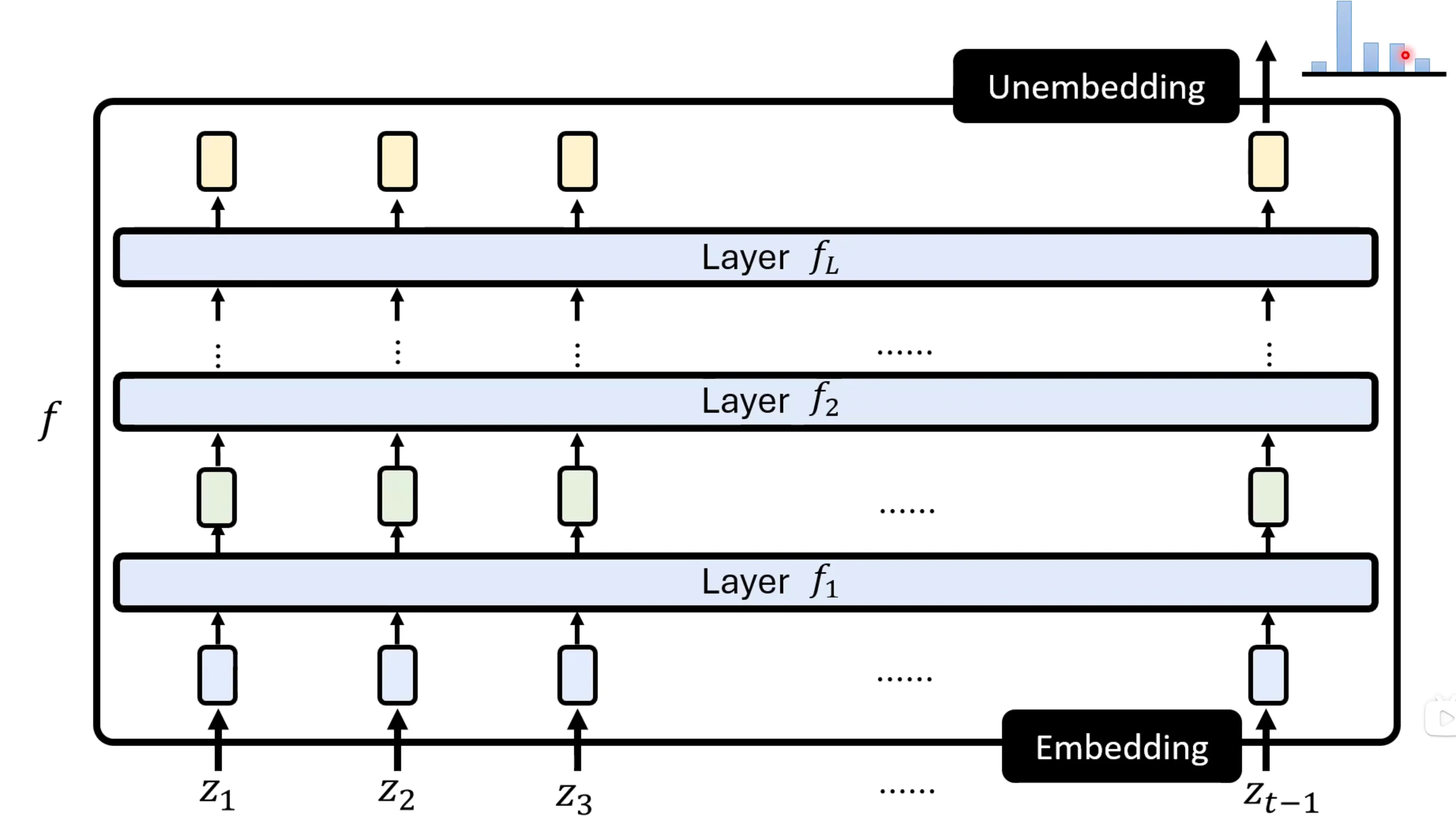
token是一个离散的变量,先要进行embedding变成向量,这个过程实际上是一个查表的过程,这个表也是通过学习,通过资料来得到的。紧接着通过一层一层的layer,得到新的vector sequence,最后得到最终的vector sequence。最后一层的最后一个向量会被用来产生distribution,从最后的向量变成分布的过程也称为unembedding,实际上也是通过一个线性的投影层将特征空间投影到类别空间
transformer中的每一个layer实际上是还包含其他的layer的。对于非self-attention的部分,这里是通过加权求和以及激活函数完成变换,蓝色的向量里面的每个值,也称为一个神经元的输出。
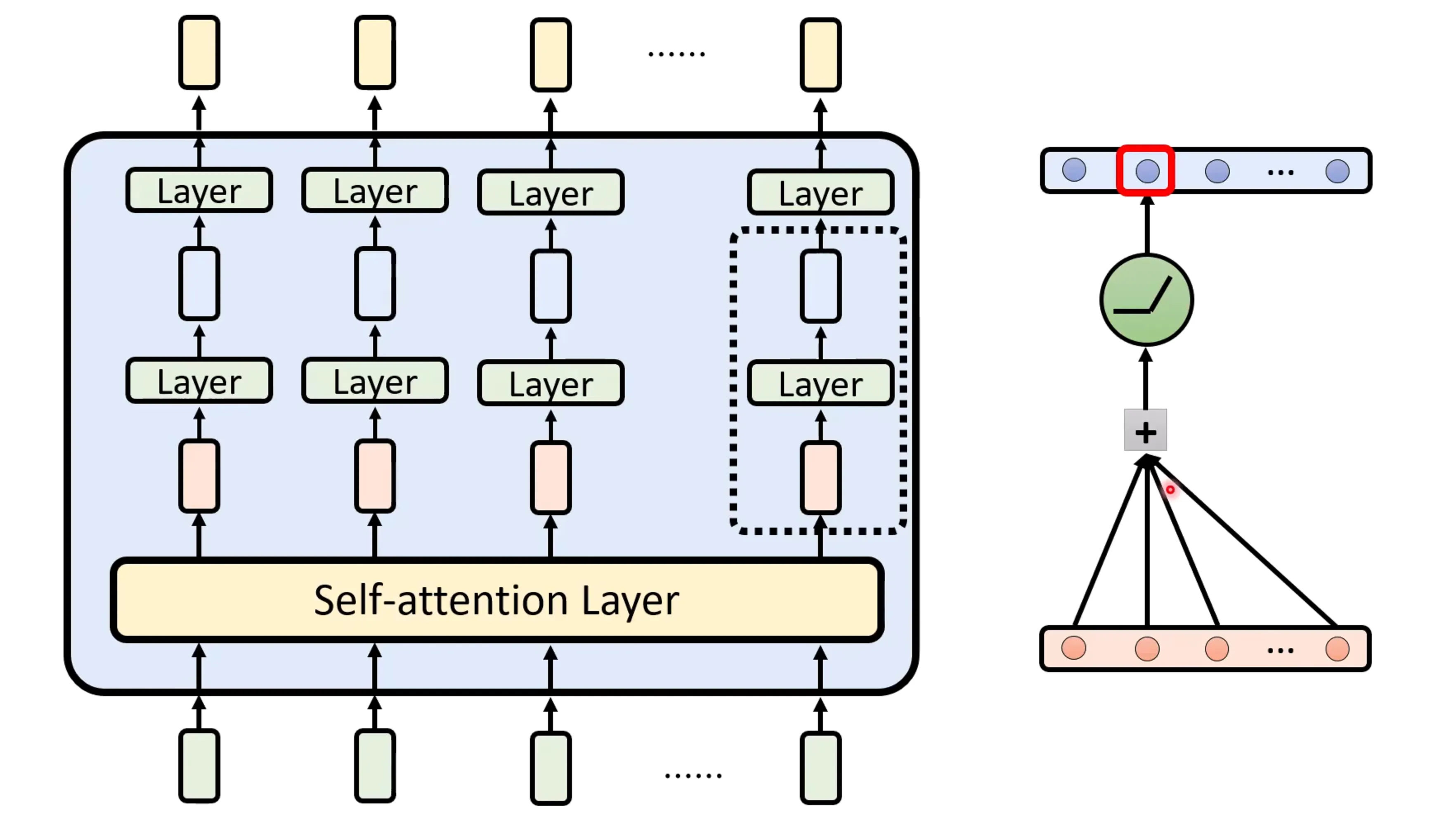 下面是检验神经元有什么用的方法,就是将某个神经元去除,从而判断神经元和输出是否有联系,但直接设置为0可能也会影响其他神经元的输出。
下面是检验神经元有什么用的方法,就是将某个神经元去除,从而判断神经元和输出是否有联系,但直接设置为0可能也会影响其他神经元的输出。
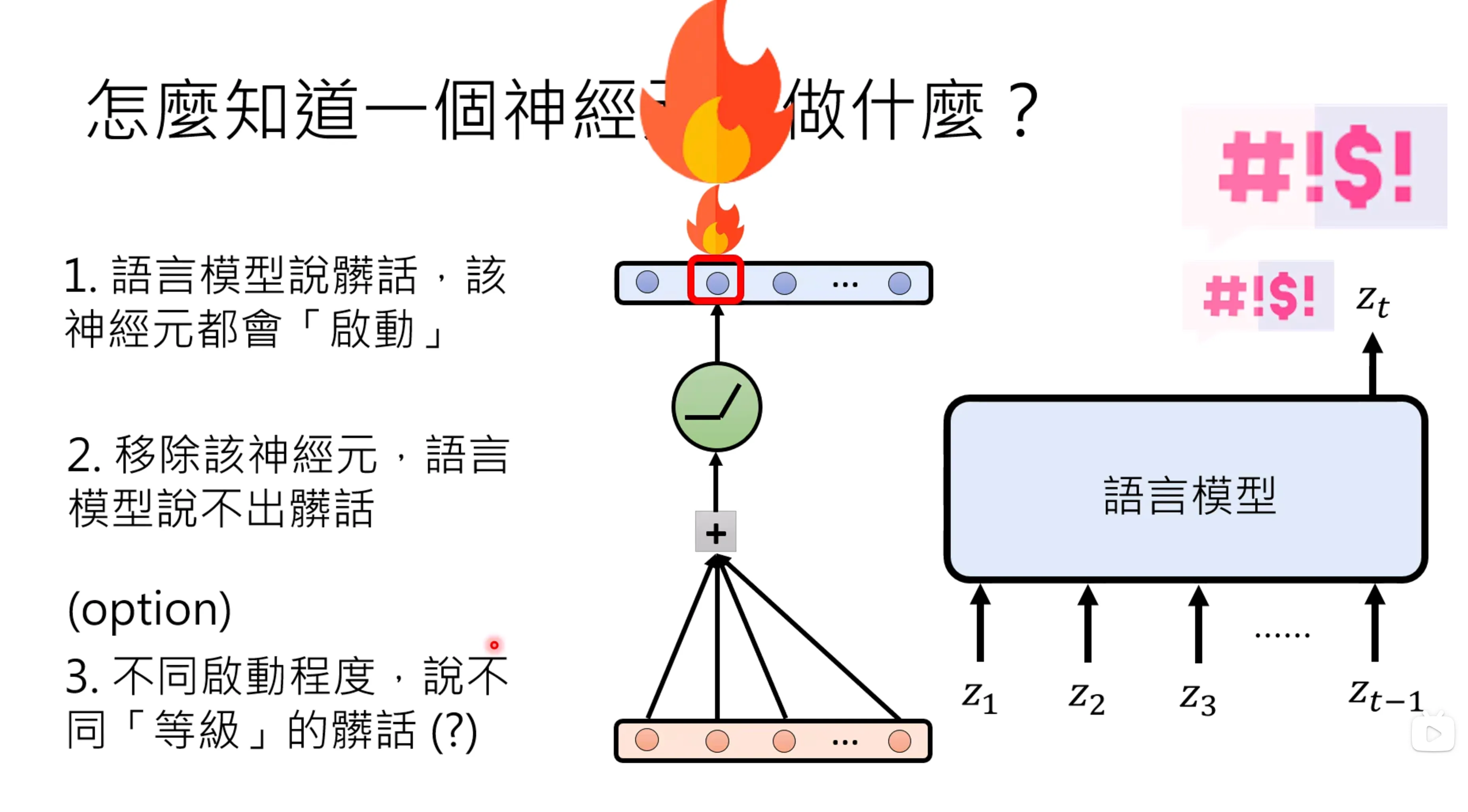 人脑中的某些神经元可能会负责单一的任务。 但对于单一神经元的功能却不容易解释,一件事情可能由多个神经元管理,一个神经元可能会同时管理很多事情。
人脑中的某些神经元可能会负责单一的任务。 但对于单一神经元的功能却不容易解释,一件事情可能由多个神经元管理,一个神经元可能会同时管理很多事情。
一层神经元在做什么#
一层类神经网络的输出通常称为representation。怎么样知道哪一层是代表拒绝功能的向量呢?这里实际上认为观察到的向量可以由拒绝向量+其他得到。只需要穷举很多拒绝的请求,就可以平均所有拒绝的情况,从而得到拒绝向量+其他平均向量的组合。在利用没有拒绝的情况,进行大量的平均可以得到其他的平均的情况。
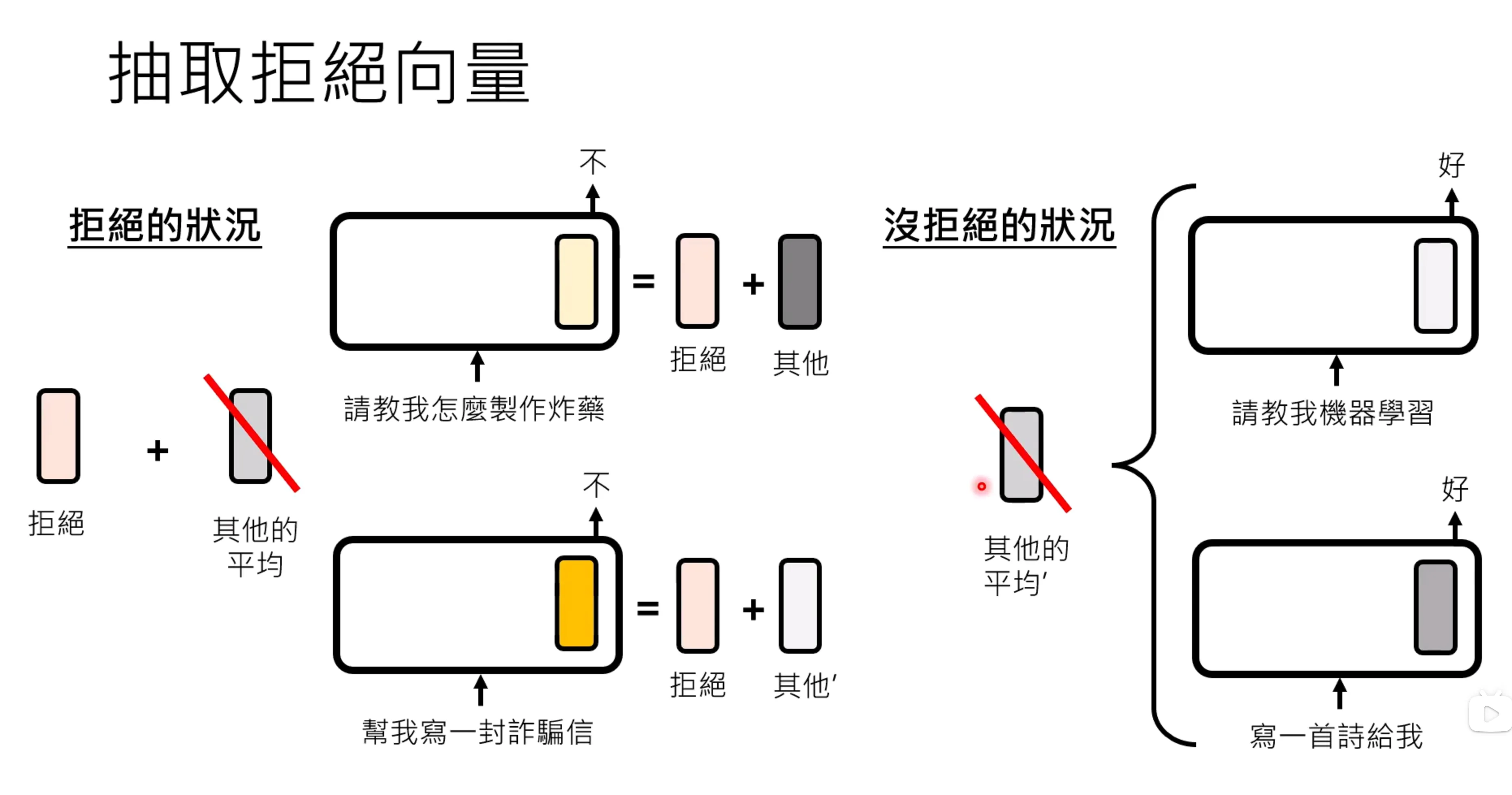 有文献中指出,加入拒绝的向量,又可能让一个正常的问题拒绝回答。找功能向量是一个研究领域和方向。对语言模型加上或者减去representation从而改变模型行为的问题,也被称为Representation Engineering,Activation Engineering,Activation Steering等等。大语言模型用In-context learning的能力,举例来说,可以通过例子来进行依样画葫芦。
有文献中指出,加入拒绝的向量,又可能让一个正常的问题拒绝回答。找功能向量是一个研究领域和方向。对语言模型加上或者减去representation从而改变模型行为的问题,也被称为Representation Engineering,Activation Engineering,Activation Steering等等。大语言模型用In-context learning的能力,举例来说,可以通过例子来进行依样画葫芦。
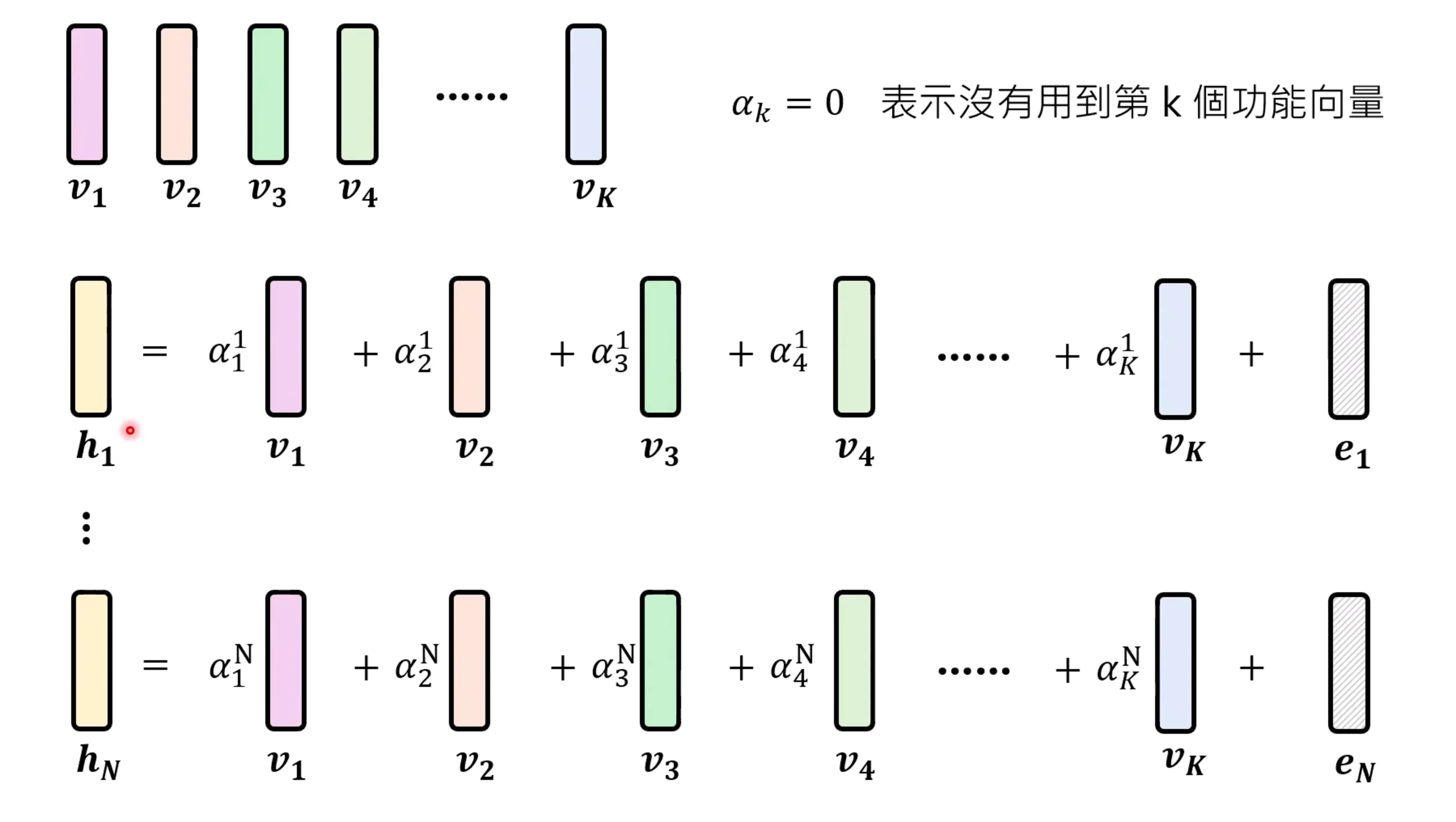
有文献发现功能向量是可以相互叠加的,但不是所有的case,而是某几个case可以。能否将某一层的所有功能向量都找出来呢? 这里需要一个假设,即当前的向量是由这些基向量甲醛而来的。
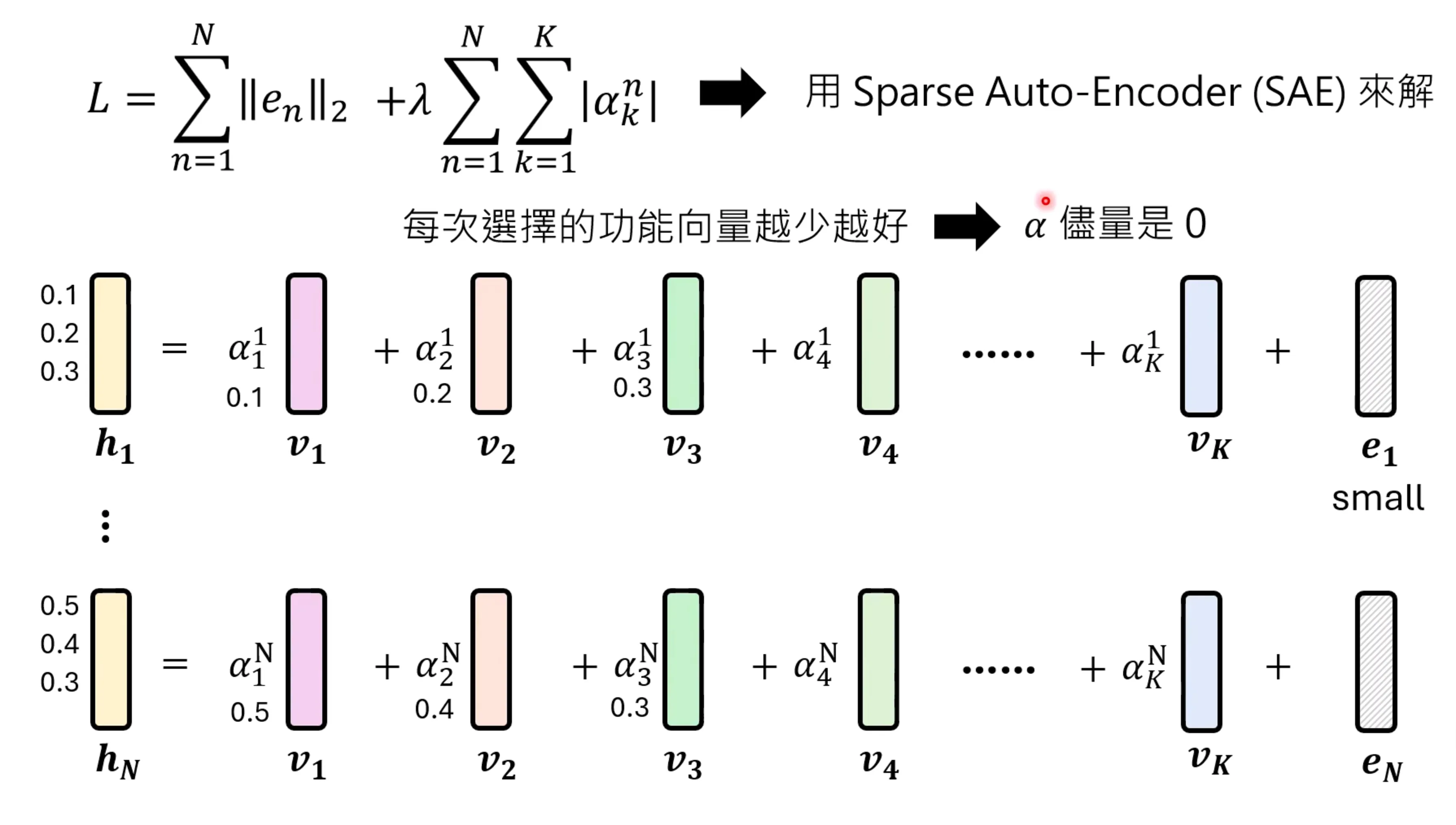
 为了要得到这些表征向量,则需要引入一些假设,首先最后的误差项要足够的小。其次选择的功能向量要越少越好,引入L1稀疏表达。解这个问题实际上和训练一个sparse auto-encoder是等价的。
为了要得到这些表征向量,则需要引入一些假设,首先最后的误差项要足够的小。其次选择的功能向量要越少越好,引入L1稀疏表达。解这个问题实际上和训练一个sparse auto-encoder是等价的。
一群神经元在做什么?#
语言模型可以理解成是人类语言系统的一个抽象,也研究人员研究语言模型的模型,企图将语言模型进一步抽象。
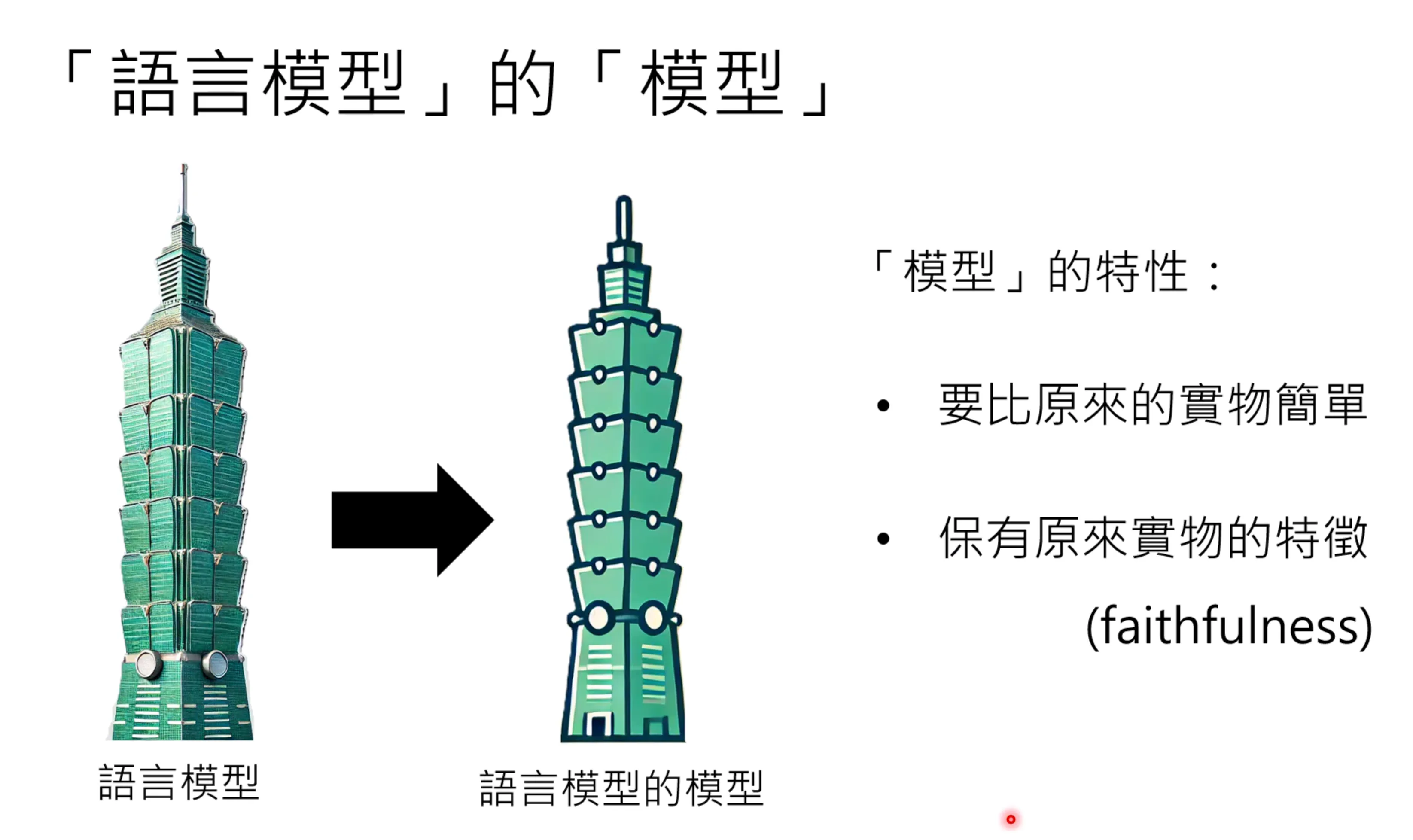 有文献认为主词通过编码可以得到一个feature,而后面的副词,可以作为一个线性层,而这个线性层描述了一个映射的关系,因此可以知道对于一个新的问题的答案是什么。当副词不变的时候,可以根据主词的变化得到后序的值。这实际上是对语言模型的一种简化,也就是语言模型的模型。但这个线性层表达可能是不够的。
有文献认为主词通过编码可以得到一个feature,而后面的副词,可以作为一个线性层,而这个线性层描述了一个映射的关系,因此可以知道对于一个新的问题的答案是什么。当副词不变的时候,可以根据主词的变化得到后序的值。这实际上是对语言模型的一种简化,也就是语言模型的模型。但这个线性层表达可能是不够的。
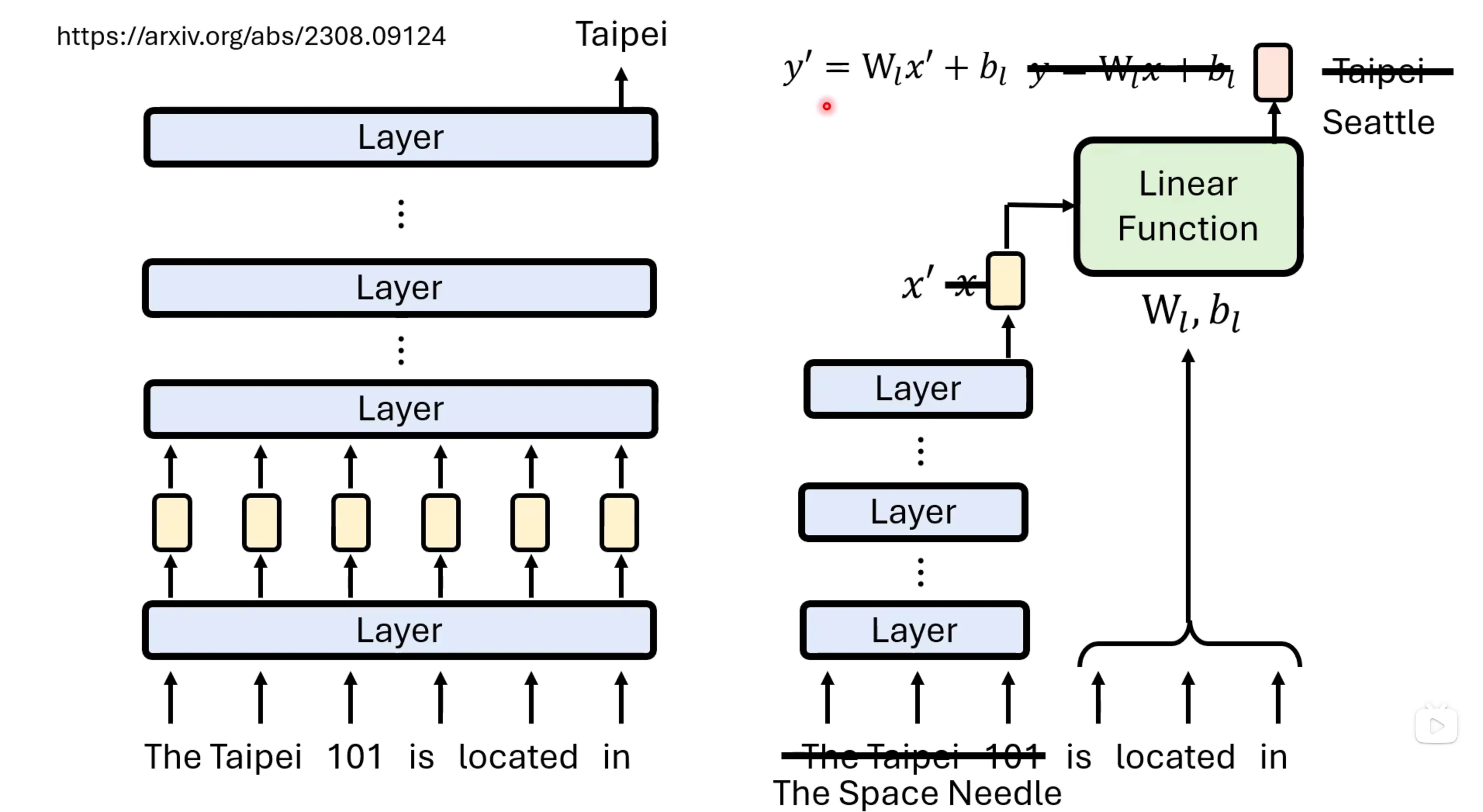
另一种可能的潜在应用是语言模型的修改,对于大模型来说修改其输出是一个相对困难的事,而通过模型的模型,可以得到线性层输出的feature,通过将得到的差异feature应用到大模型上,也许可以得到类似的效果。事实上确实这种观测是有一些用的
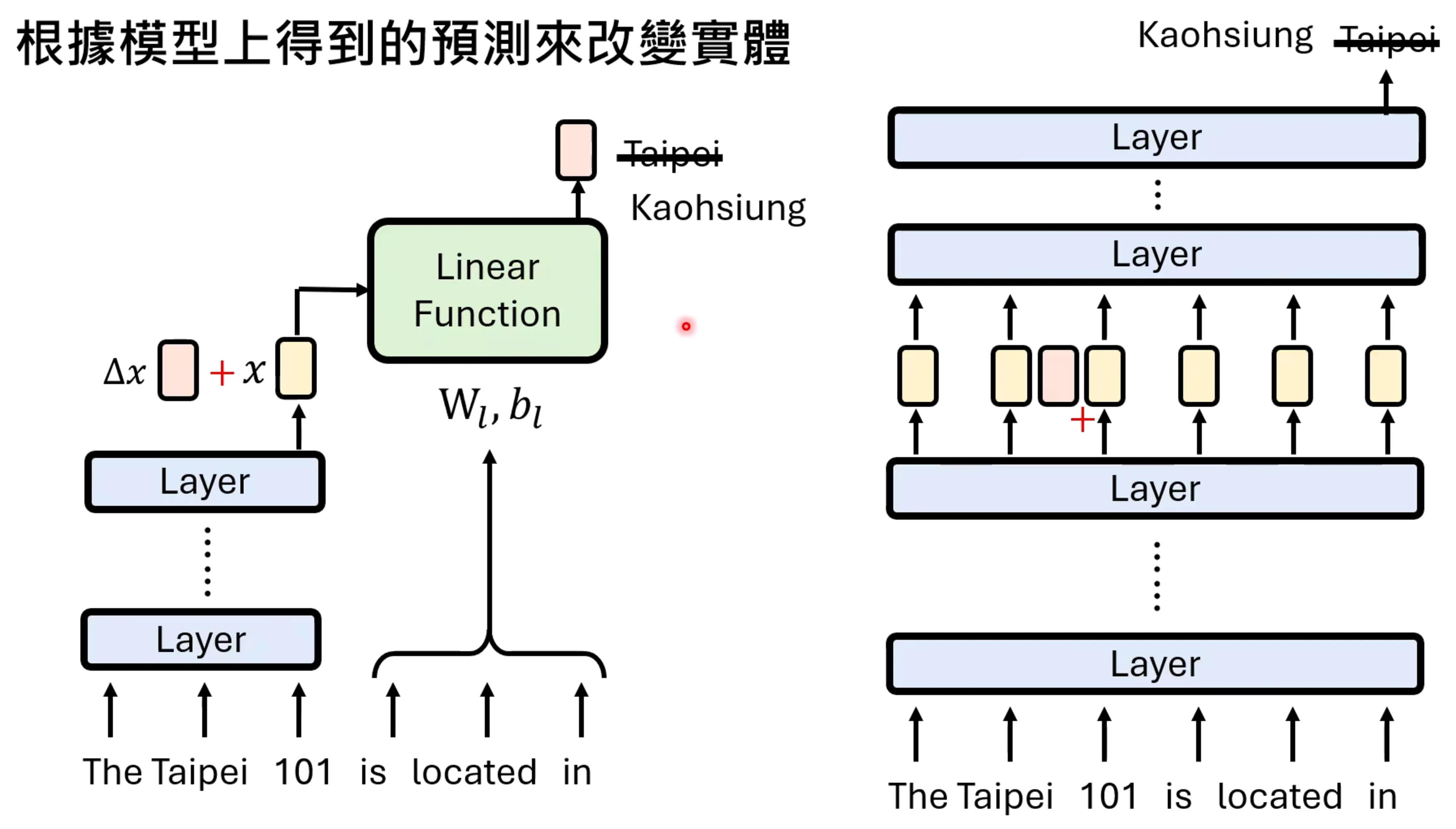 语言模型的模型也称为circuit,做pruning即可,但是和network compression还有些不一样,语言模型是在专有任务上的逼近,而网络压缩是对所有任务的一个逼近。
语言模型的模型也称为circuit,做pruning即可,但是和network compression还有些不一样,语言模型是在专有任务上的逼近,而网络压缩是对所有任务的一个逼近。
语言模型的运作#
另一种对于残差模型的理解,一种是左侧,认为token经过layer的变换后,在加上原来的信息,还有一种理解是实际上一直存在一个residual stream,相当于在每一步都在将信息加入到residual stream中,这种可以将中间的信息也通过softmax进行概率的输出,这个也叫做logit lens
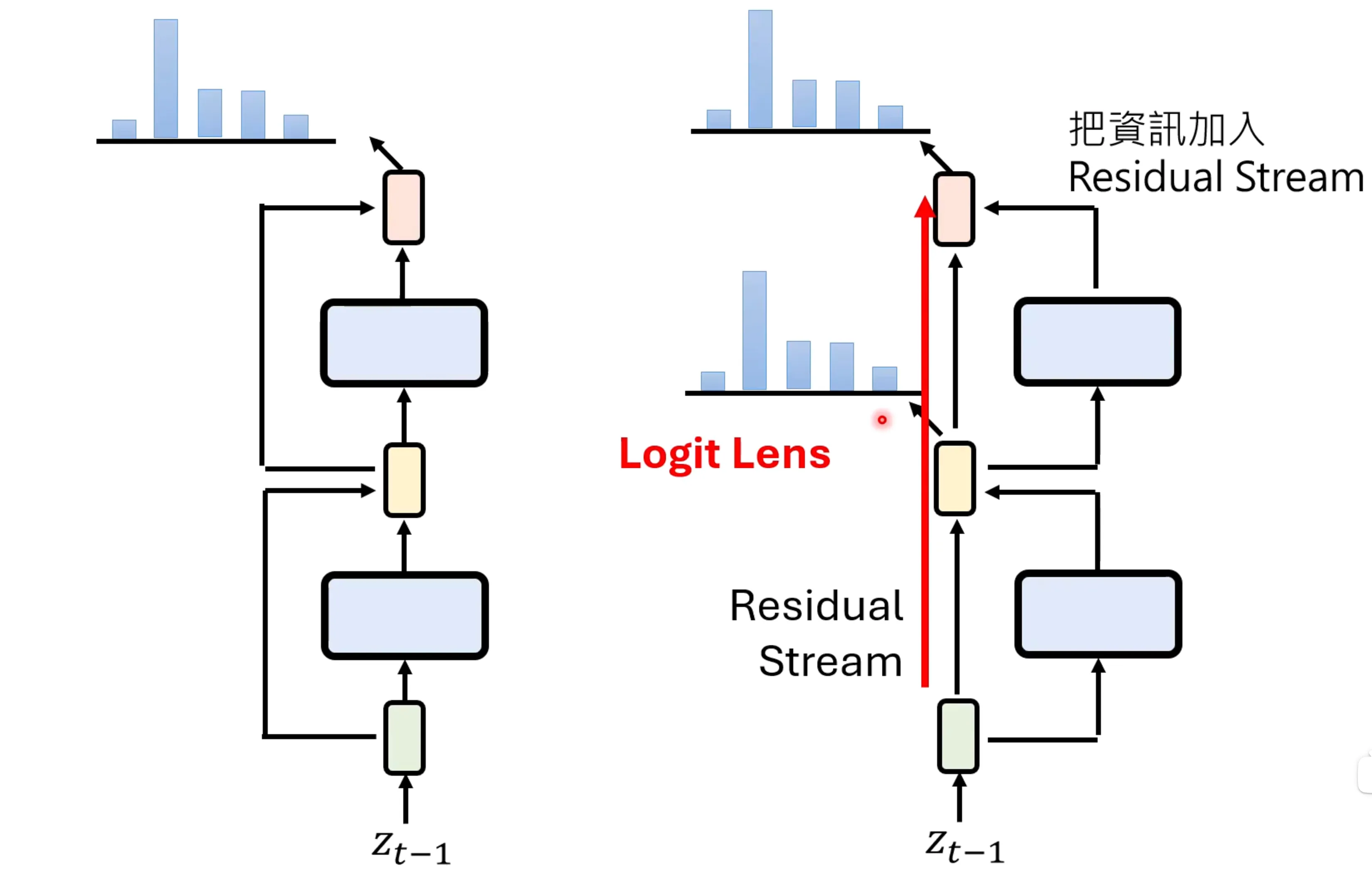 通过这种logit len的方法可以得到语言模型每一层的一个输出,从而发现语言模型的变化过程,这也让思维变得逐渐透明。
通过这种logit len的方法可以得到语言模型每一层的一个输出,从而发现语言模型的变化过程,这也让思维变得逐渐透明。
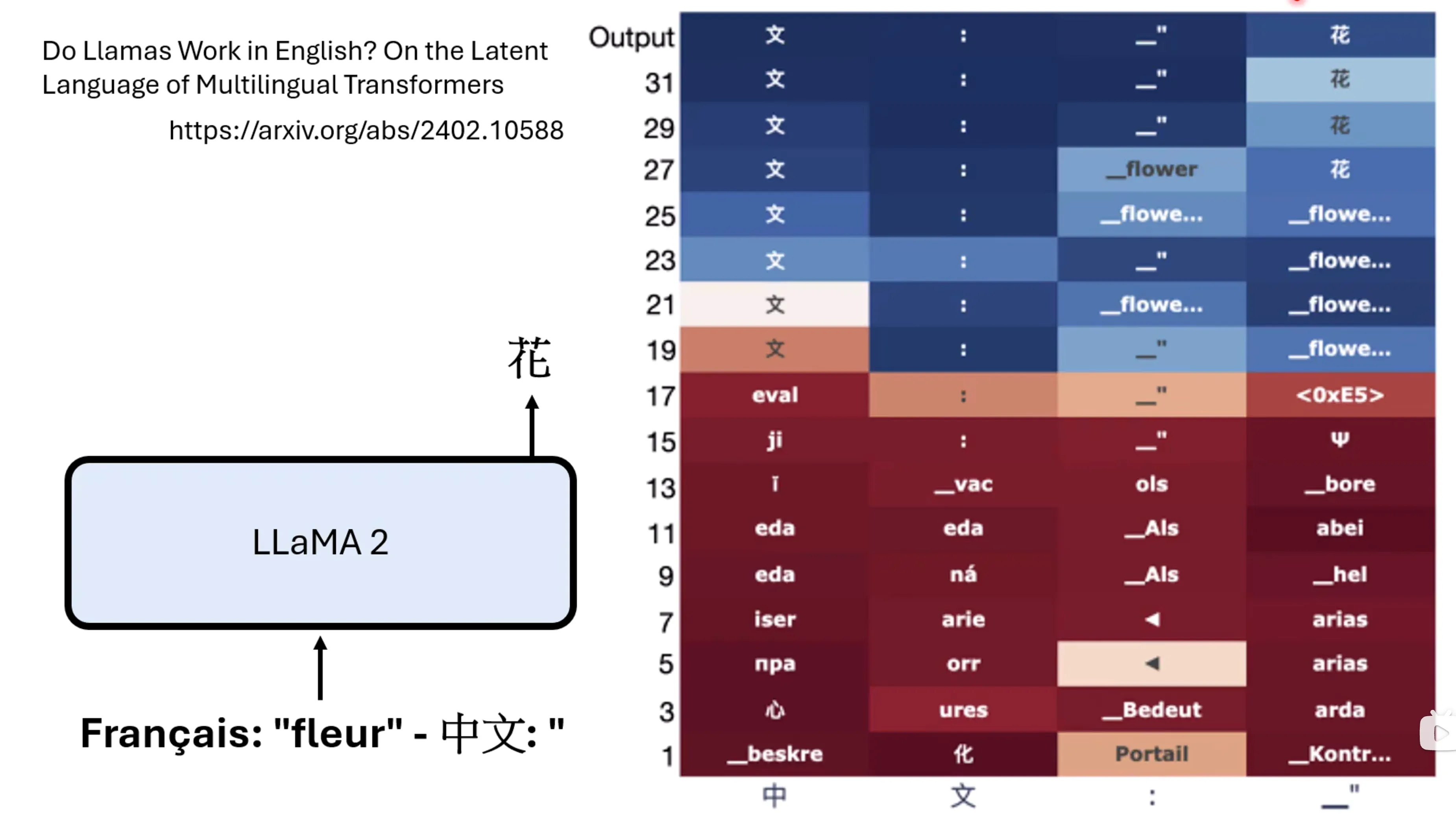 有人分析了LLaMA2的文本回答过程,当中字输入的时候,在最后会推断出文这个字,当文作为补充输入的时候,会推断出:,当_输入的时候最后会输出花,而实际上这个过程是先得到英文的结果,在将其转为中文的结果,比较有趣。
有人分析了LLaMA2的文本回答过程,当中字输入的时候,在最后会推断出文这个字,当文作为补充输入的时候,会推断出:,当_输入的时候最后会输出花,而实际上这个过程是先得到英文的结果,在将其转为中文的结果,比较有趣。
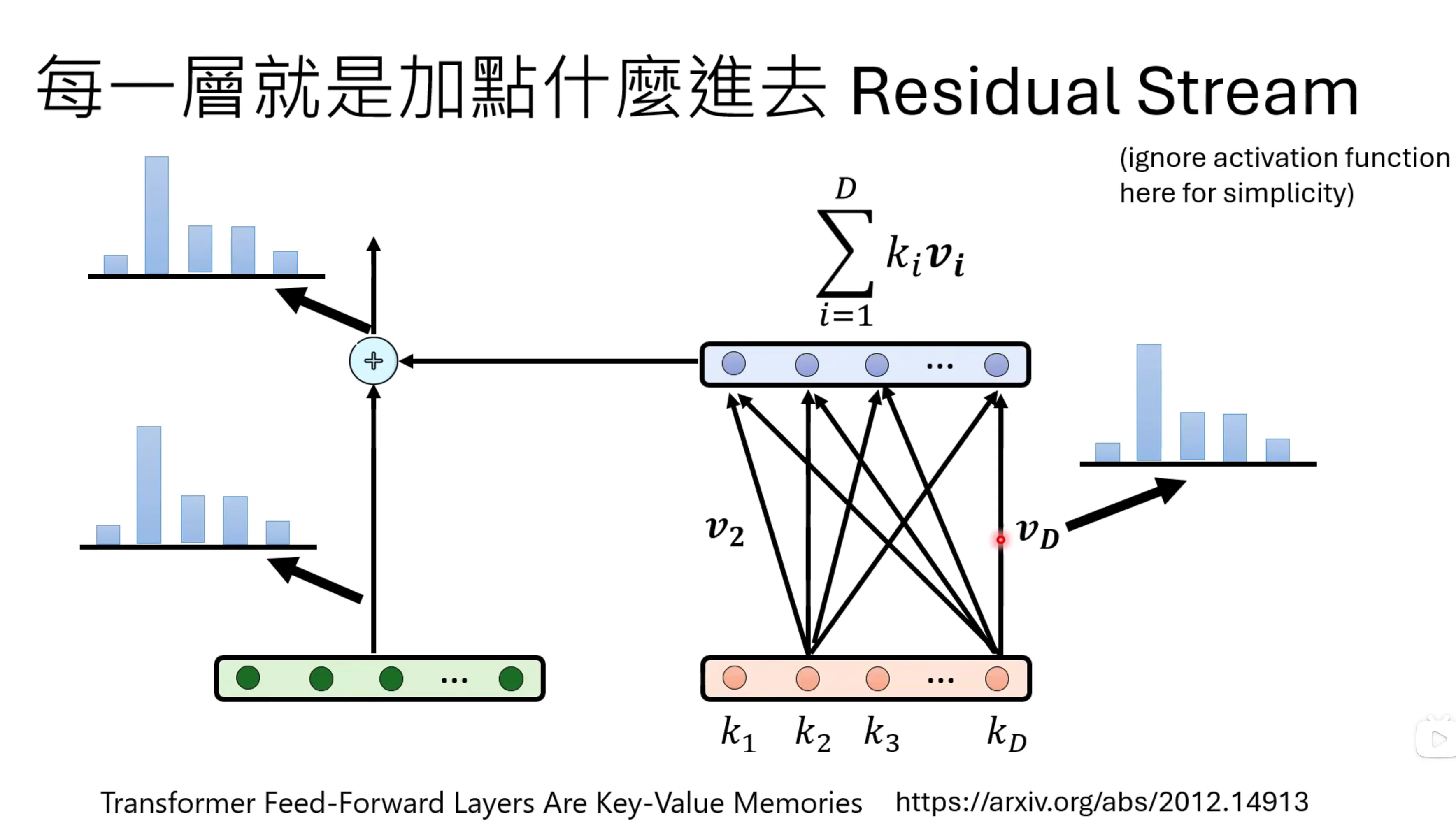
Feed Foward的network可以看成是一个有key和value的transformer,weight是transformer的attention weight,最后的输出是weight加权的value。通过这种方式可以对每个合成的基进行解码,从而知道每个神经元向量在传递过程中的含义。
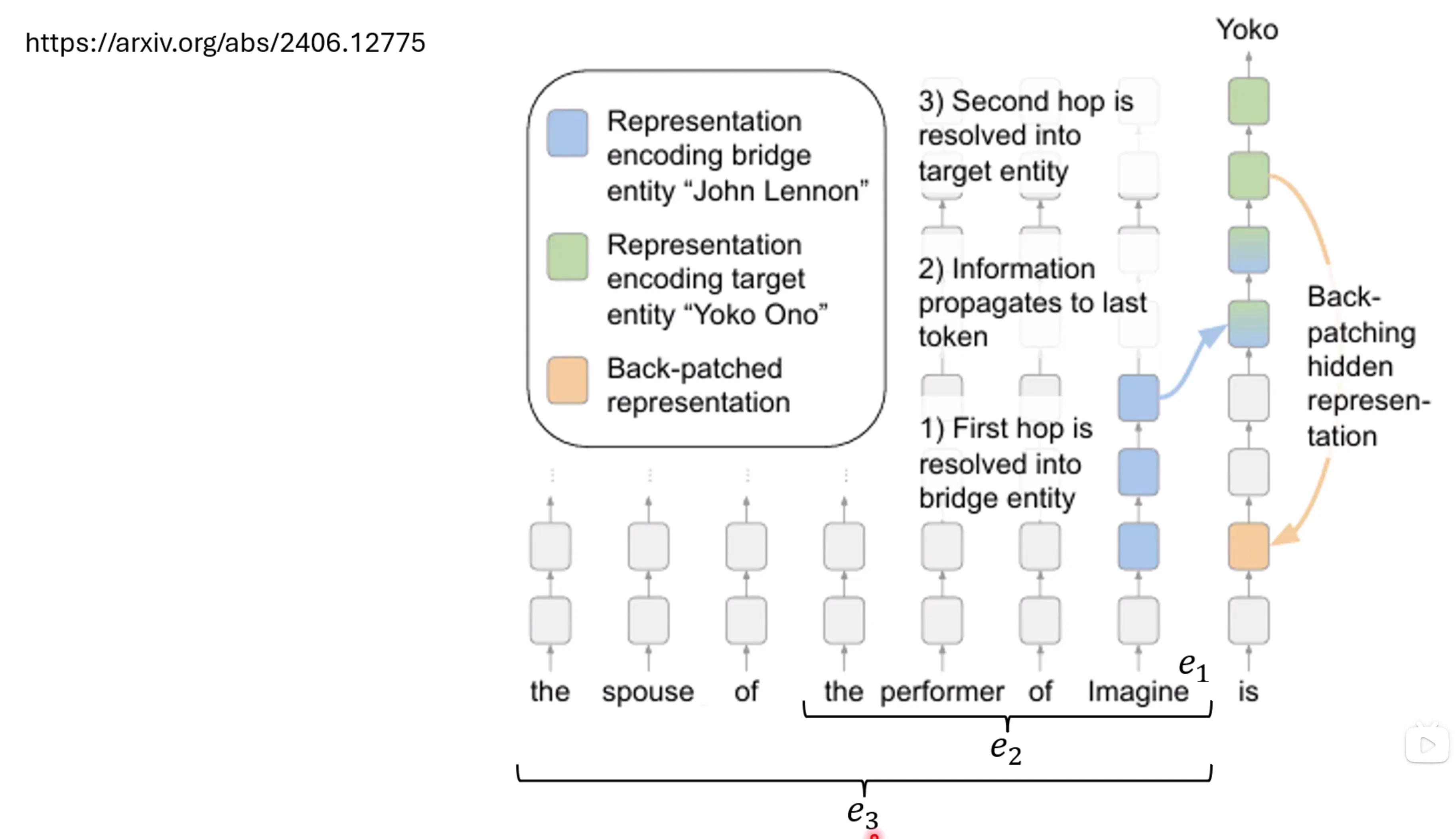
实际上这里有个比较有意思的事情,就是发现思维过程,作者认为信息是一点一点被解析和锁定的,即前面的部分的思考会影响后面的生成,因此作者认为如果有些思考过程或者先验信息出来的过晚,可能会导致没办法得到正确的解析结果,因此作者将一些后期的思考加入前期的输入中,发现确实能提高之前不对的信息的回答的正确率。
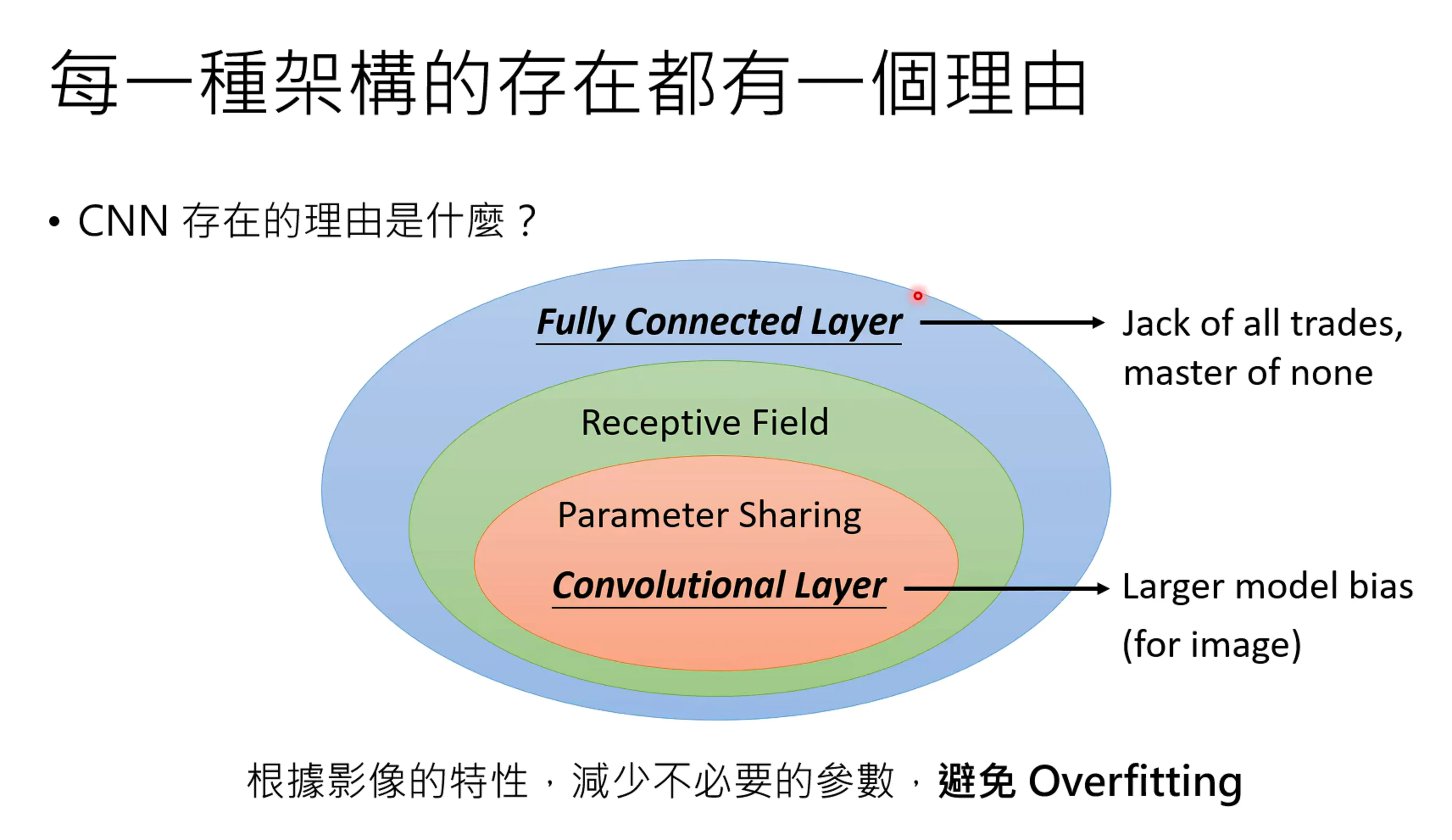
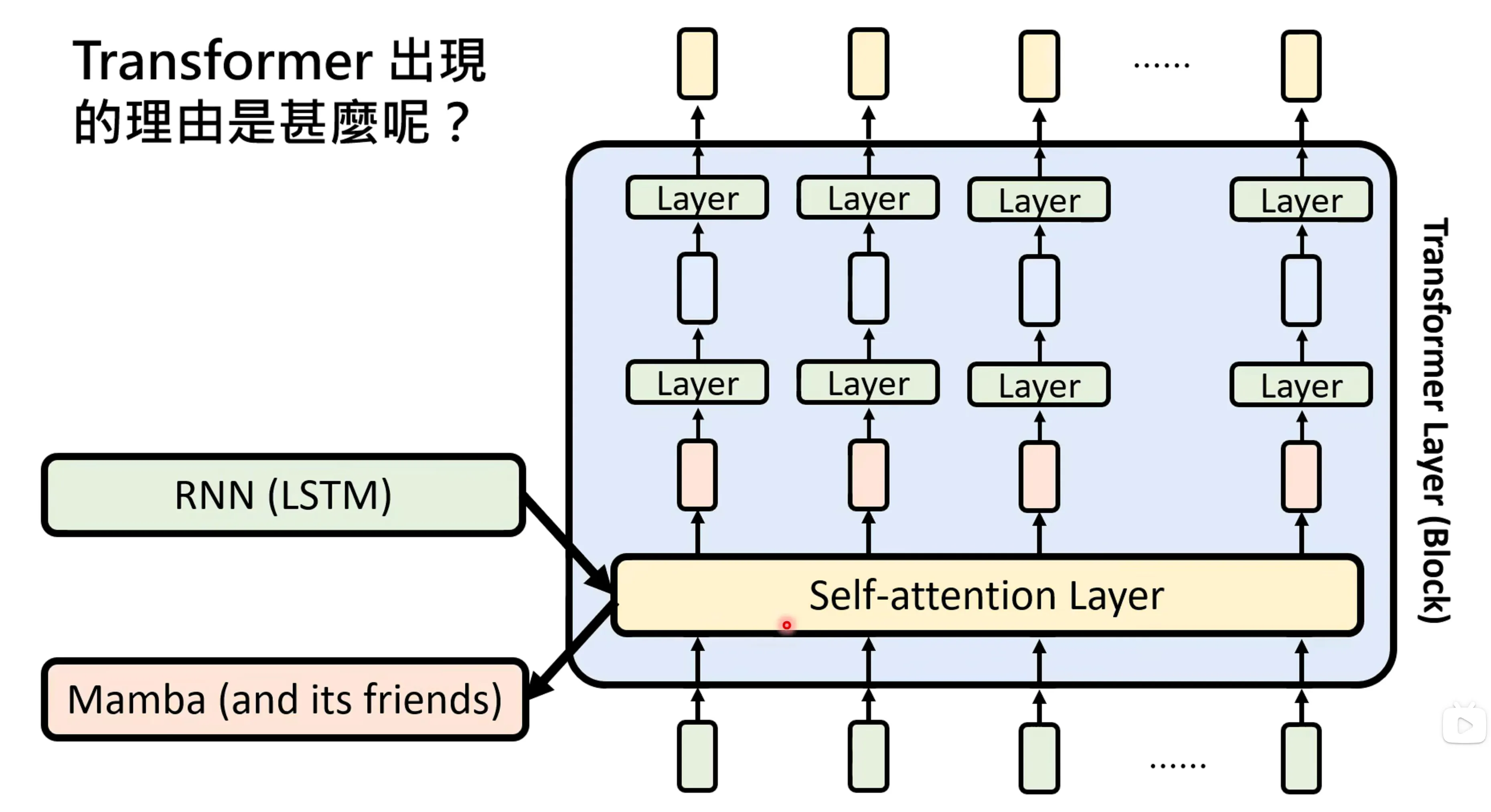
Transformer的竞争者们#
每一个架构都有一个存在的理由,将fully connected feedforward network进行范围的缩小,加入一些约束可以变成convolutional network
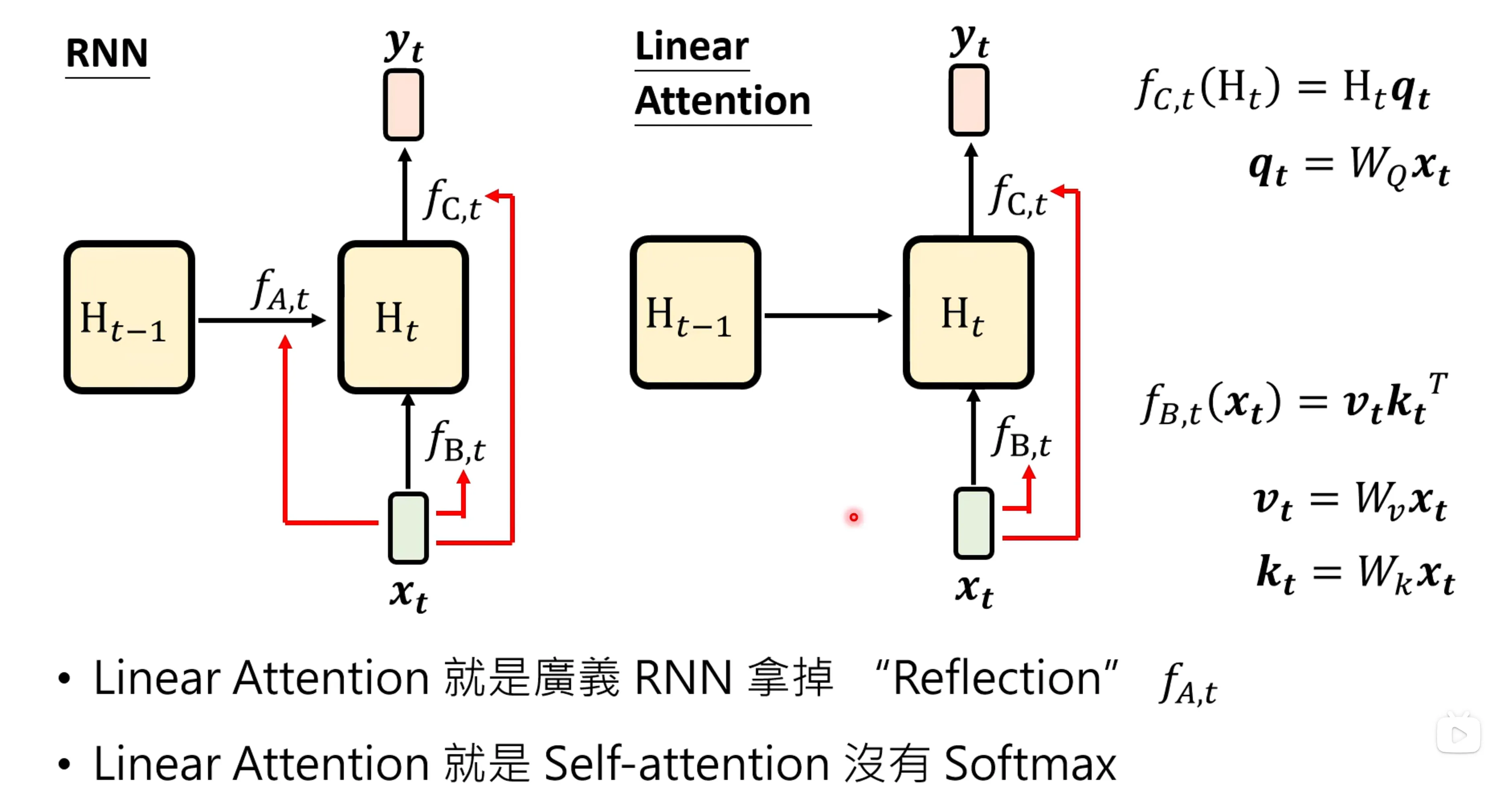
self-attention是在2019年在机器学习这门课引入,Mamba就是RNN,输入一个vector sequence,通过一个模型结构输出另一个加权的vector sequence是所有架构的一个目的。
RNN#
首先先看RNN是如何解决这个问题的:RNN是有一个hidden state的,将目前所有看到的输入混合起来,放入hidden state中,输出仅需要hidden state即可决定输出。RNN的hiden state不一定是向量,他也可以是一个很大的矩阵。
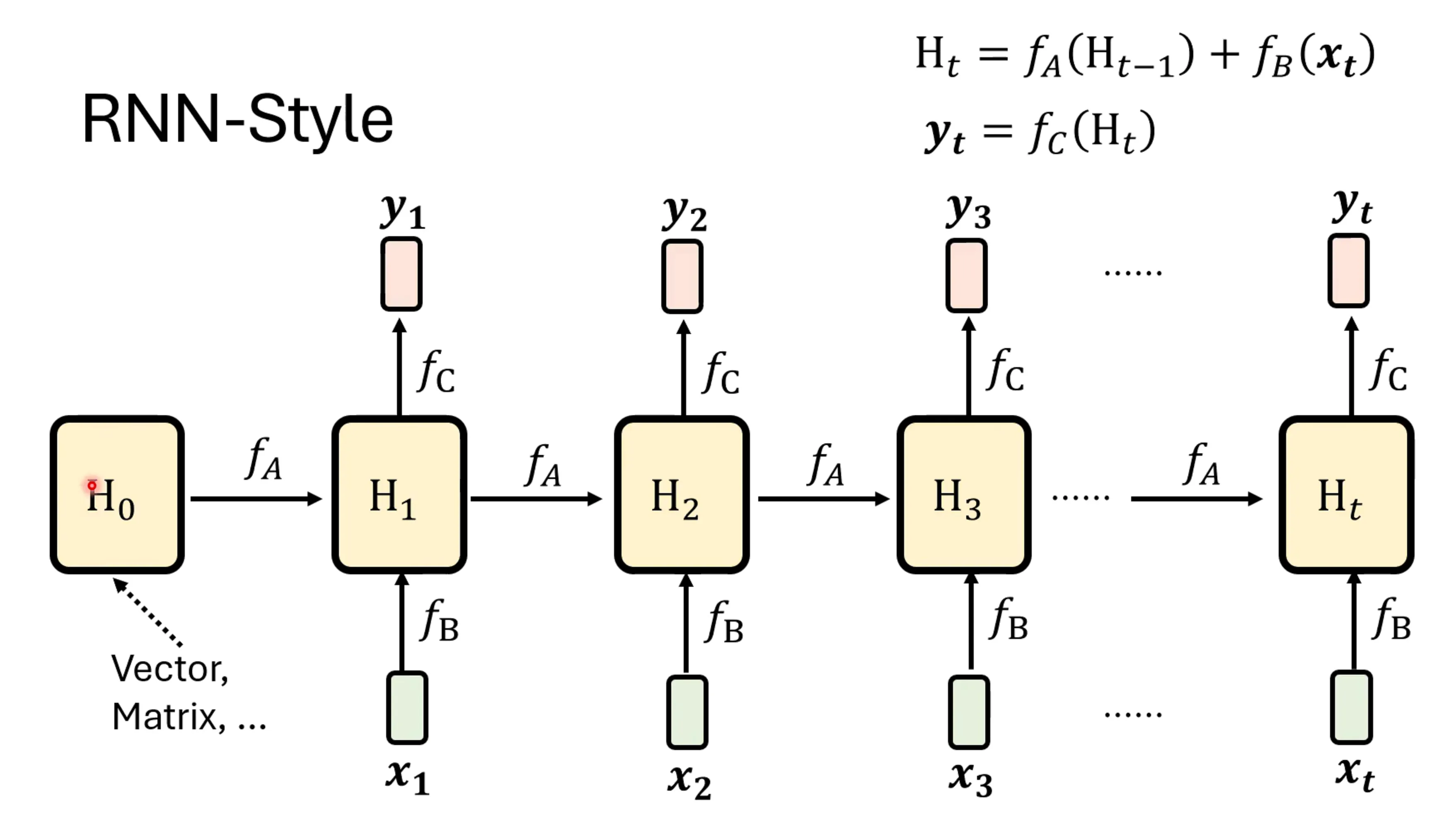 更一般的写法,让这个f映射和时间相关,则RNN可以重新写为:为了让f和时间有关,可以写成是的函数,让f和输入有关,其实这个就是LSTM。
更一般的写法,让这个f映射和时间相关,则RNN可以重新写为:为了让f和时间有关,可以写成是的函数,让f和输入有关,其实这个就是LSTM。
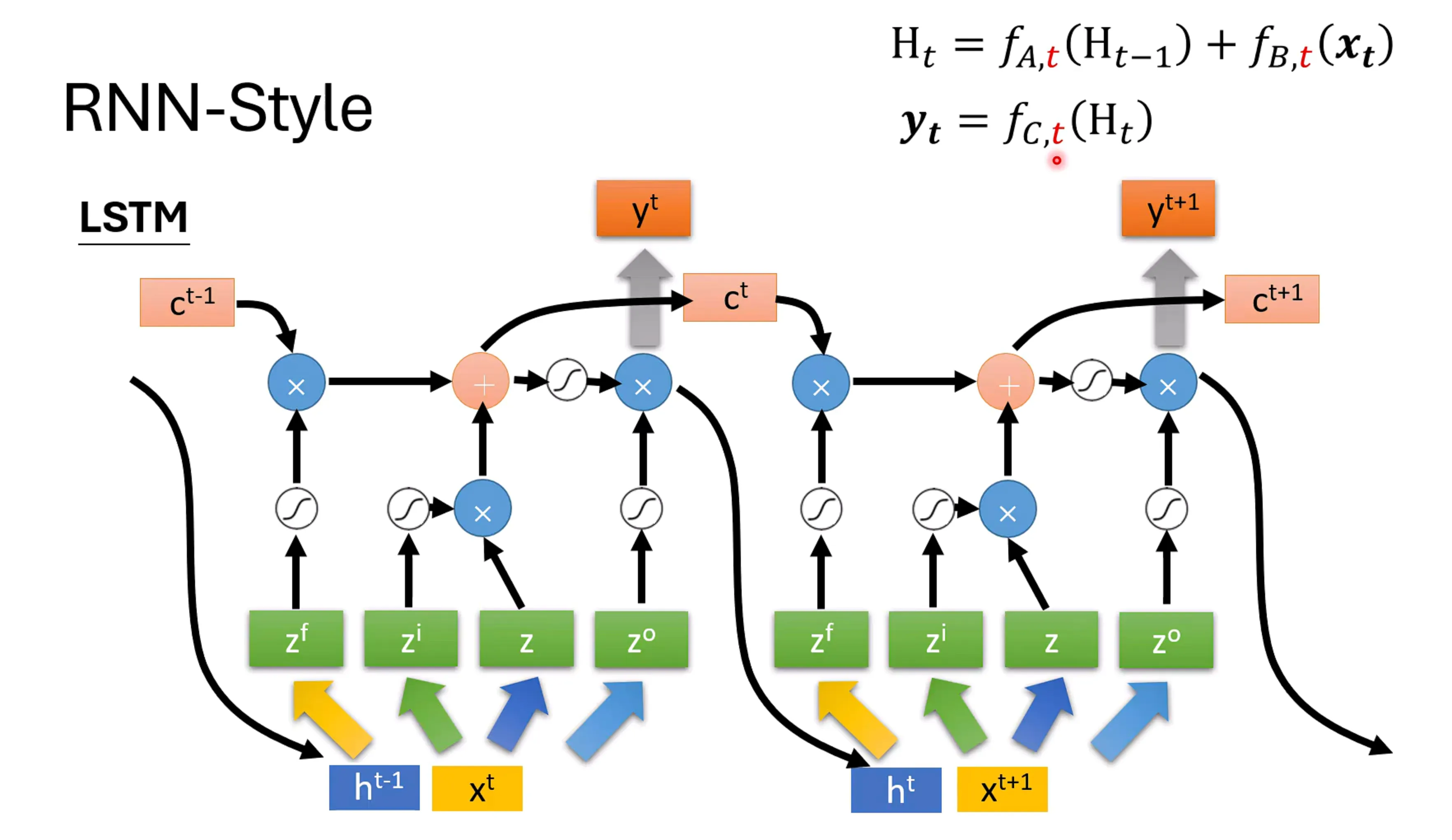
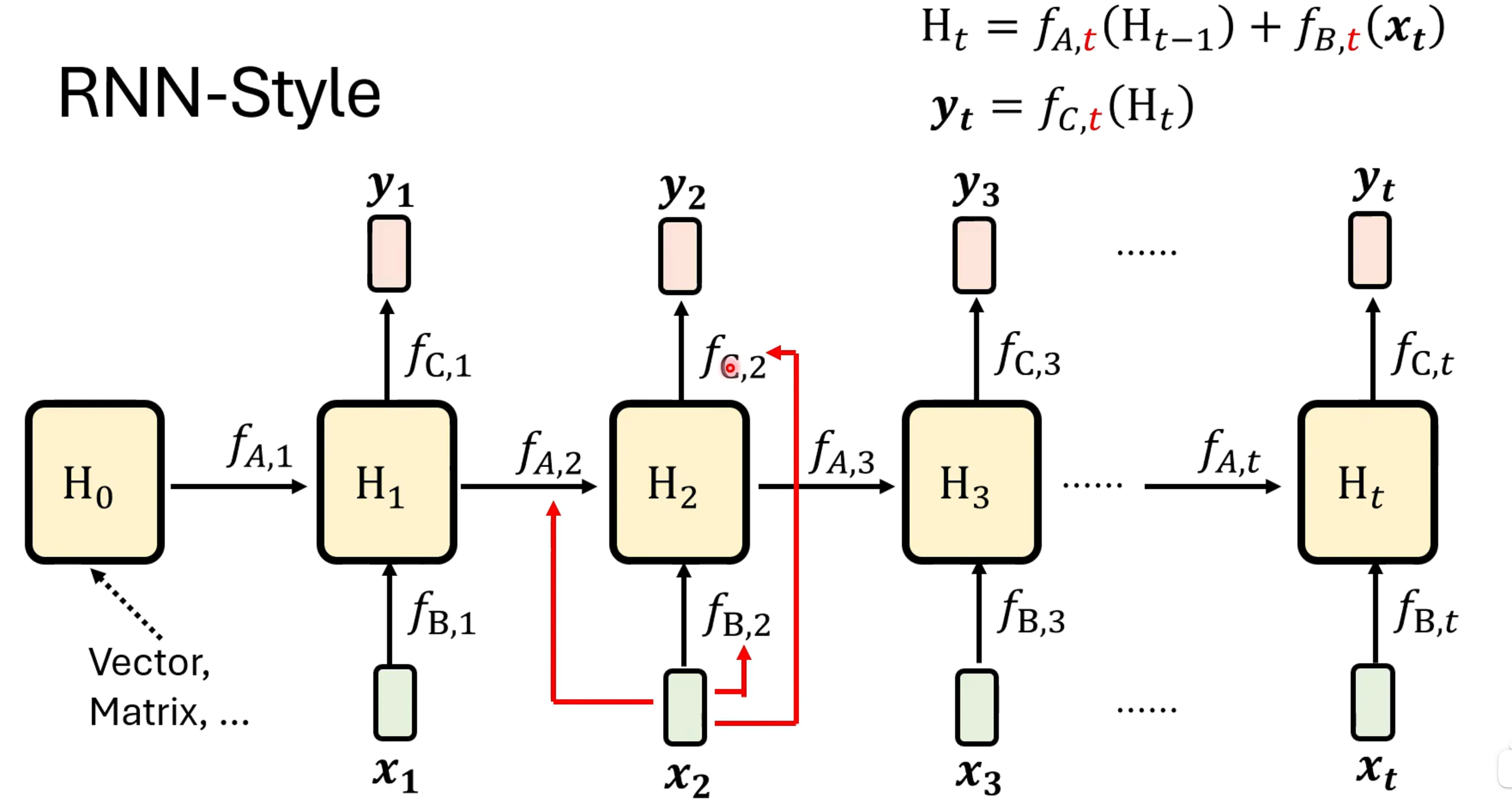 这些有Gate的RNN其实就是让其和时间有关,这个t就是gate,对于LSTM有三个Gate,一个是input gate对应,一个是forget gate,对应,另一个是output gate对应
这些有Gate的RNN其实就是让其和时间有关,这个t就是gate,对于LSTM有三个Gate,一个是input gate对应,一个是forget gate,对应,另一个是output gate对应
而这个流程实际上好AI agent的大模型的流程是像的,H就是一个memory,而H的转移和变换的过程就可以对应Reflection,而输入要不要放入记忆中,实际上就是对应写入的过程,而输出对应的也是一个读取的过程,很有趣。
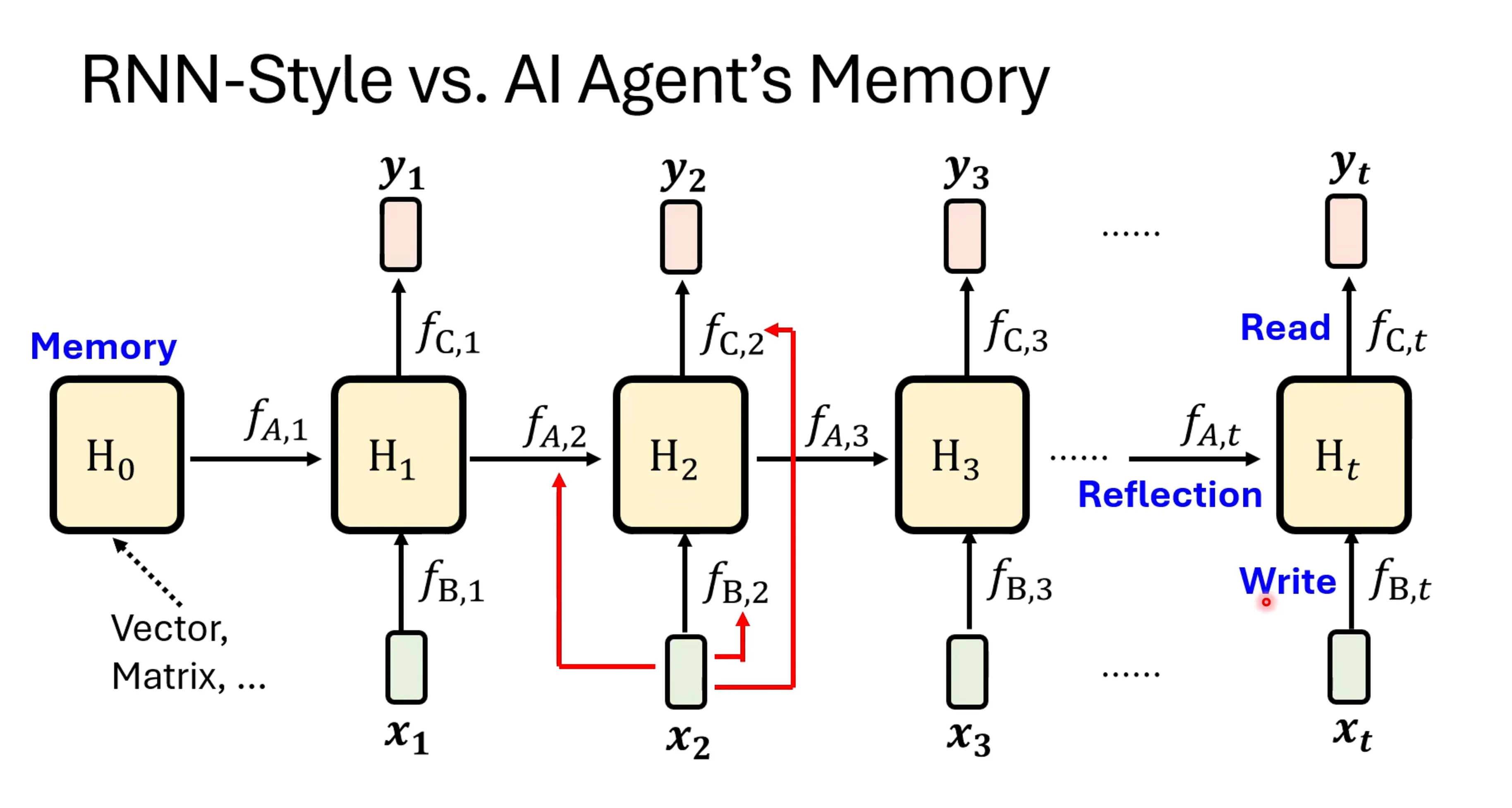
如果将RNN作为一个训练好的语言模型,进行inference,是将RNN替换transformer中的self-attention,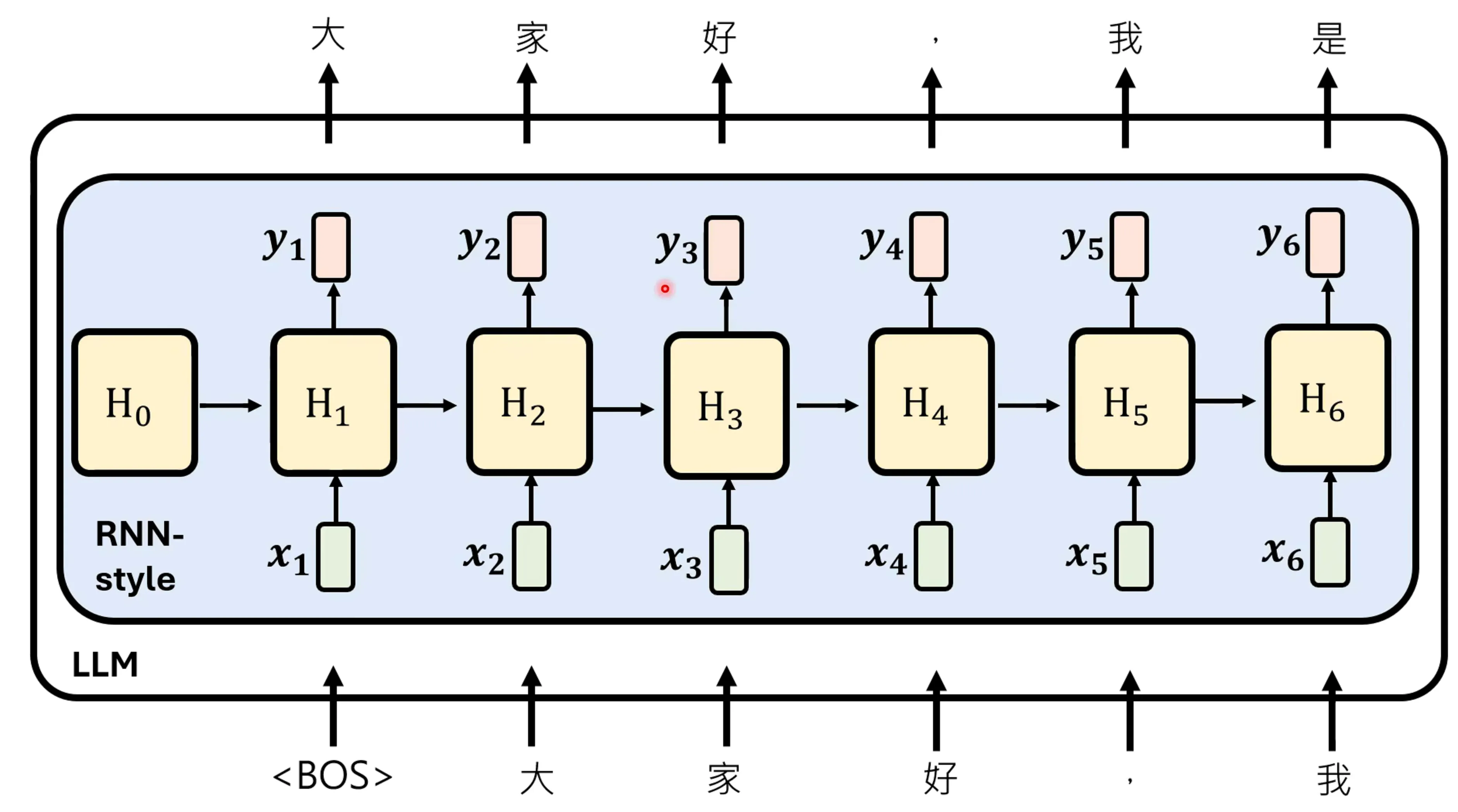
self-attention#
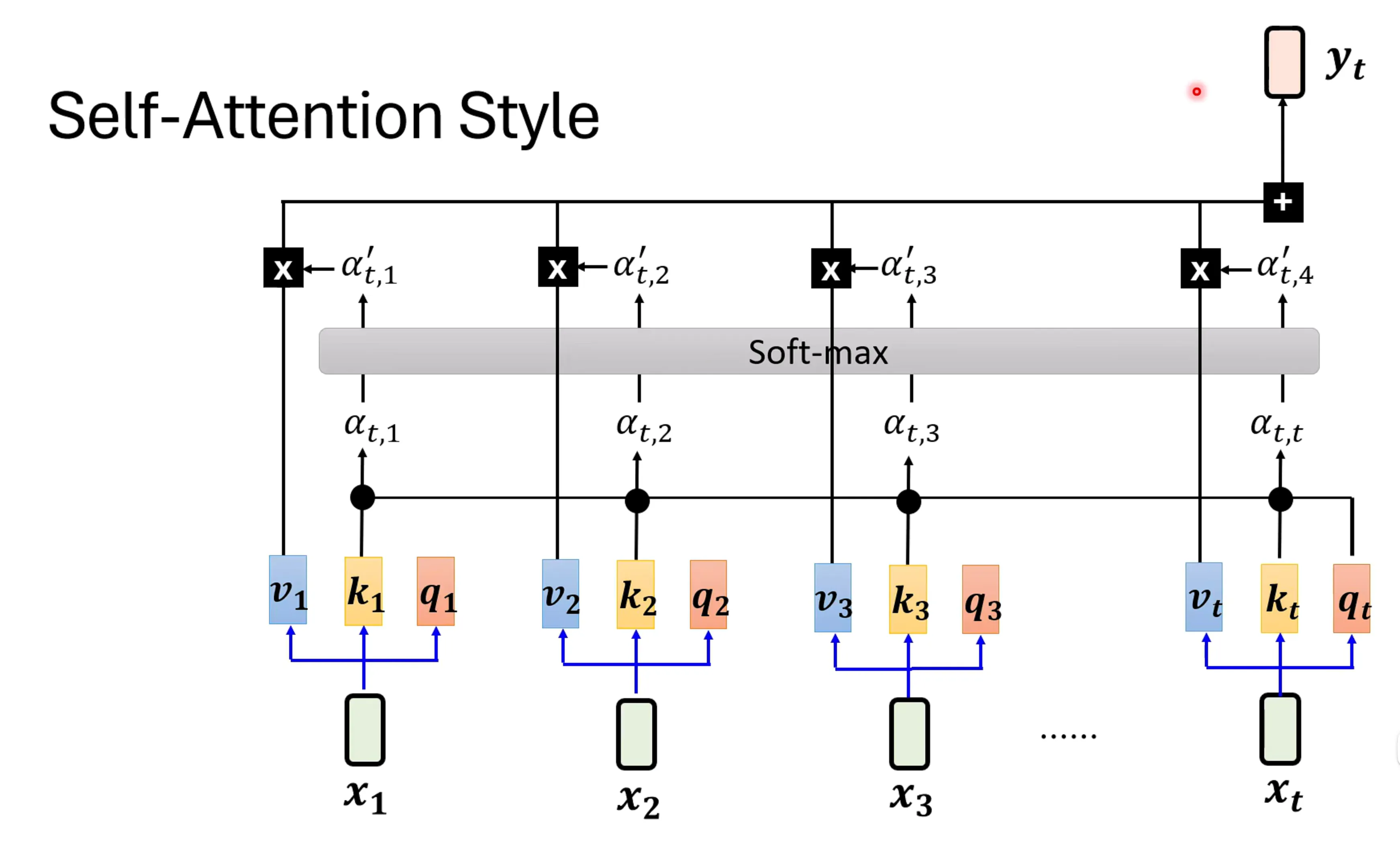
self-attention完成输入的方式是如下图所示,实际上attention的概念很早就有了,并不是在transformer中首次提出。
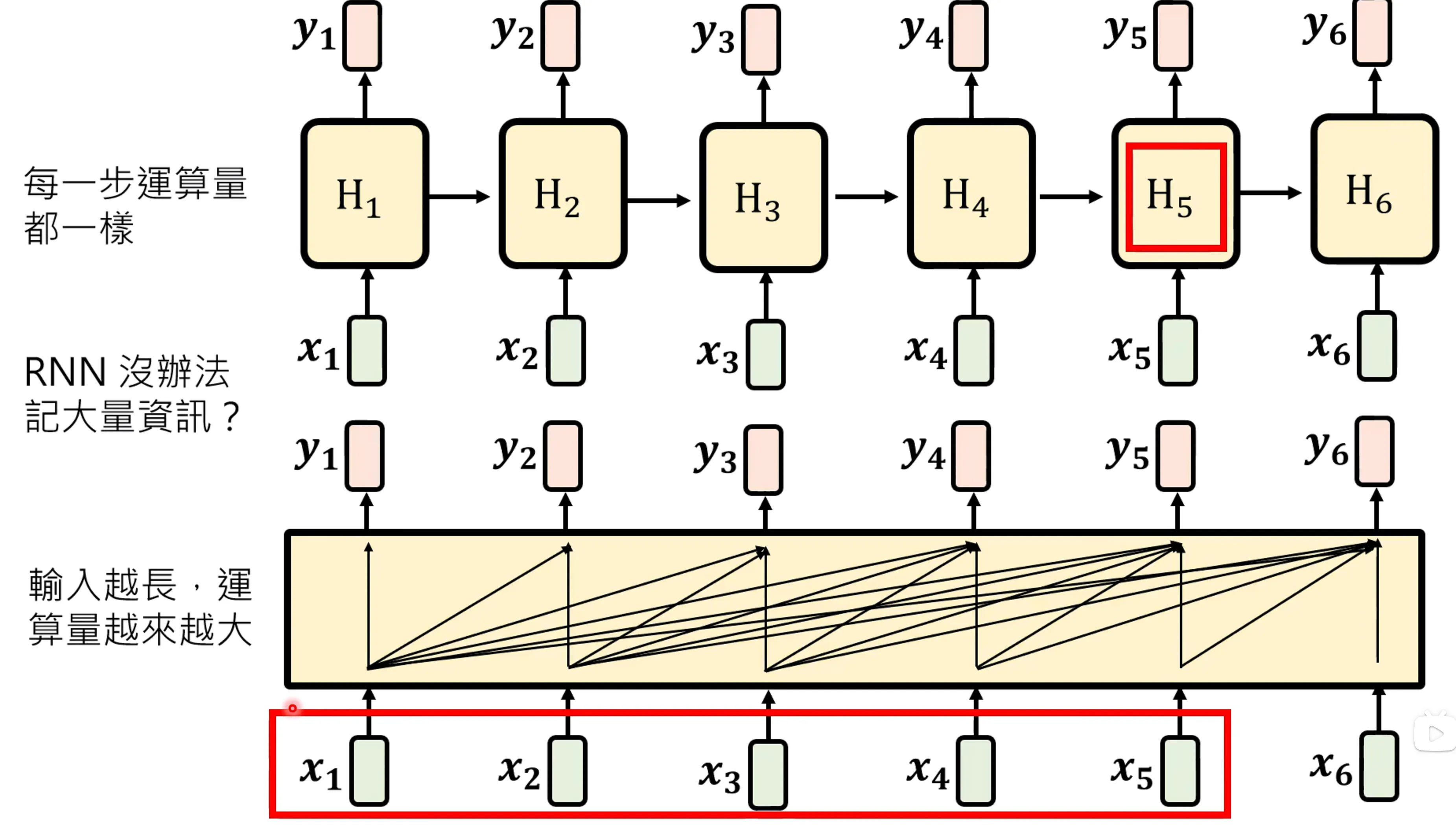
对比RNN和attention在运算量上的不同,RNN在每步运算量都是相同的,而self-attention会随着输入的增加,运算量增加。
 是RNN由于隐状态比较小,所以没办法记住很多的信息吗?其实并不是这样。Attention is ALL you Need这篇文章并不是发明了attention,而是拿掉了Attention以外的东西,而transformer最大的好处在论文中也是提到了是
是RNN由于隐状态比较小,所以没办法记住很多的信息吗?其实并不是这样。Attention is ALL you Need这篇文章并不是发明了attention,而是拿掉了Attention以外的东西,而transformer最大的好处在论文中也是提到了是并行化。Transformer可以很快的得到现有的答案,从而计算差异,进行参数的更新。
正常我们理解的loss计算可能是一步一步的auto aggressive的方式,但是在transformer在训练的时候,可以一次性的给出,通过向右移位可以得到每一个时刻下的token的groundtruth,从而批量的计算loss,(这个应该是要配合mask_attention操作,看不到右侧的信息)
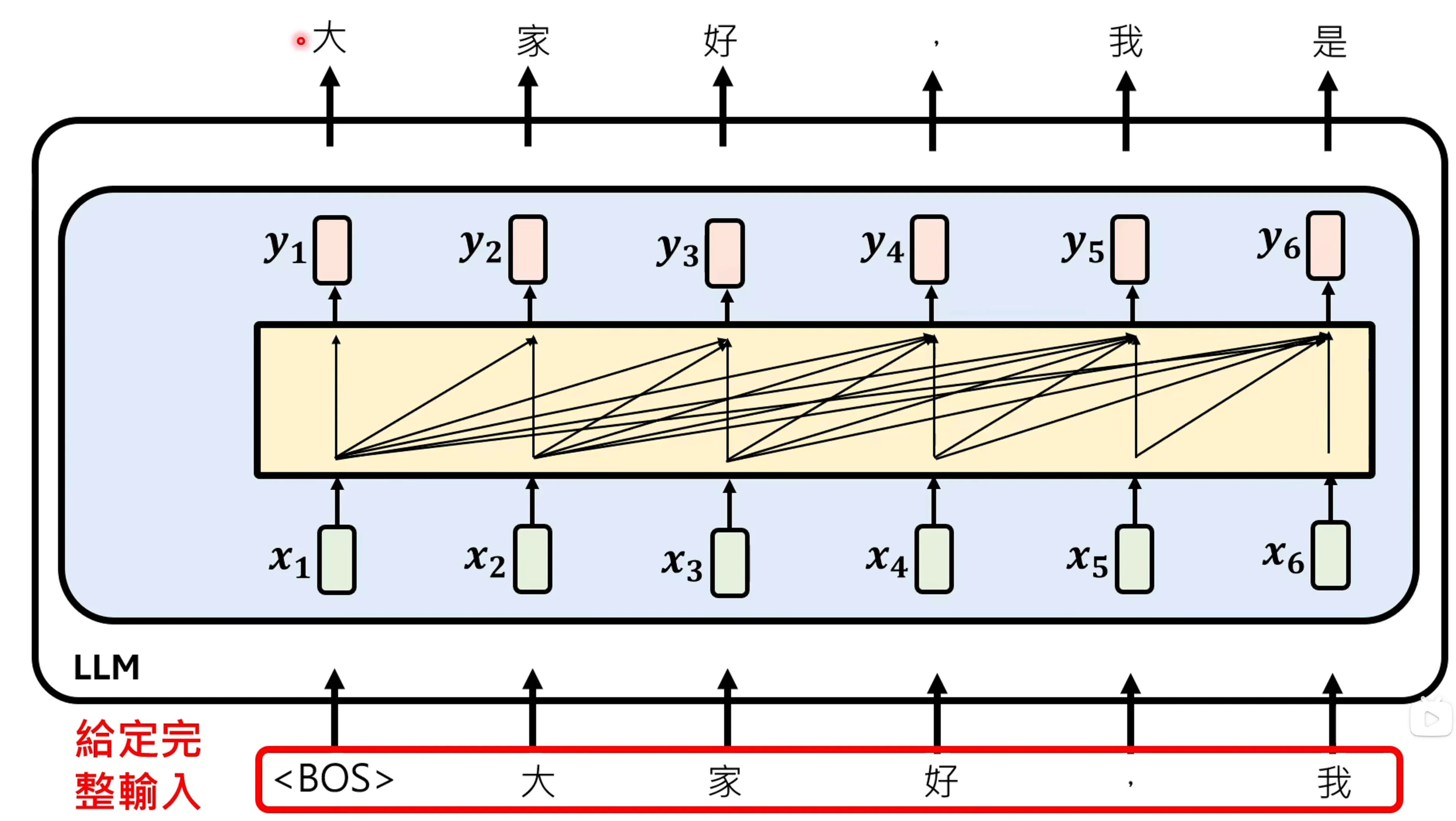
而transformer可以利用GPU进行并行化的计算, 因为GPU擅长去做矩阵的运算。
![]()
很重要的点是需要一个处理长sequence的方法,因为现在的模态也变得越来越多。而transformer对于长序列的处理能力是有限的,所以有人就在想能够让RNN去做训练时候的并行呢?如果让最开始的为0,可以得到如下的展开的式子,但是最后还是一系列的变量的相乘,似乎这些变量都和相关,因此直接将去掉A有。
 将其用线性的转移变换带入,则变成都是和相关的向量。
将其用线性的转移变换带入,则变成都是和相关的向量。
 如果对于写成矩阵,同时将输出过程进行展开,用线性变换表示从xt经过Ht到的映射
如果对于写成矩阵,同时将输出过程进行展开,用线性变换表示从xt经过Ht到的映射
 最后对再进行向量分解,在用重新进行表示有:这里就是q,k,v的transformer的形式了。
最后对再进行向量分解,在用重新进行表示有:这里就是q,k,v的transformer的形式了。
 实际上就是对于v的加权的结果,这个和self-attention很像,但是对于attention的weight并没有经过softmax来进行归一化,这个叫做Linear attention。
实际上就是对于v的加权的结果,这个和self-attention很像,但是对于attention的weight并没有经过softmax来进行归一化,这个叫做Linear attention。

Linear attention的好处,训练的时候像self-attention,而在inference的过程中更像RNN。实际上就像是RNN拿掉了隐变量的转移的过程。
H实际上是一个memry的bank,而每次实际上是对这个memory的更新,v是决定要写入哪些资讯,而k是决定要写入哪些。
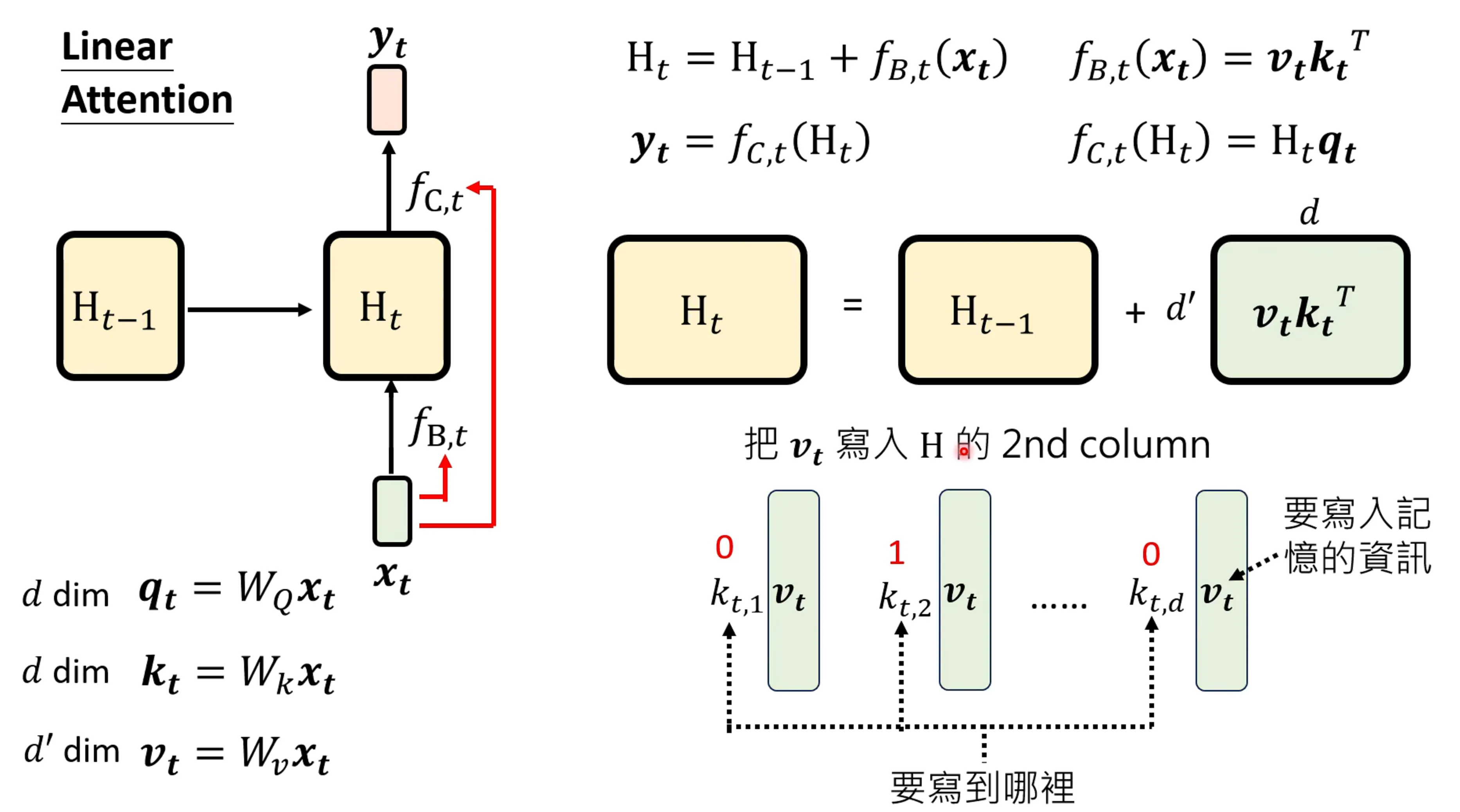 所以,transformer可以作为一个特殊的RNN,也是一种attention,只差了softmax而已。
所以,transformer可以作为一个特殊的RNN,也是一种attention,只差了softmax而已。
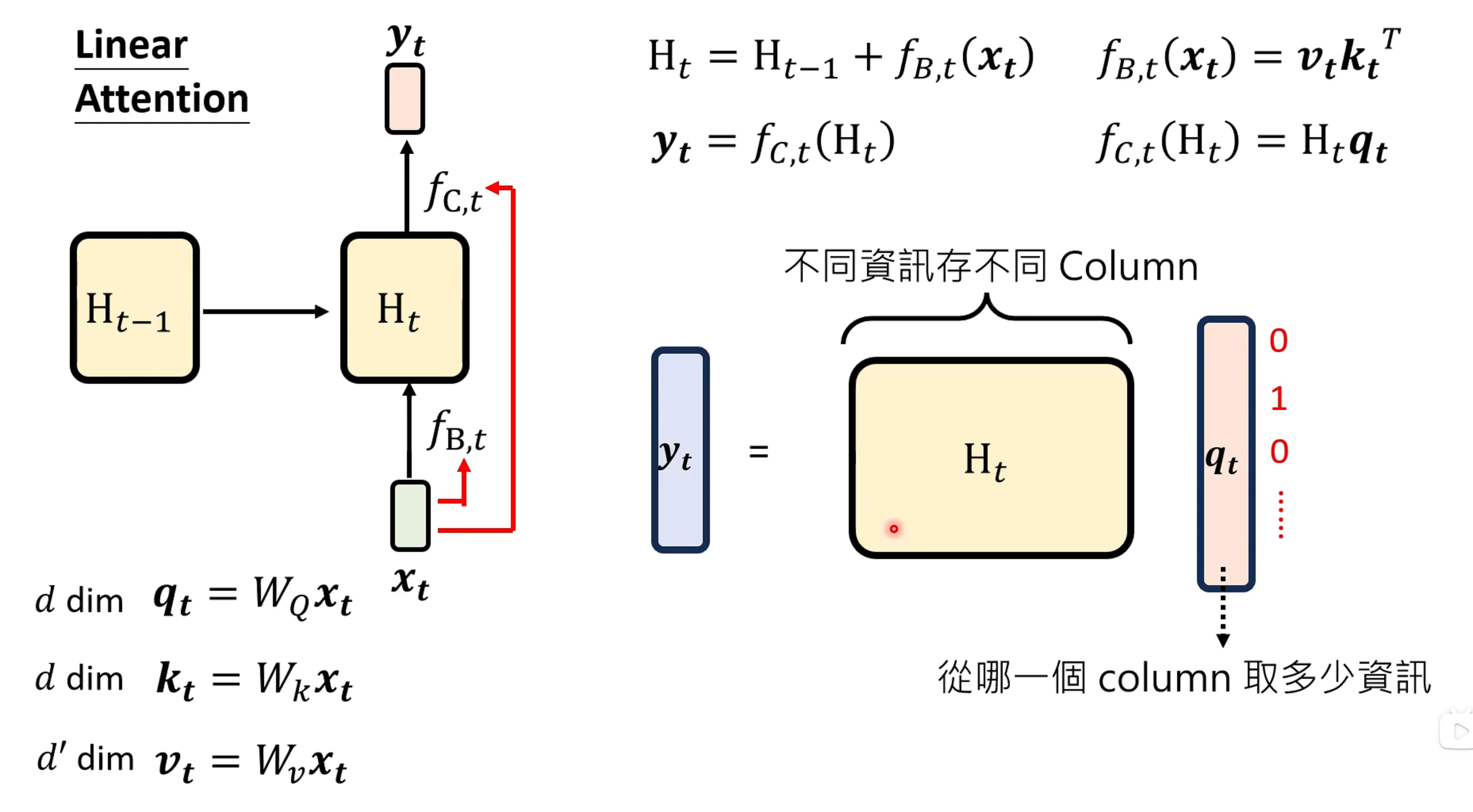 但现在linear attention还是赢不错transformer的,RNN似乎记忆是有限的,他存储的记忆似乎是有限的:
但现在linear attention还是赢不错transformer的,RNN似乎记忆是有限的,他存储的记忆似乎是有限的:
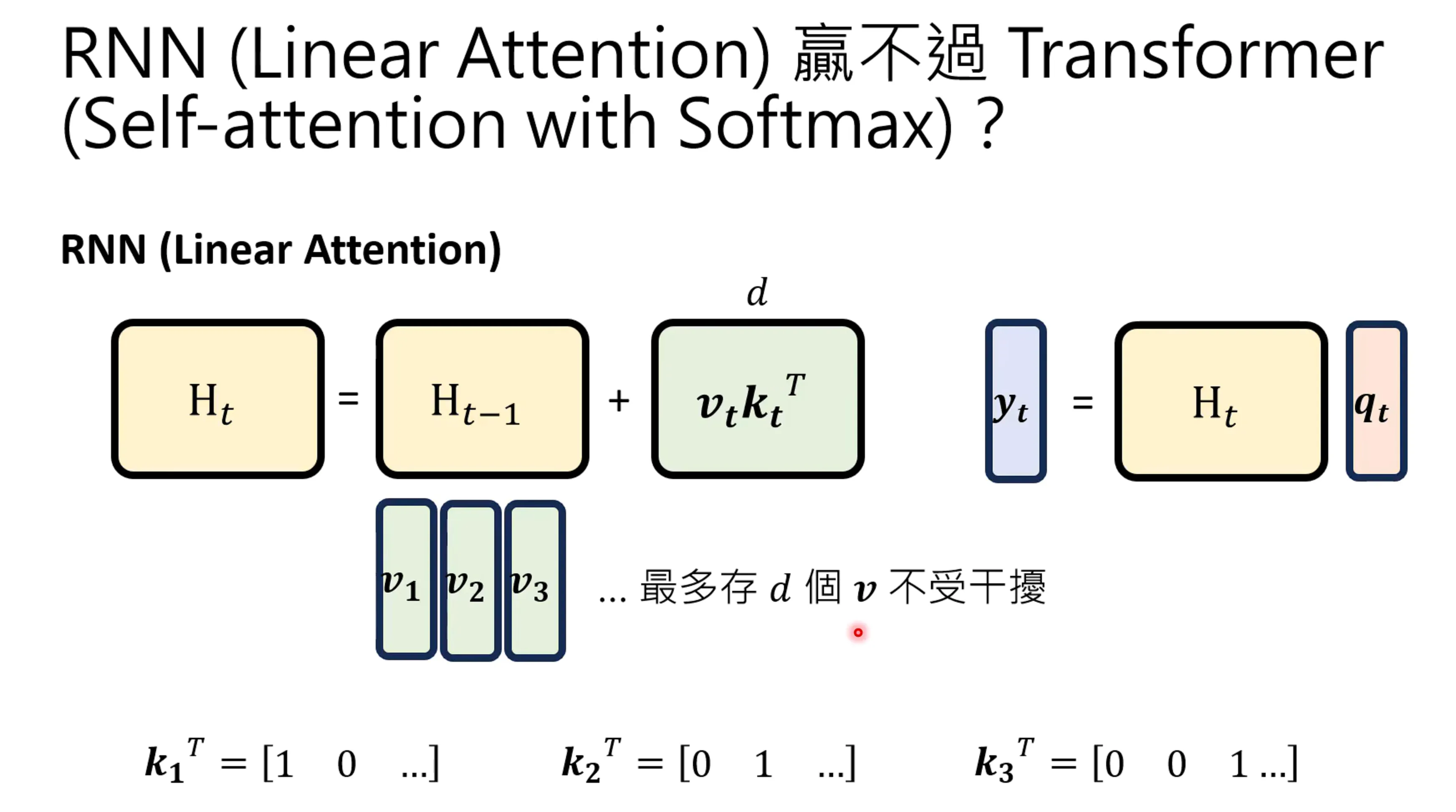
但transormer存的东西也是有限的, 当t大于d时候,总有一个元素是大于0的,就会导致对v进行加权,出现混淆。
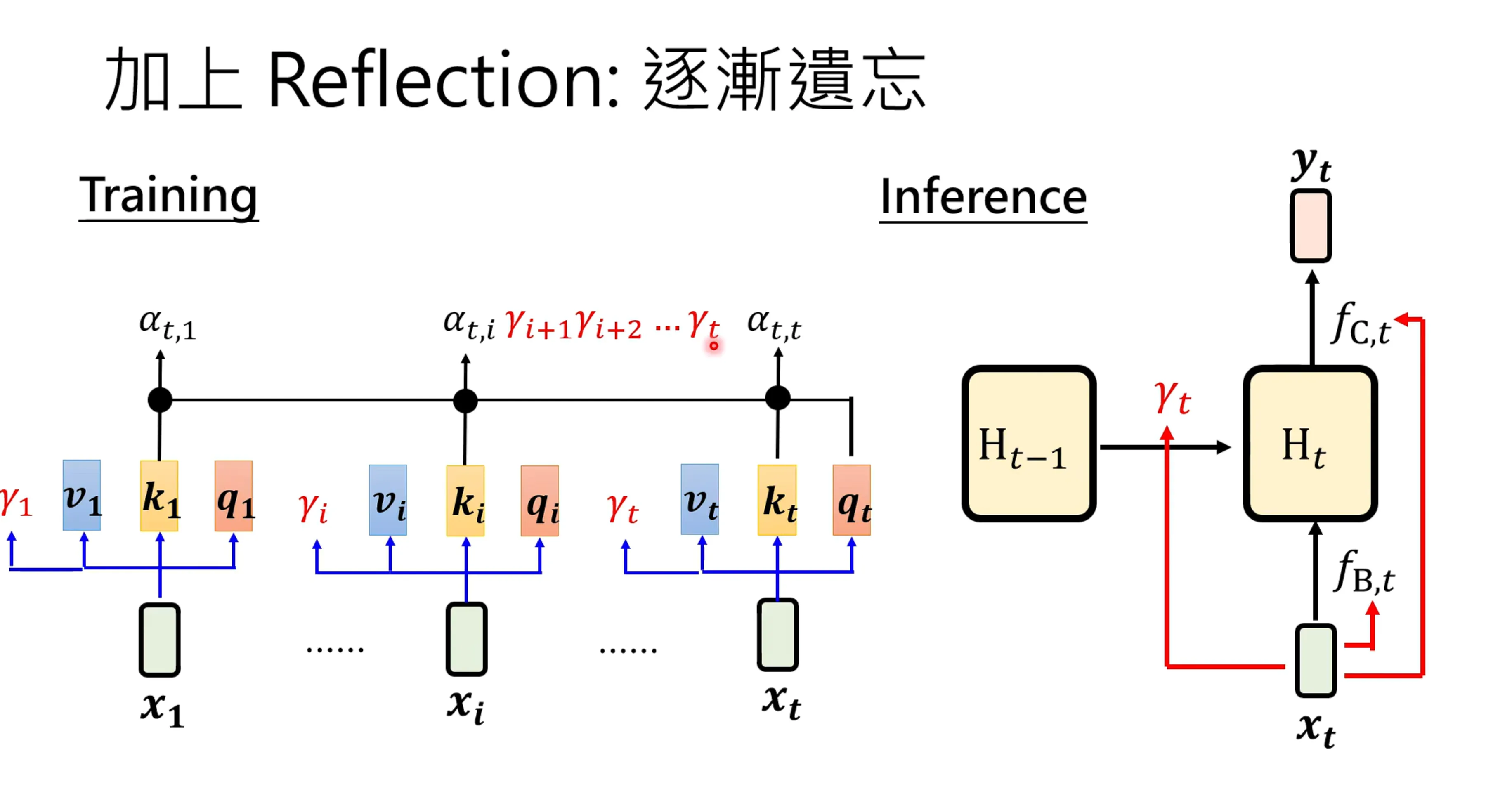
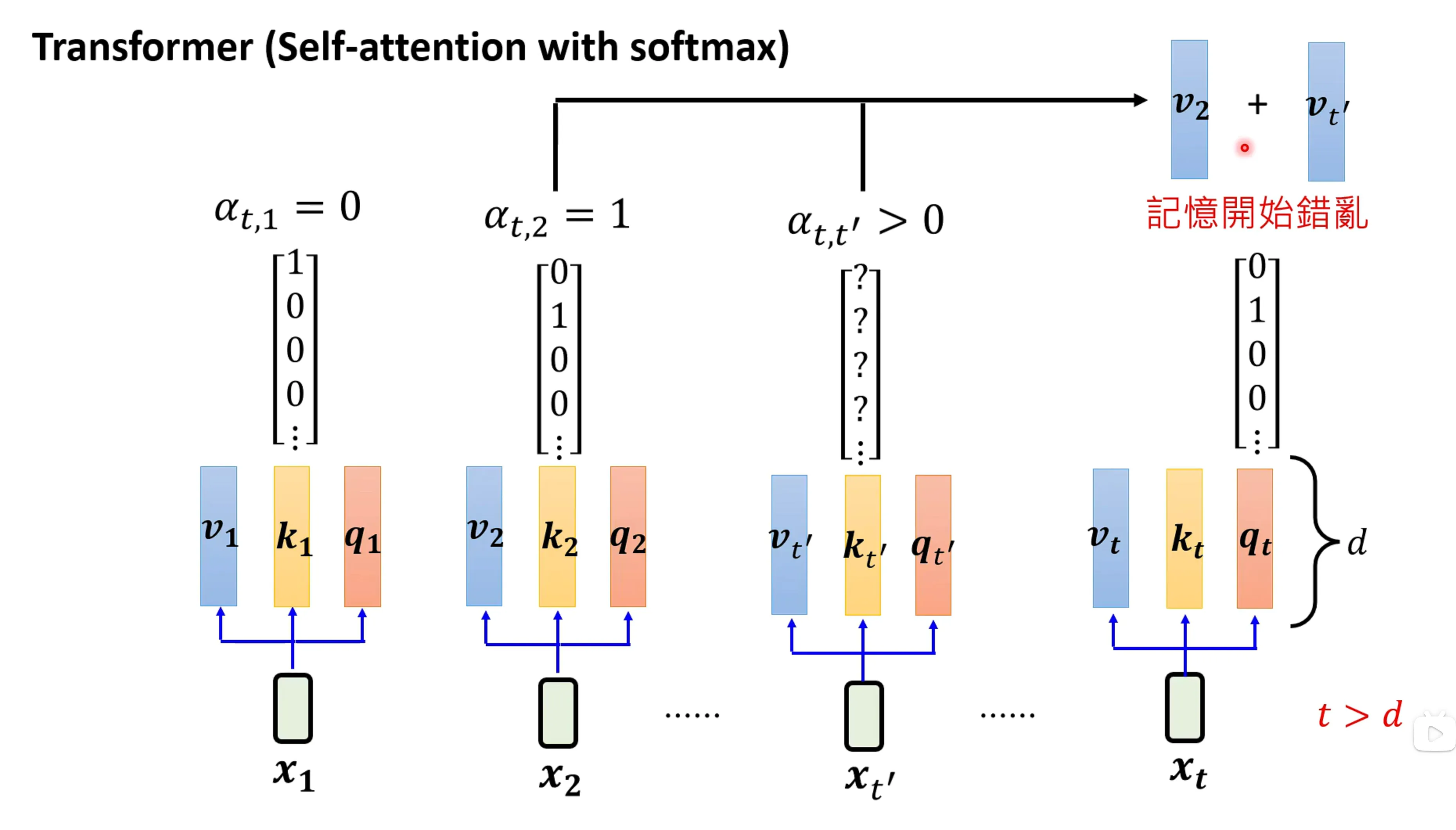 Linear attention的记忆永远不会改变,因为它不会像softmax一样做全局的平均调整?这里理解有点奇怪,因此有人加入Reflection机制,让H逐渐遗忘。
Linear attention的记忆永远不会改变,因为它不会像softmax一样做全局的平均调整?这里理解有点奇怪,因此有人加入Reflection机制,让H逐渐遗忘。
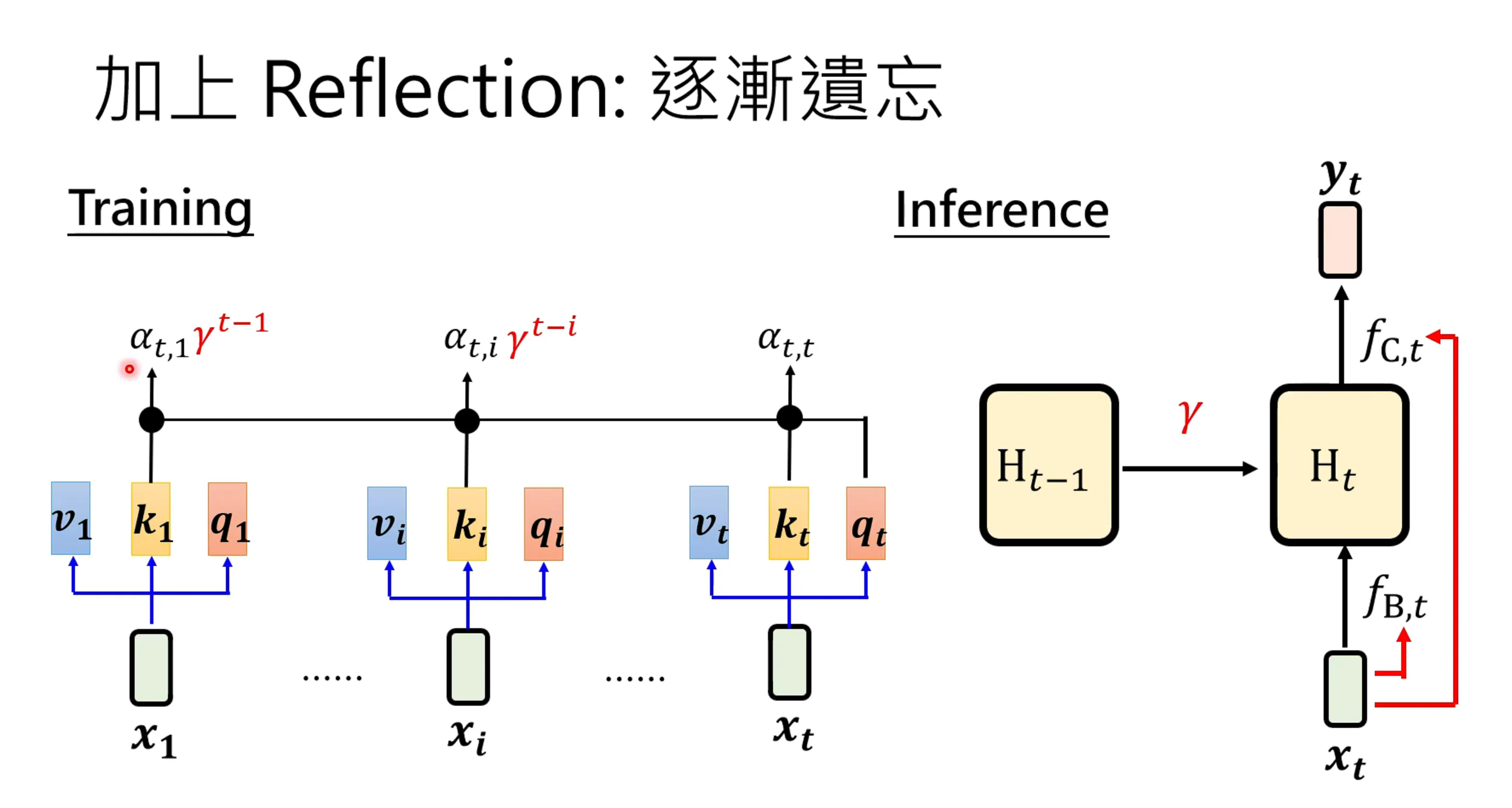 在这只有有个更加进阶的版本,将gamma改为,让gamma随着时间改变,还是老样子,对输入的进行线性变换,之后通过sigmod,
在这只有有个更加进阶的版本,将gamma改为,让gamma随着时间改变,还是老样子,对输入的进行线性变换,之后通过sigmod,

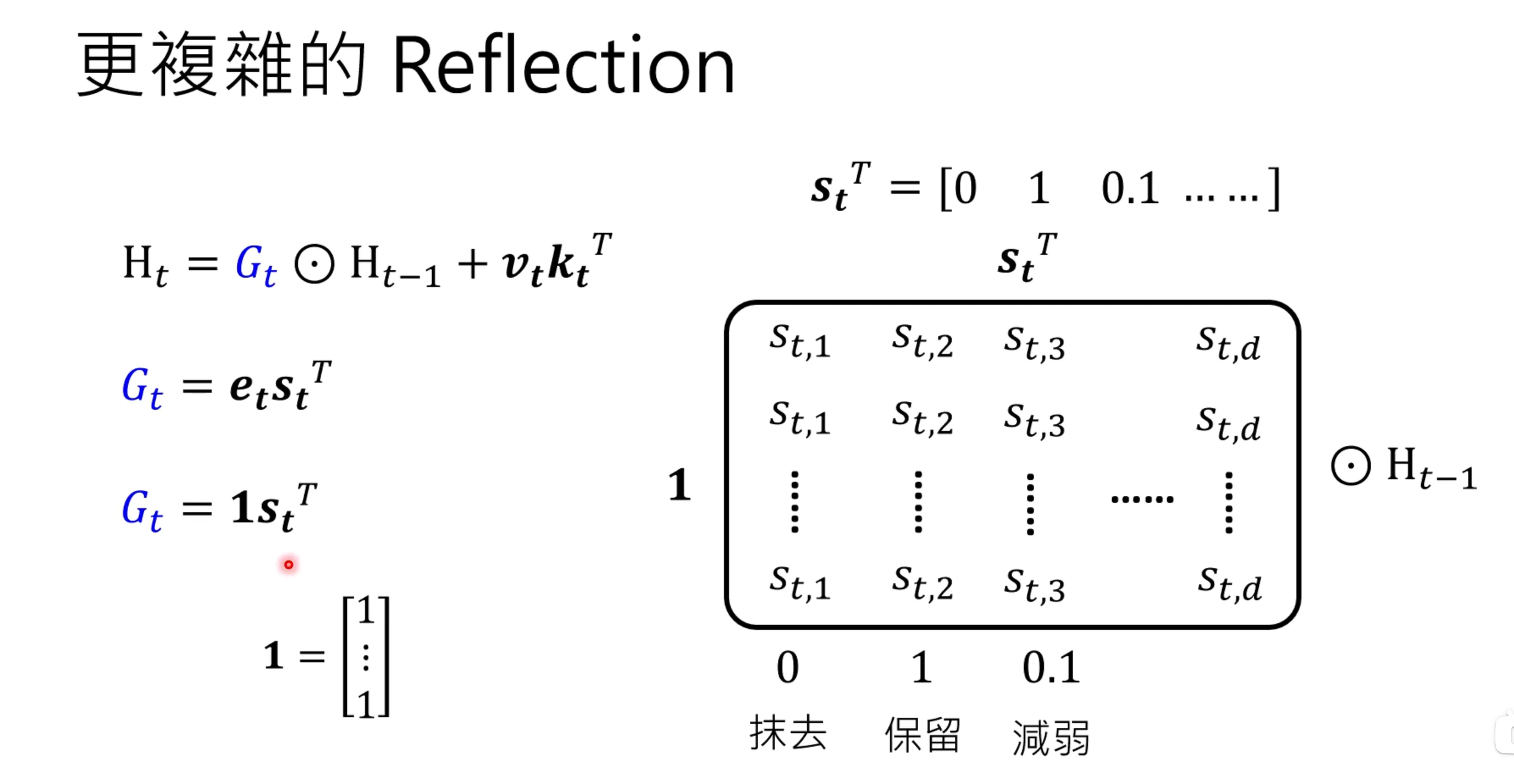
 有人想要对当中的记忆的元素进行操控,因此就引入了哈德马积,对于可以进行向量分解,有研究表明第一个向量取1影响不大,则其物理意义就是对的每一列进行操作,比如抹去,比如保留和减弱。
有人想要对当中的记忆的元素进行操控,因此就引入了哈德马积,对于可以进行向量分解,有研究表明第一个向量取1影响不大,则其物理意义就是对的每一列进行操作,比如抹去,比如保留和减弱。
 Mamba比较能打,能比过transformer。
Mamba比较能打,能比过transformer。

在分类的问题上可能没必要去考虑attention的架构,用CNN可能是足够了,但对于分割任务上来说,mamaba这种self-attention的架构还是很不错的。
大模型训练方法(预训练---对齐)#
语言模型的训练有三个阶段,第一阶段是pre-train,通过网络大量爬到的资料,让网络有基本的文字接龙的能力。第二阶段是SFT,告诉模型什么样的输出是对的,第三阶段是RLHF,由人告诉什么回答是比较好的。第三阶段需要人类提供回馈。把人类参与的阶段叫做alignment,也就是第二和第三阶段,有时候也称为fine-tune。
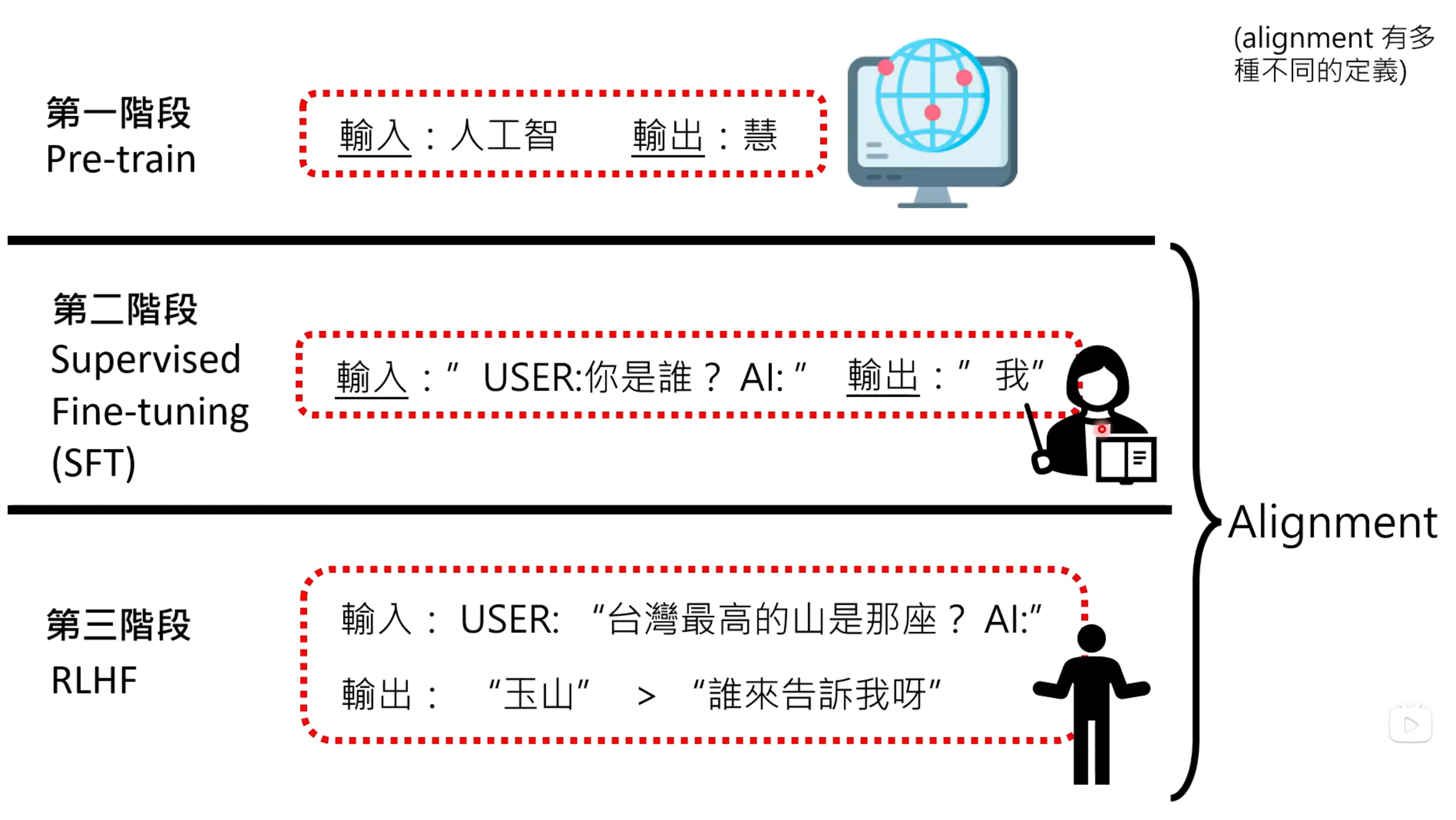
重要:模型里面有base,往往是只有做pretrain,没有做alignment的模型。 而模型里面有chat或者instruct关键字的代表是对齐过后的,

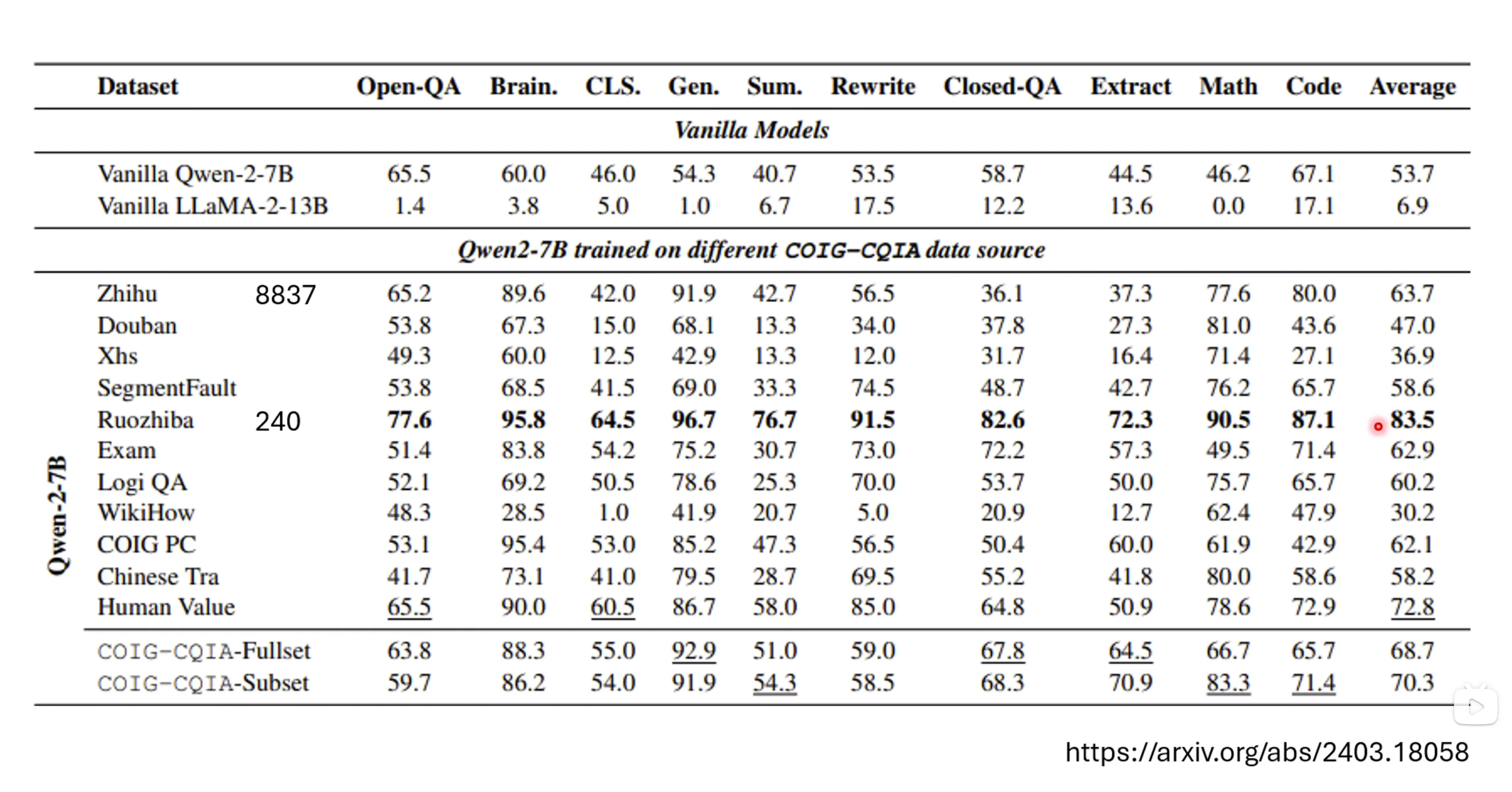
 Alignment资料用的不多,LLaMA2用的20000多条数据进行的收集微调,就可以获得很好的结果了。Alignment的资料的质量是非常重要的,Quality is all you need。240笔资料是比8837比资料最终效果要更好的。
Alignment资料用的不多,LLaMA2用的20000多条数据进行的收集微调,就可以获得很好的结果了。Alignment的资料的质量是非常重要的,Quality is all you need。240笔资料是比8837比资料最终效果要更好的。
Knowledge Disti#
让老师模型的信息去监督自己的LLM进行Fine tune 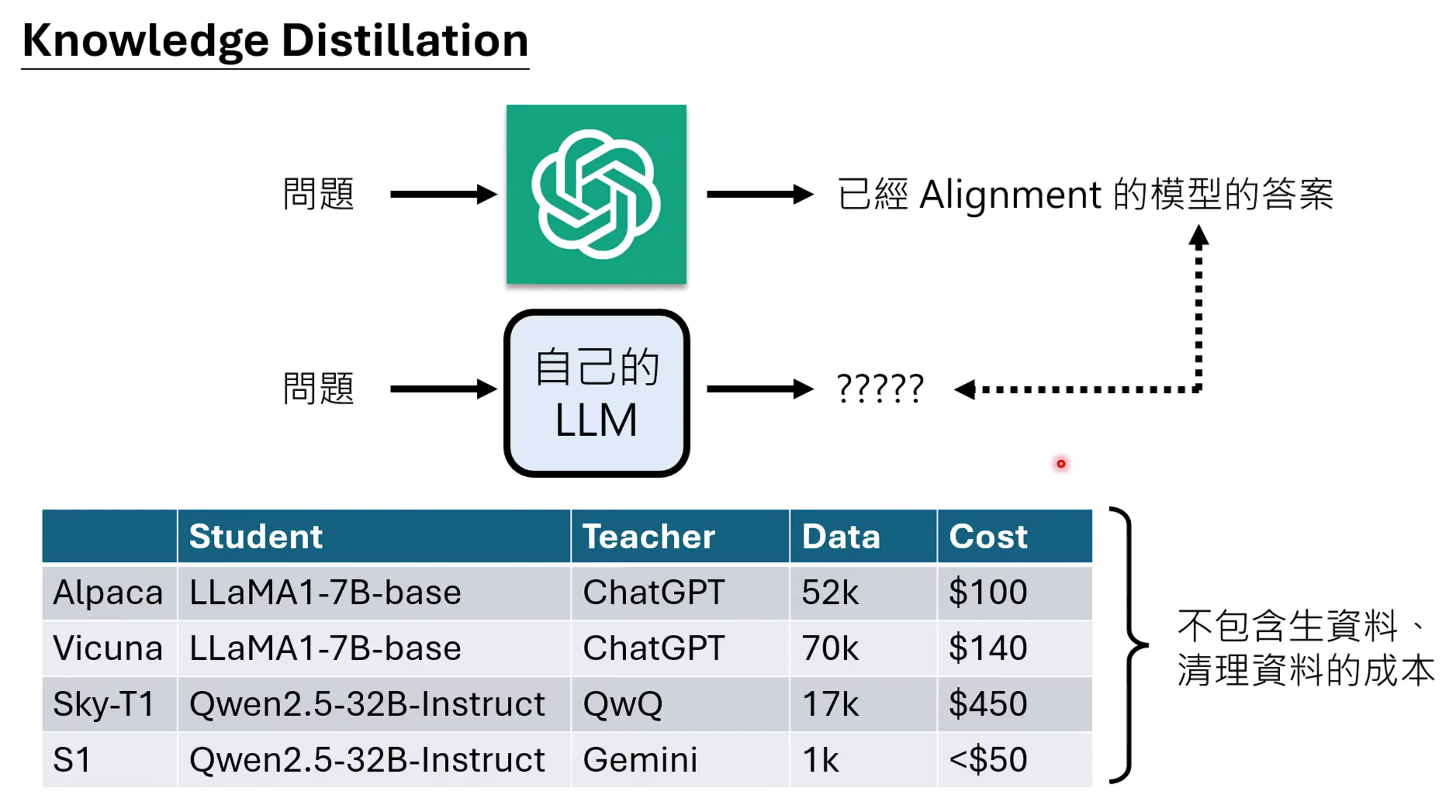
这里面如何选取资料也是个很关键的问题(选择模型生成的答案),一般来说长一点的资料会好一些,但是并不绝对,有些模型用更短的资料已久可以得到比较好的结果。
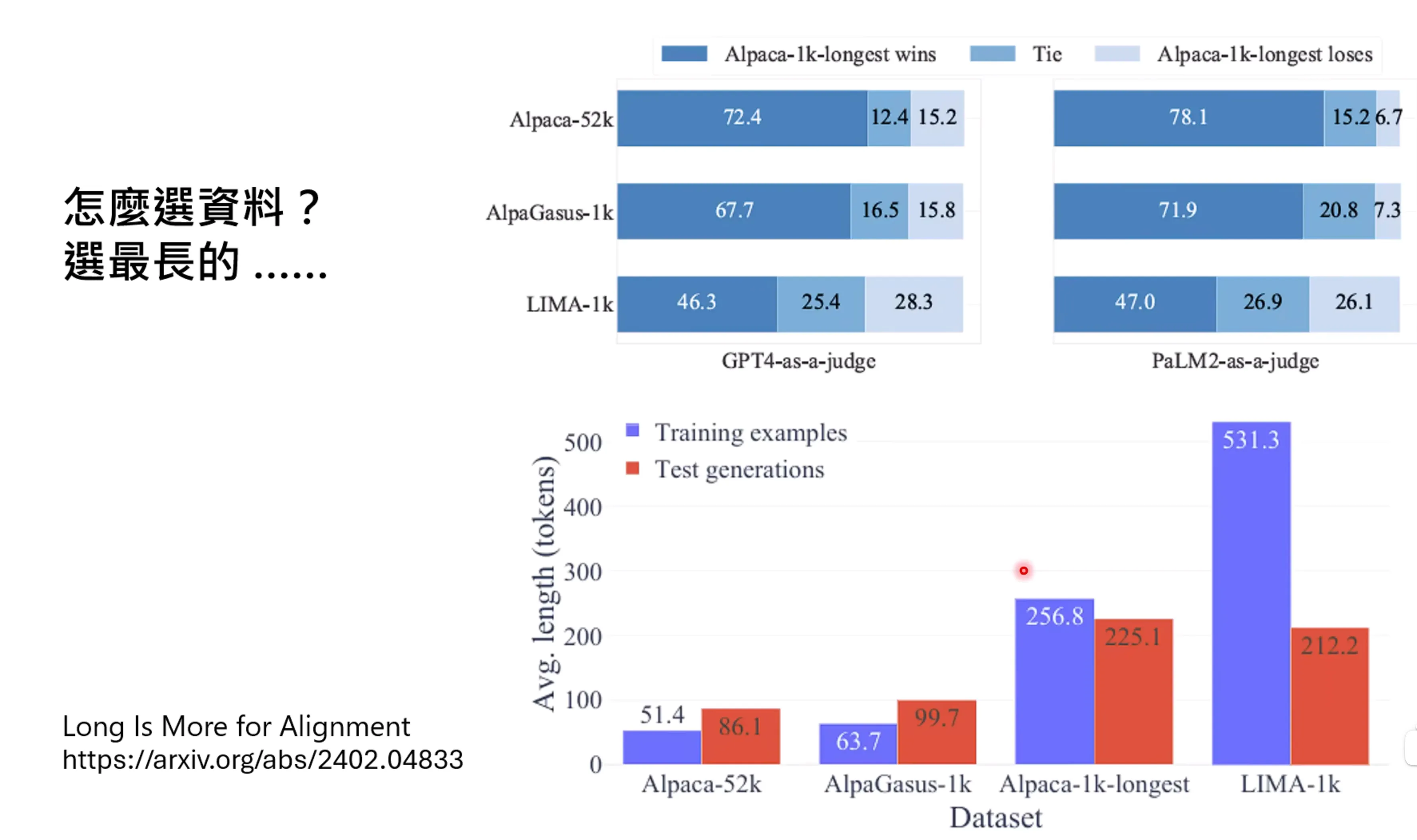
另一个比较关键的事情是,如何给模型一个比较好的问题?问题如何来是个很关键的。台大这边的老师只用了前半句做提问,甚至不是个问题,让模型输出后半句,利用GPT-4生成后半句的数据做监督,甚至最终的效果更好。实际上alignment前后模型的实际行为差异并不大。
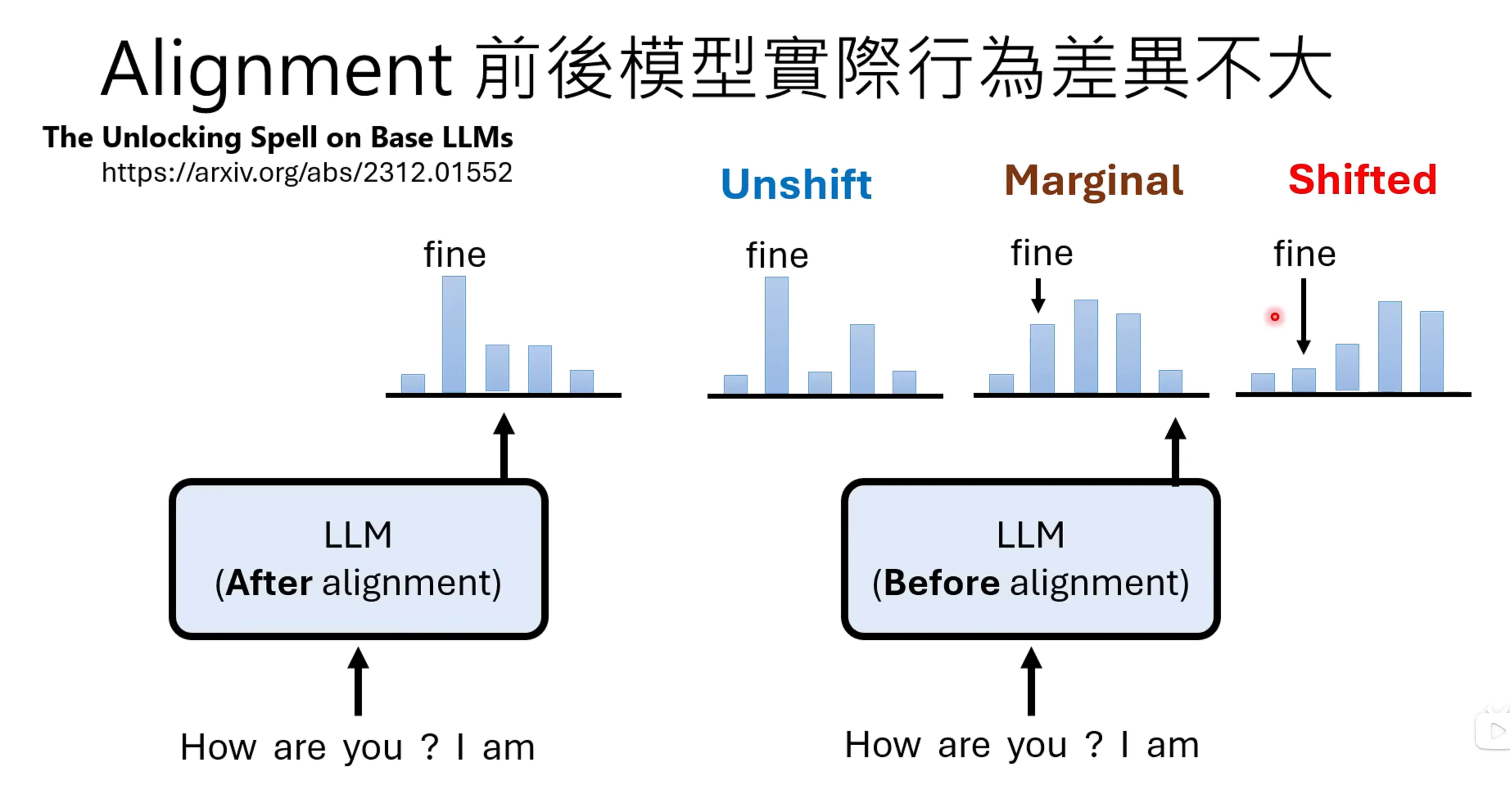
 response tuning,当没有问题,只给他回答的时候,已久可以让模型学到很多东西。对于没办法alignment的token如果直接对齐出现的高铝进行修改,实际上也能证明修改过后的模型也有大约1/4的概率能够赢得instruction tunning的结果。Alignment实际上并未对pre-train的模型造成了很大的变化。
response tuning,当没有问题,只给他回答的时候,已久可以让模型学到很多东西。对于没办法alignment的token如果直接对齐出现的高铝进行修改,实际上也能证明修改过后的模型也有大约1/4的概率能够赢得instruction tunning的结果。Alignment实际上并未对pre-train的模型造成了很大的变化。
Pretrain#
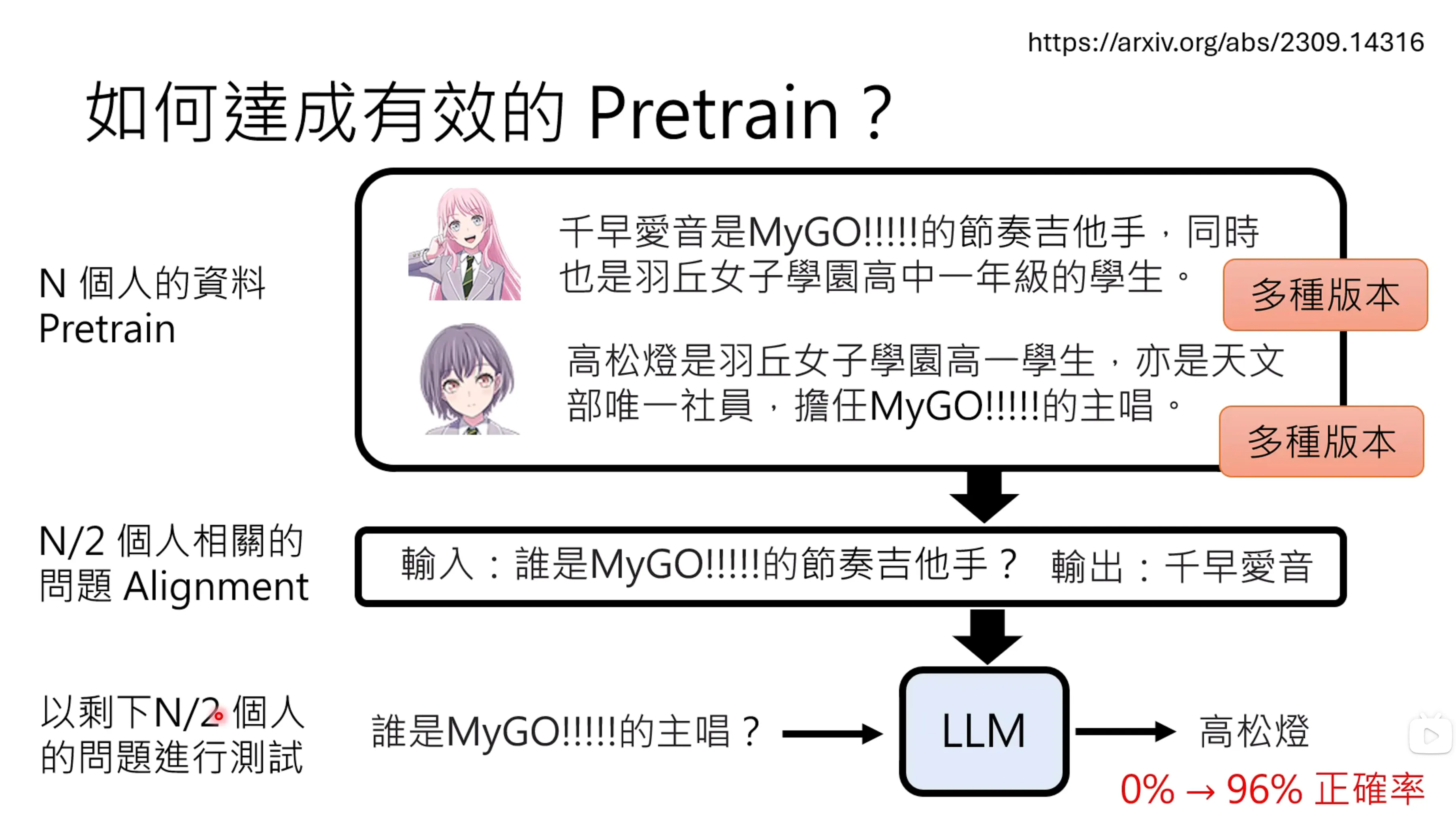
如何得到更好的pretrain呢?同样的资料,有不同的介绍方式对于pretrain是重要的事情。对于同一个人的不同版本去做介绍,模型的输出的正确率可以大幅度提高。此外,也并不是所有的资料都需要有不同的介绍,只要有部分的多版本的细腻些,模型就可以完成对于一些混淆问题的理解能力的提升。
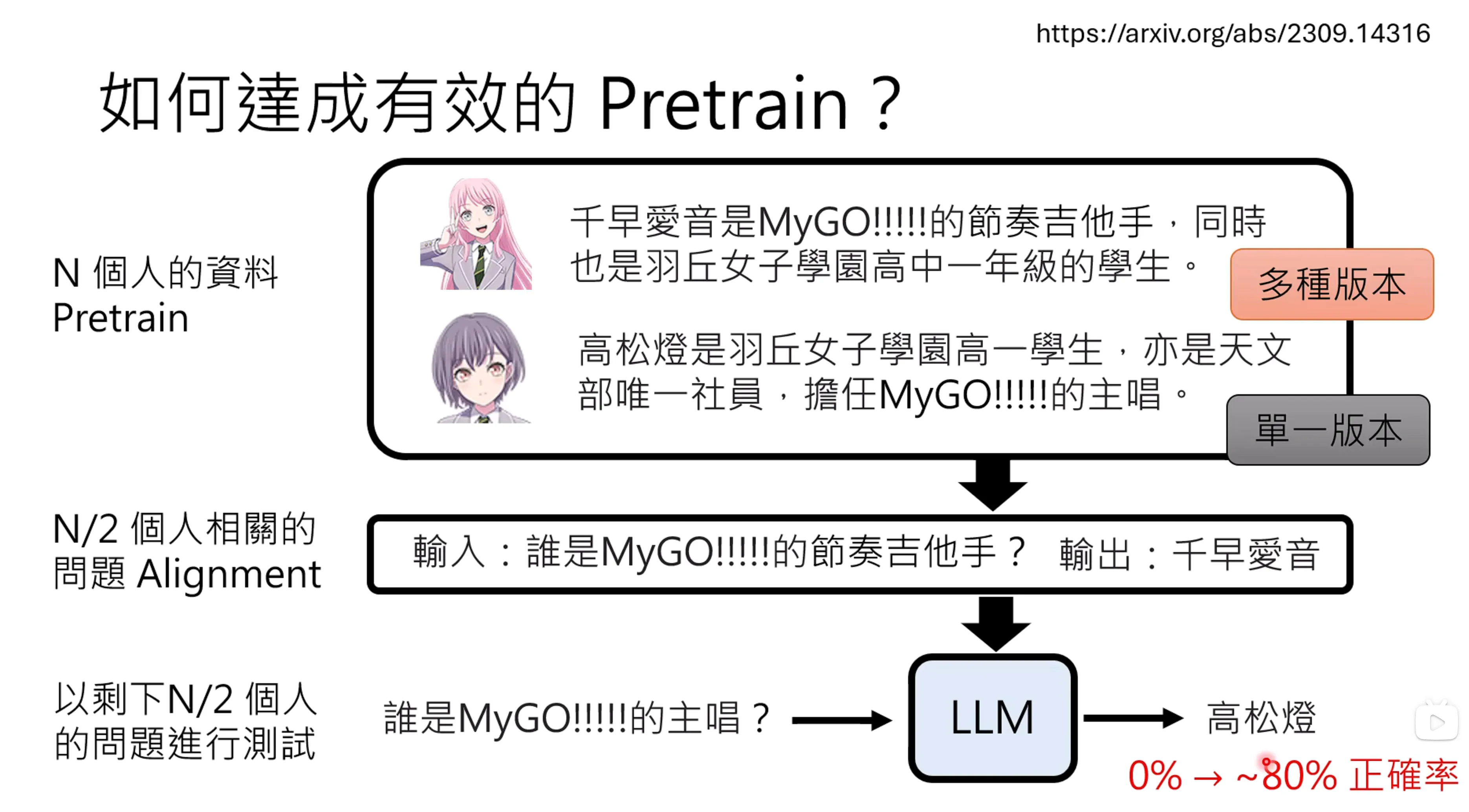
现在的pretrain的资料,LLaMA3 15T的token,DeepSeek-V3有14.8T的token。

Hugging face已经有开源的15T的token了

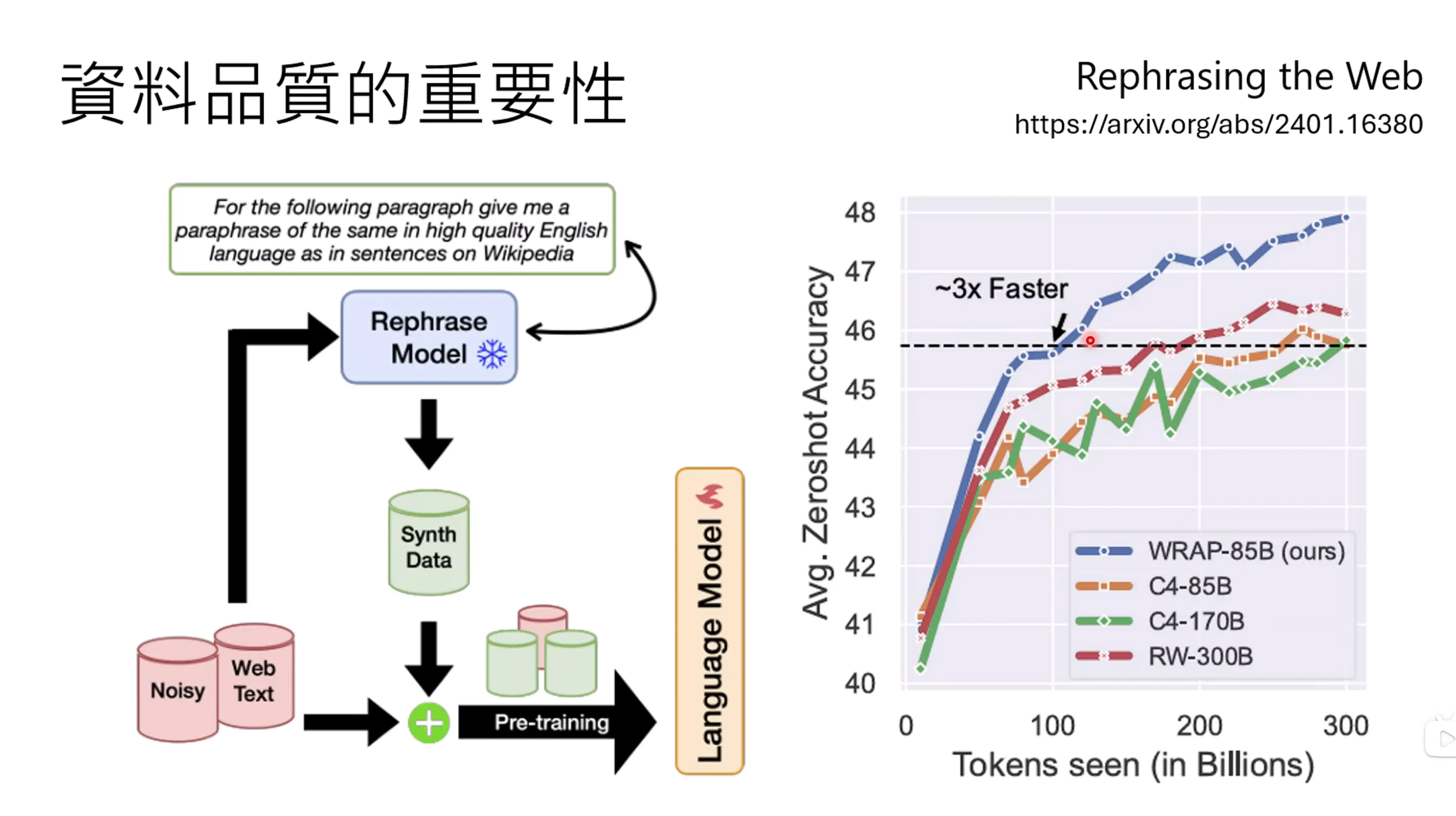
资料的品质比较重要,apple用了文字处理的mode对带噪声的输入进行了清洗,用于训练,可以发现可以减少3倍的token的输入的个数,可见高质量数据的重要性。
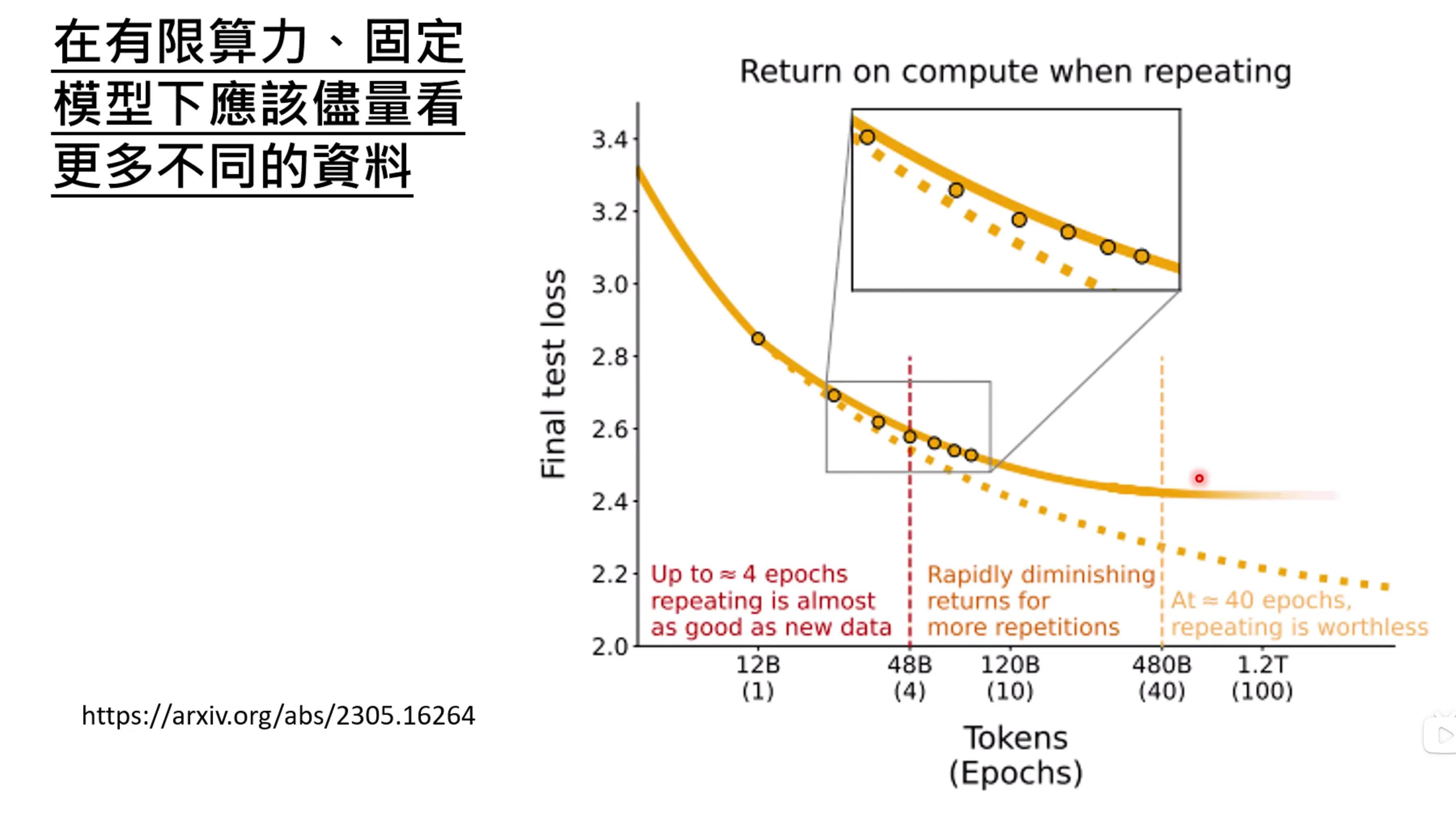
去除重复的文章和重复的段落很重要,在有限的算力下,固定模型下应该看更多不同的资料,而不是让他反复看一个内容。
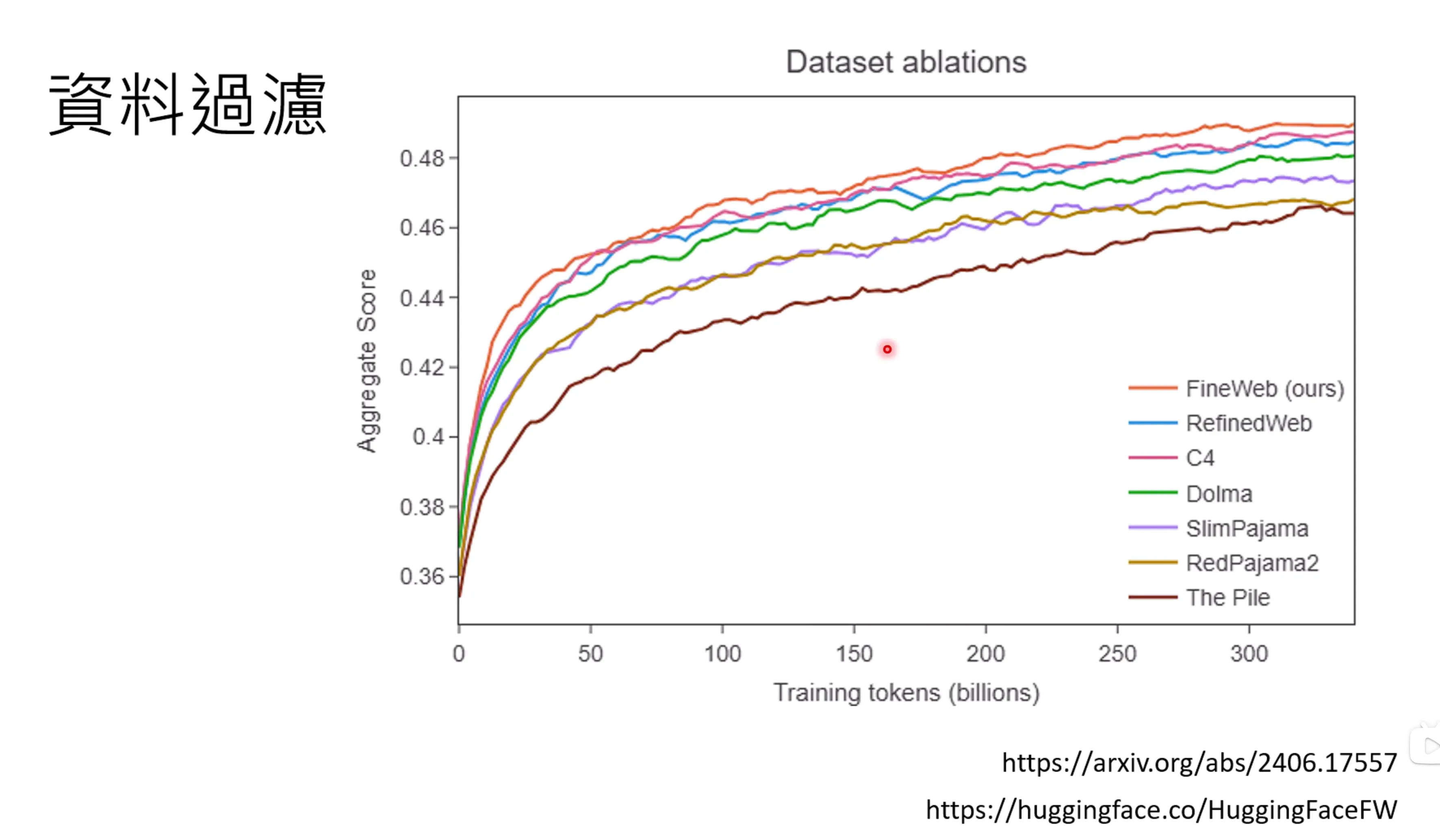
什么样的data filter是有效的呢?怎么样过滤资料,HuggingFaceFW fineweb有说明
Alignment的极限#
看起来并不是说给gpt4输出的数据模型的真实能力就会显著提升,有人在LLaMA1上进行了测试,结果表明很多实际输出的内容反而是错误的。
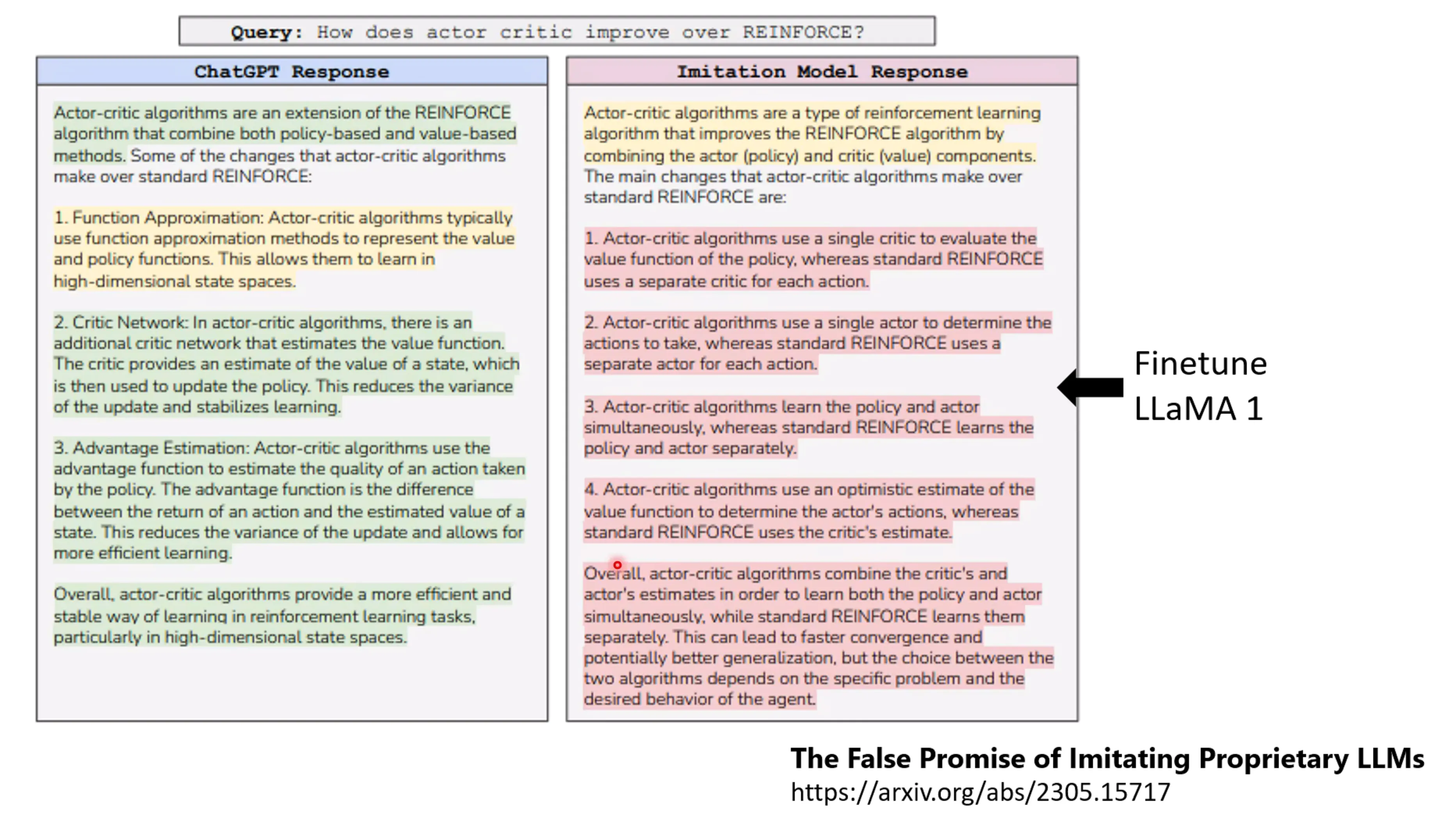
有研究将Alignment分成了4类,Highly Known,模型本来就会的东西,pretrain模型就可以答对,不用alignment,示例问题和答案是为了做in-context learning的,防止他胡乱输出;Maybe Known,模型有这方面的知识,但问法要问对才行;Weakly Known,问模型的时候不一定给出正确答案,有几率得到正确答案;剩下的是模型始终学不会的,为Unkown,实验结果表明:让模型学本来他知道的东西是更加有用的,而如果让他学本来不知道爱的东西会破坏模型的实际的性能。
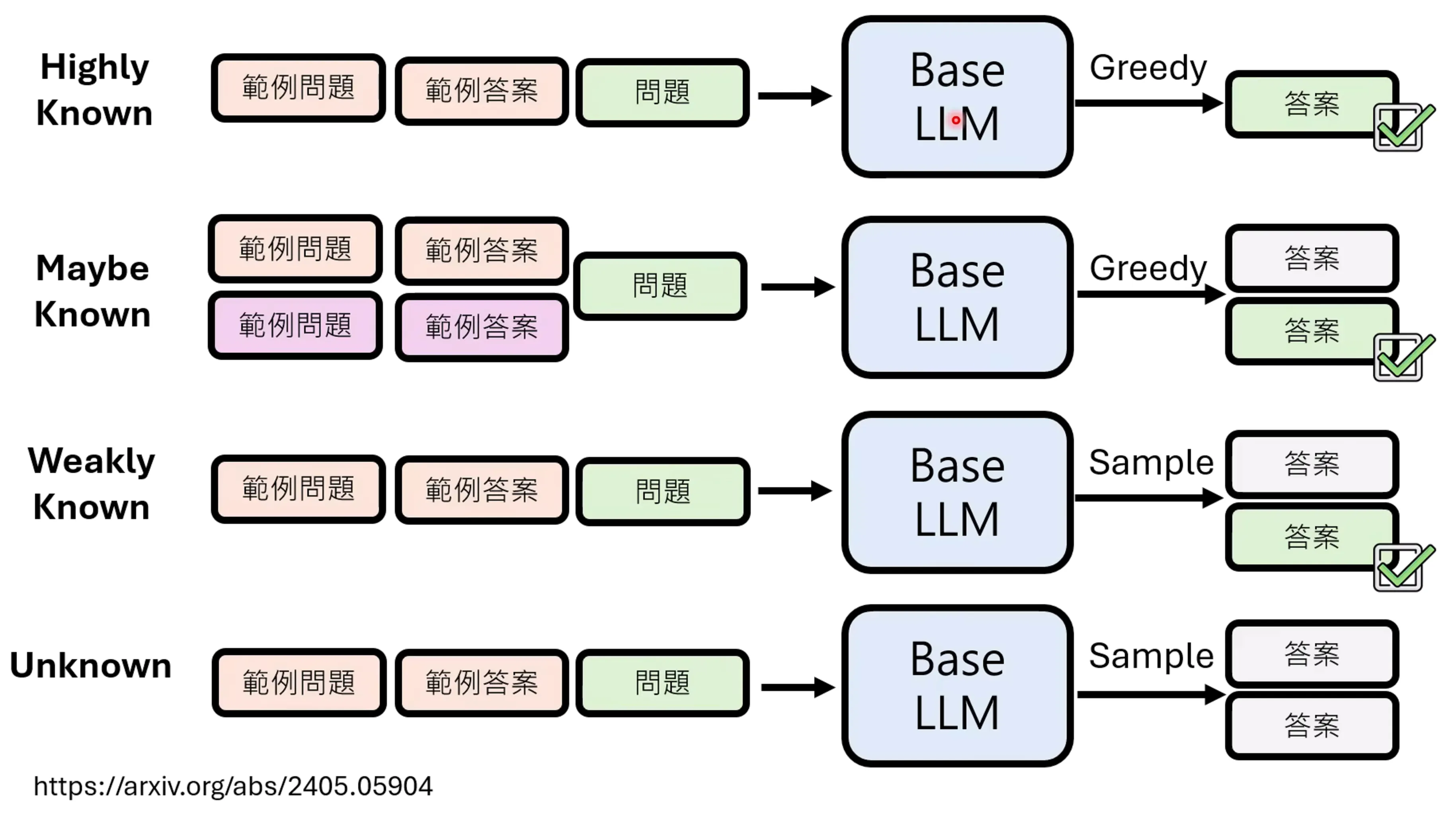 Maybe Known是这里面对模型训练提升最有帮助的,
同样有一个论文得到的观察,如果让模型非要学一个正确答案,反而没有让模型学一个不正确的答案的性能好。即强制让模型学正确答案在alignment阶段是其反作用的,alignment阶段并不能交给模型新的知识,而通常只是调整模型的行为。这个问题需要时在pretrain中已经知道的。
Maybe Known是这里面对模型训练提升最有帮助的,
同样有一个论文得到的观察,如果让模型非要学一个正确答案,反而没有让模型学一个不正确的答案的性能好。即强制让模型学正确答案在alignment阶段是其反作用的,alignment阶段并不能交给模型新的知识,而通常只是调整模型的行为。这个问题需要时在pretrain中已经知道的。
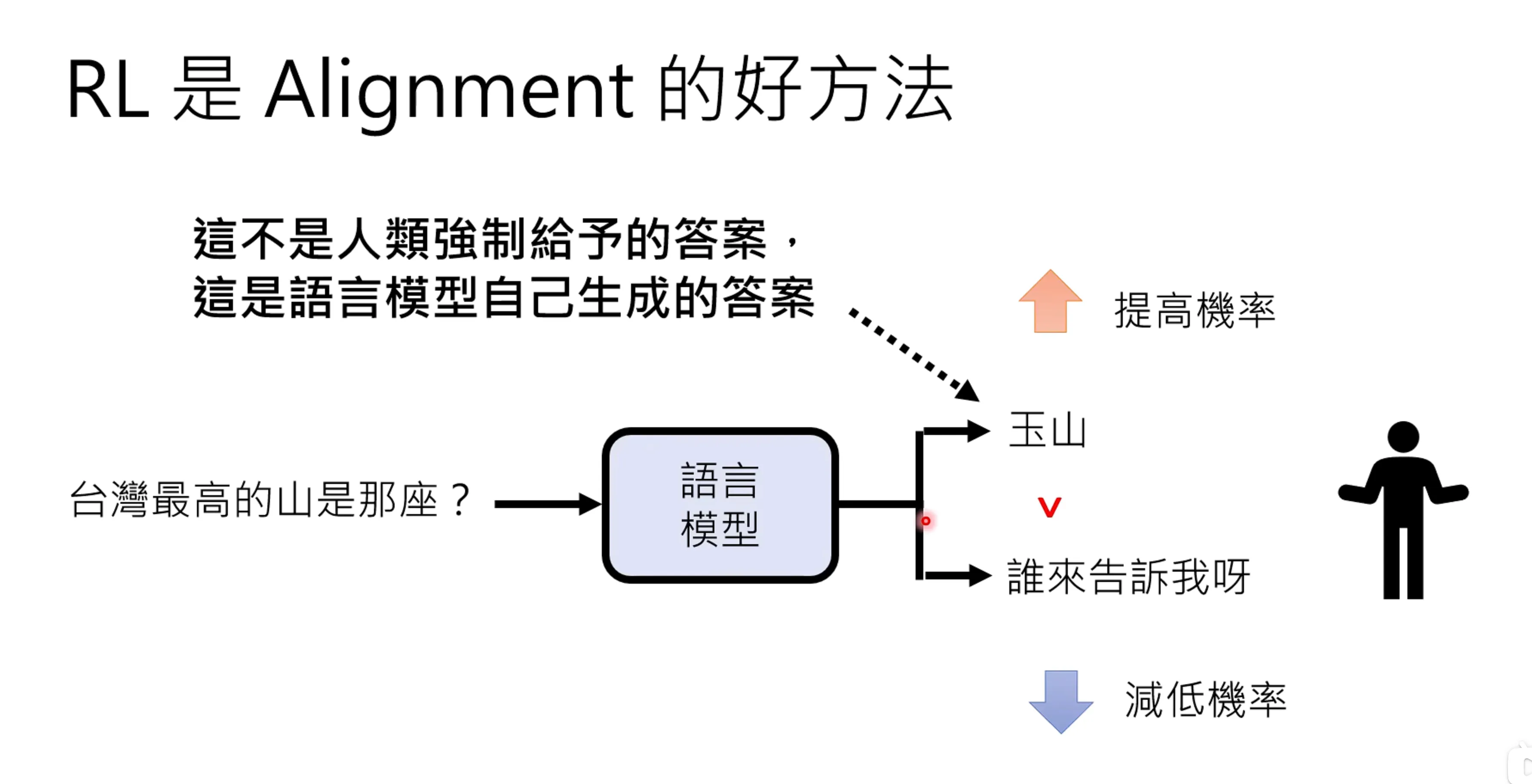
RL是Alignment的好方法, RL并不是人类强制给予大难,而是让模型自己生成答案。是激发模型自己本身的潜力。
Alignment可能没办法改变pretrain模型内部正确的知识,只能改变模型的行为而已,通过alignment是可以让模型不太想去讲脏话的,但里面训练的信息实际上是很难直接清除的。
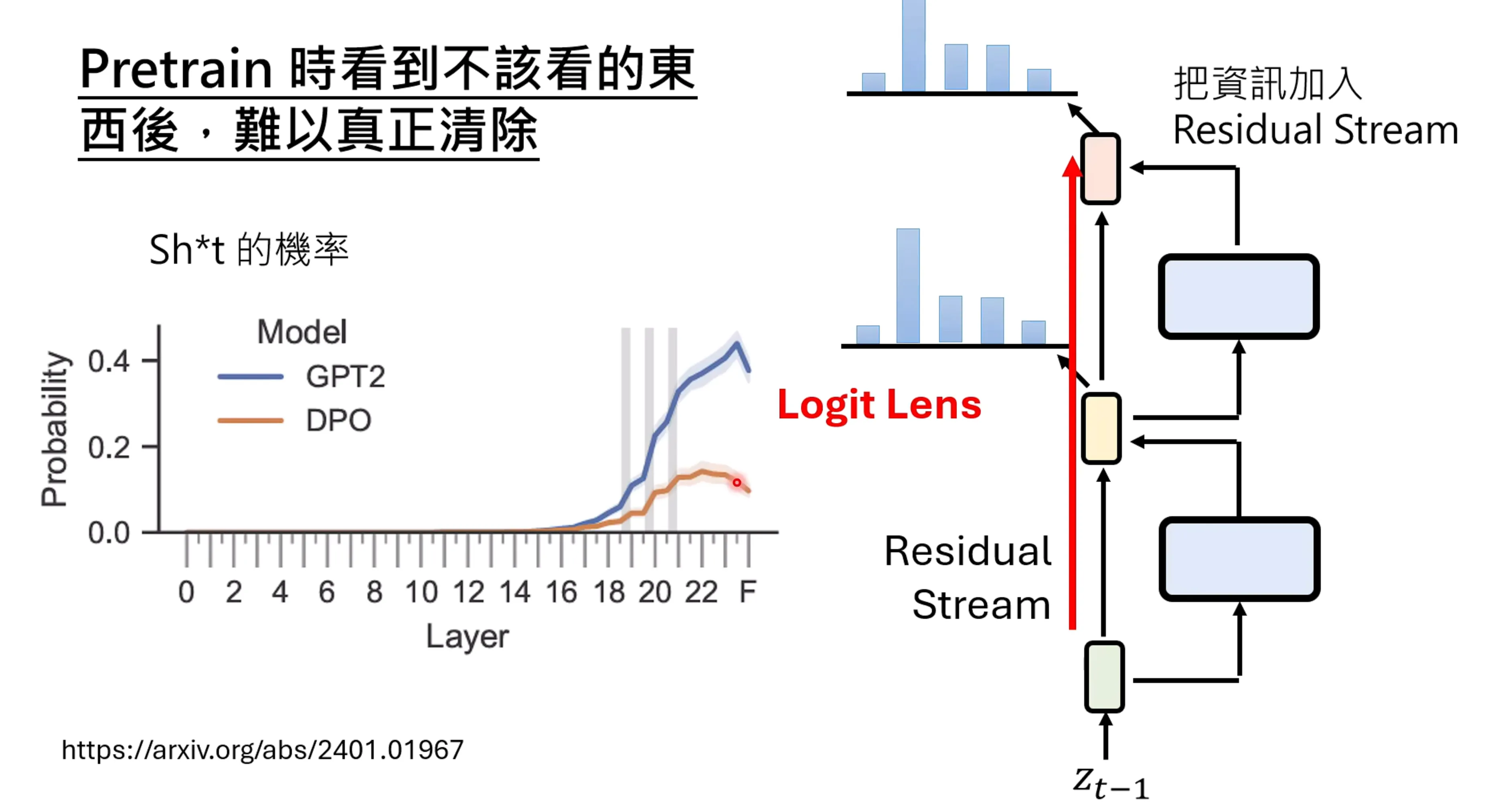
pretrain阶段看过各式各样的资料是一个关键,而pretrain-alignment是由一定的极限的,并不能学习新的技能。

生成式人工智能的后训练(Post-training)与遗忘问题#
模型的基础能力已经非常好了,但有些时候需要一个具有专长能力的模型,这里就需要post-training的方式。Alignment是post-training的一种方式,这堂课说的post-traing更加广泛,是指更广泛的概念,现有的模型加上额外的技能就是Post-training。
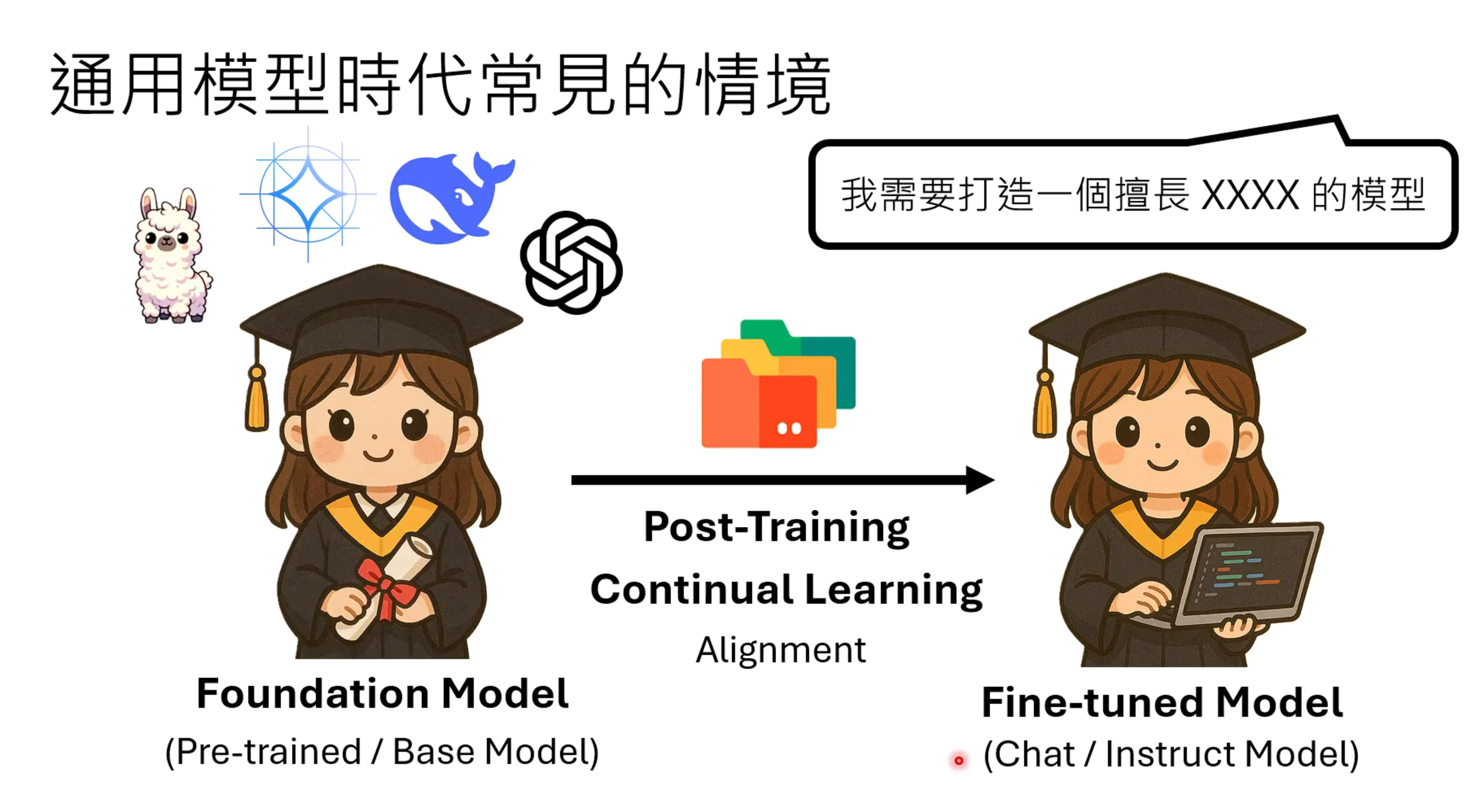
因此这个foundation model广义上讲也可以是chat或者是instruct model。
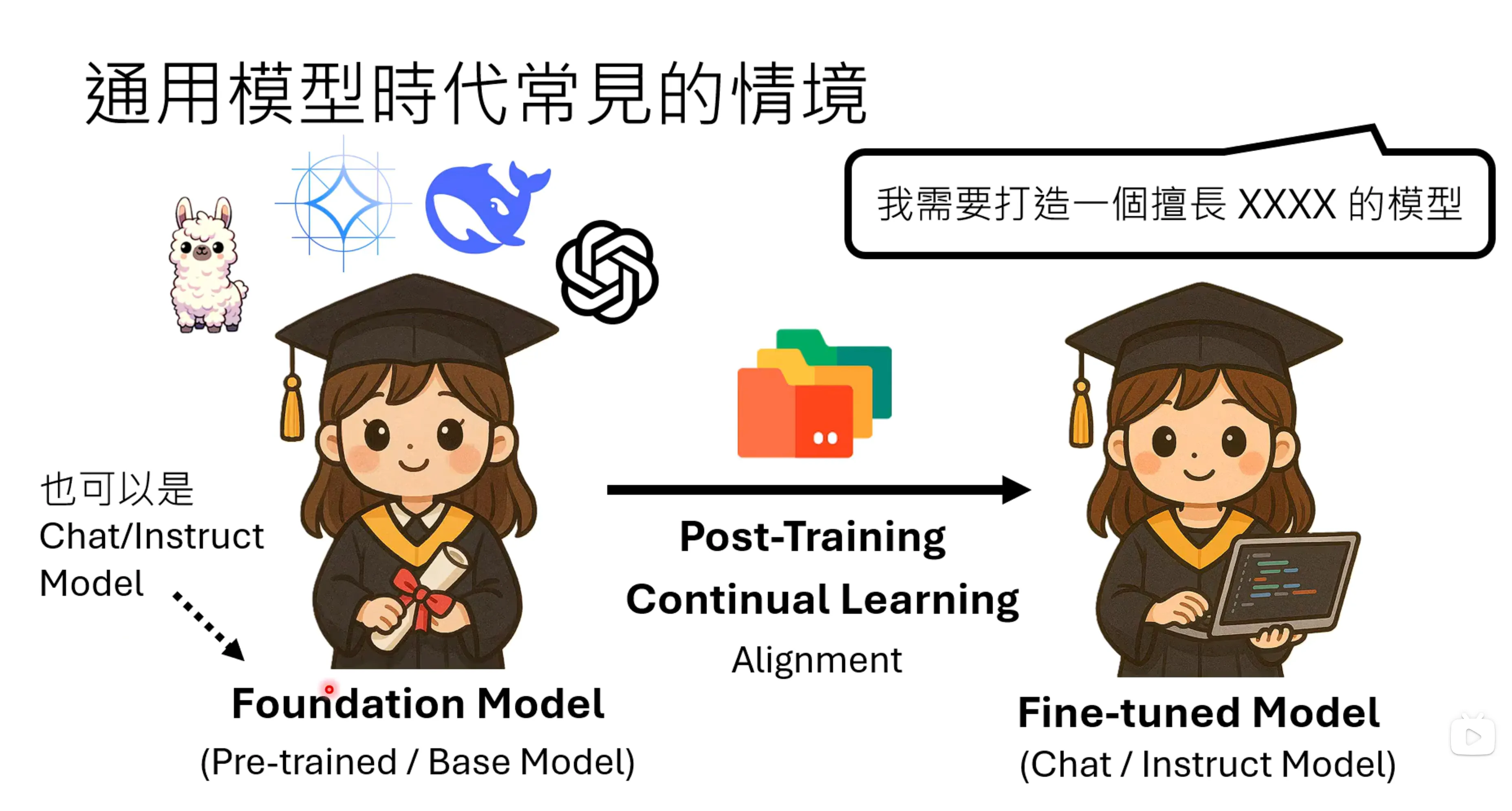
教语言模型新的能力,可以通过Pre-train Style(文字接龙的方式),或者是SFT style(一问一答的方式),又或者是RL style
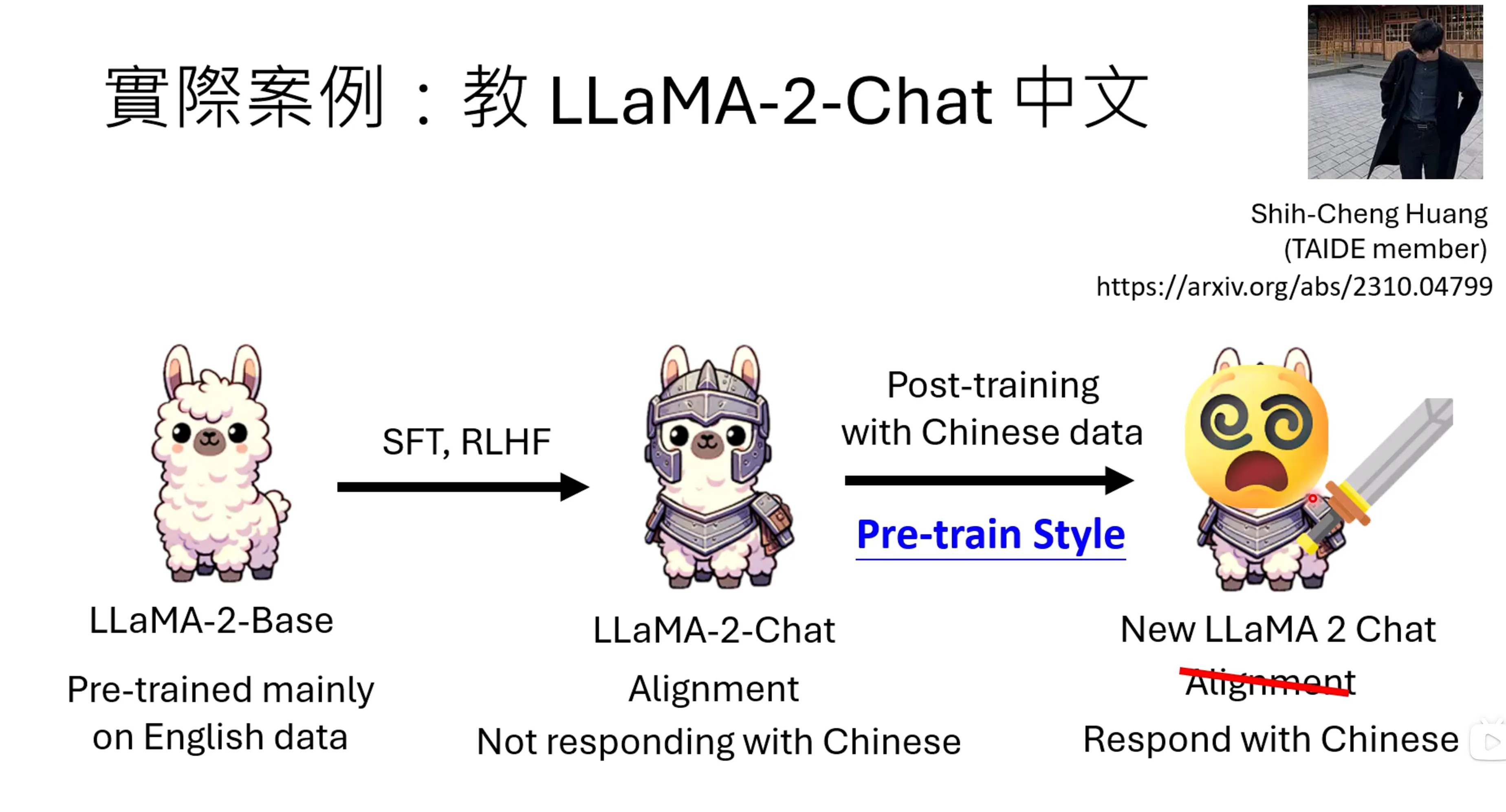
举个例子:原版的LLaMA2只能支持英文,通过pre-training的方式喂给模型中文,似乎可以让模型学到中文的信息,但是原来的Alignment会被破坏,模型会有遗忘的问题。即使做SFT模型也很容易产生遗忘。Safety alignment是最容易被破坏的能力,很容易破坏其他模型的基础能力。
如何在一个语言模型上加入基础的模态信息呢?
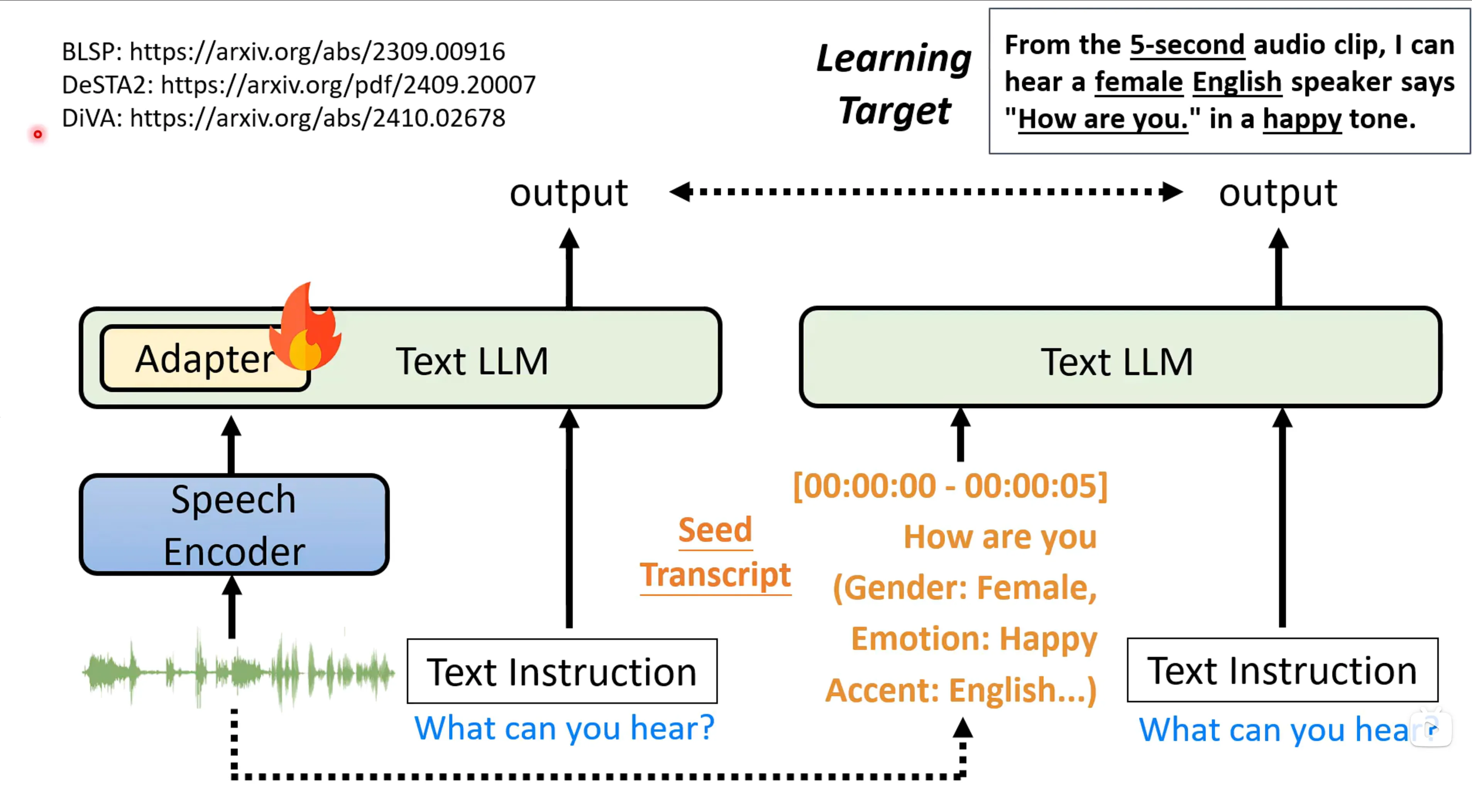
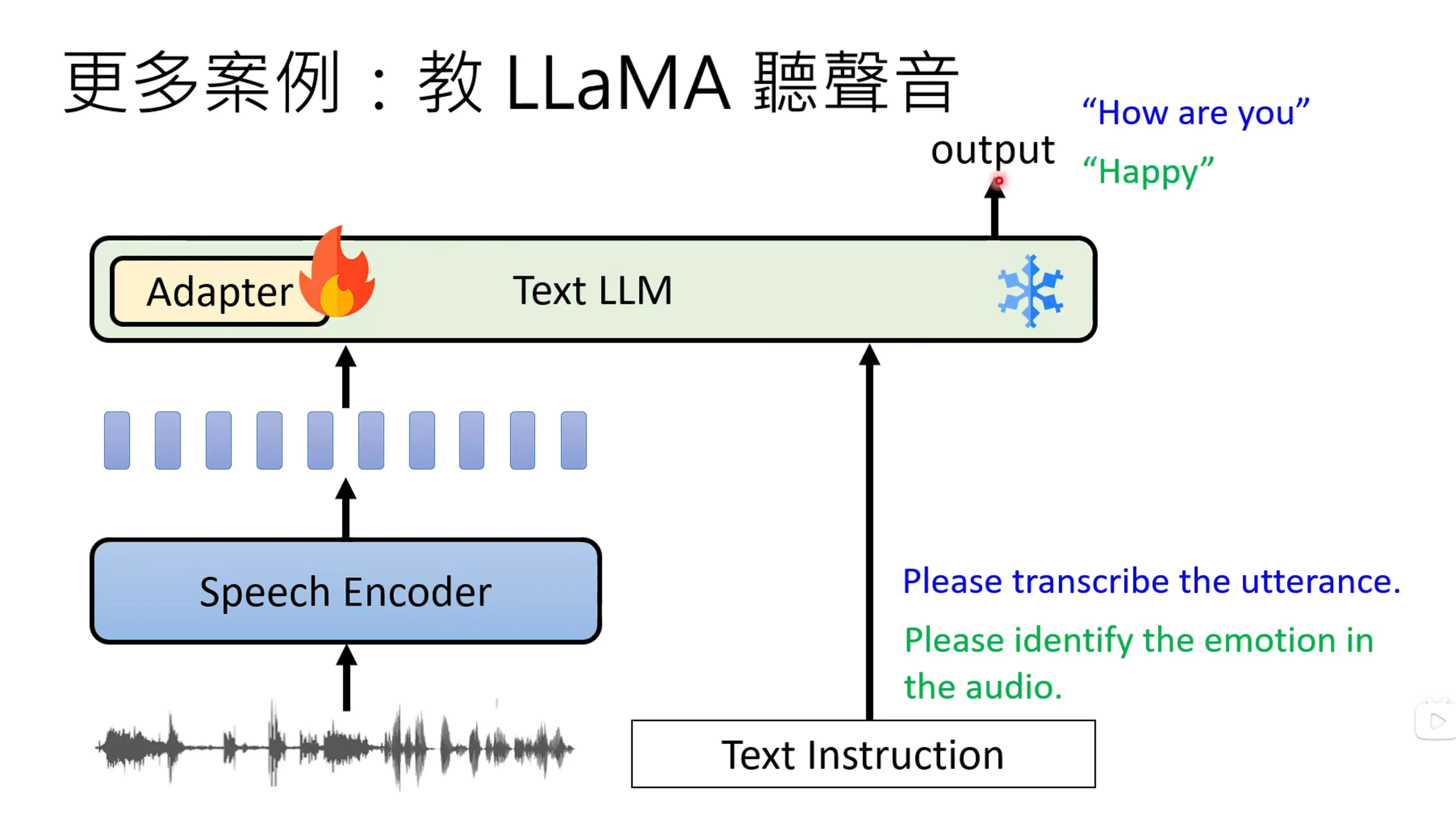 实际上需要增加一个speech的encoder,通常是0.2s编码成一个向量,因为没办法整个训练LLM,因此会加入一个Adapter来进行训练。给定多模态的信息,和文字,来进行正确答案的训练。Q:这里的Adaptor是啥。Post-training的最大的一个挑战就是可能会导致遗忘(Catastrophic Forgetting),随着专有任务的完成,原有的能力会退化或者消失。
实际上需要增加一个speech的encoder,通常是0.2s编码成一个向量,因为没办法整个训练LLM,因此会加入一个Adapter来进行训练。给定多模态的信息,和文字,来进行正确答案的训练。Q:这里的Adaptor是啥。Post-training的最大的一个挑战就是可能会导致遗忘(Catastrophic Forgetting),随着专有任务的完成,原有的能力会退化或者消失。
Forgetting的现象往往和模型的大小没什么关系,但是和目标任务上做的有多好有关系。 一般来说在目标问题上学的越好,往往模型遗忘的会越严重。
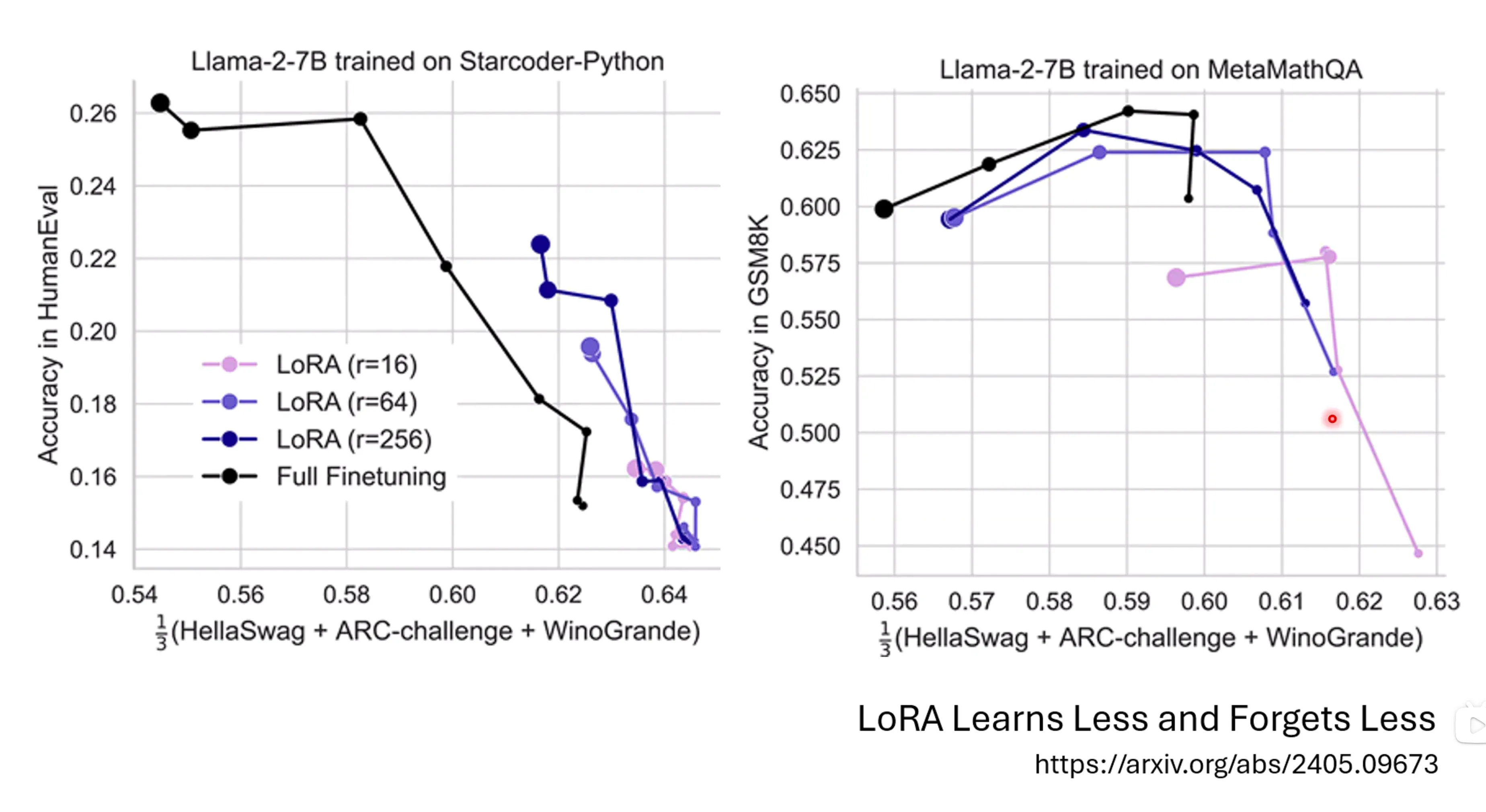 LoRA的遗忘能力似乎更小,但他也是通过牺牲起数学或者是代码能力所换来的。微调之后单一性能确实有提高,但是模型遗忘的也很严重。
LoRA的遗忘能力似乎更小,但他也是通过牺牲起数学或者是代码能力所换来的。微调之后单一性能确实有提高,但是模型遗忘的也很严重。
之前解决遗忘的方式:Experience Replay,注入之前的一点知识来唤醒之前的记忆。但对于当下的模型来说,很难获得他原始的训练数据,这样experience replay的方式就成了一个困难。但是可以让模型自问自答的去产生一些原始的训练数据(从已有的模型产生训练资料)。
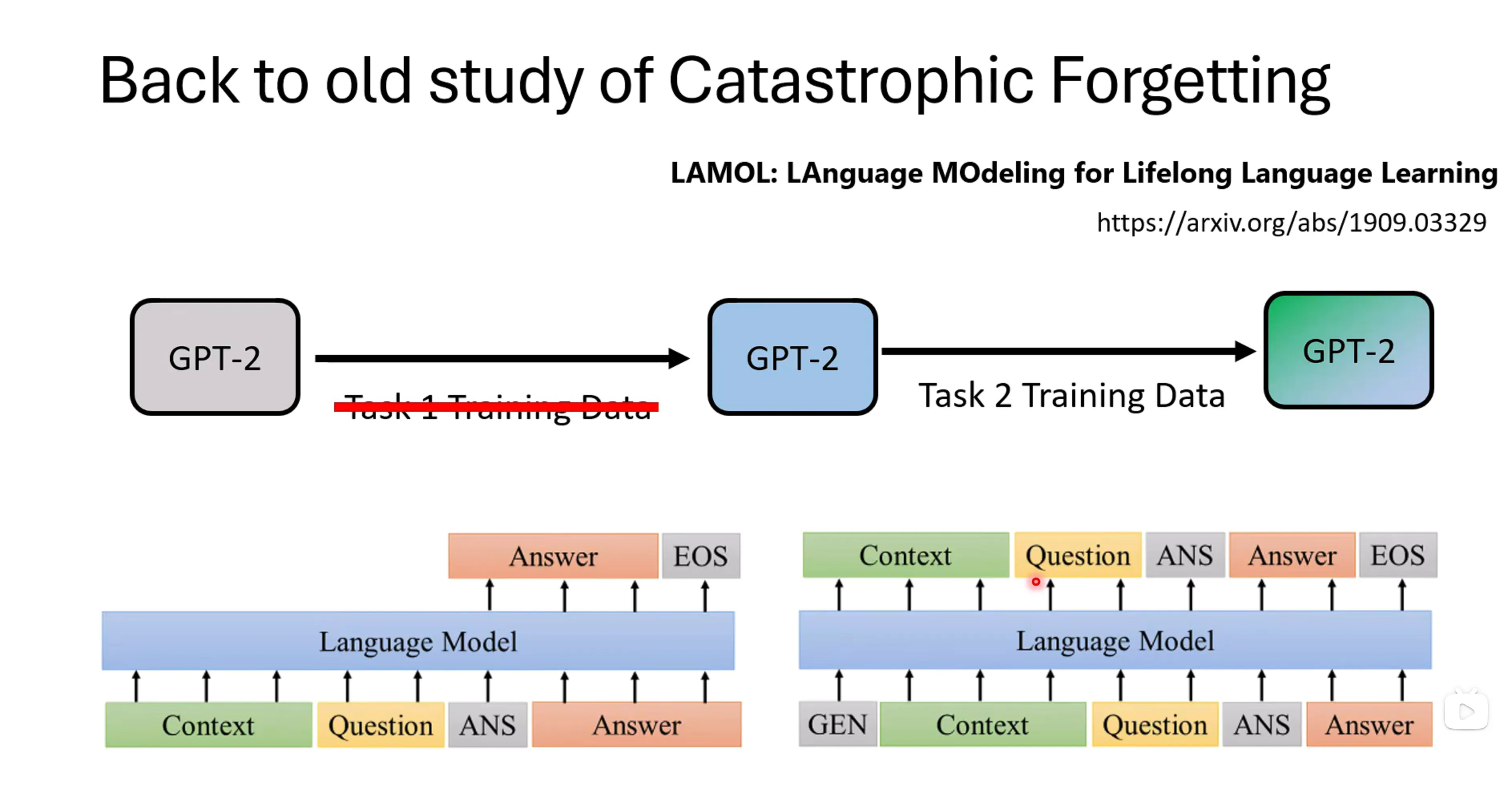 通过一个没有当下训练的GPT版本产生之前训练步骤过程中的训练数据,自说自话,可能信息都是假的。
通过一个没有当下训练的GPT版本产生之前训练步骤过程中的训练数据,自说自话,可能信息都是假的。
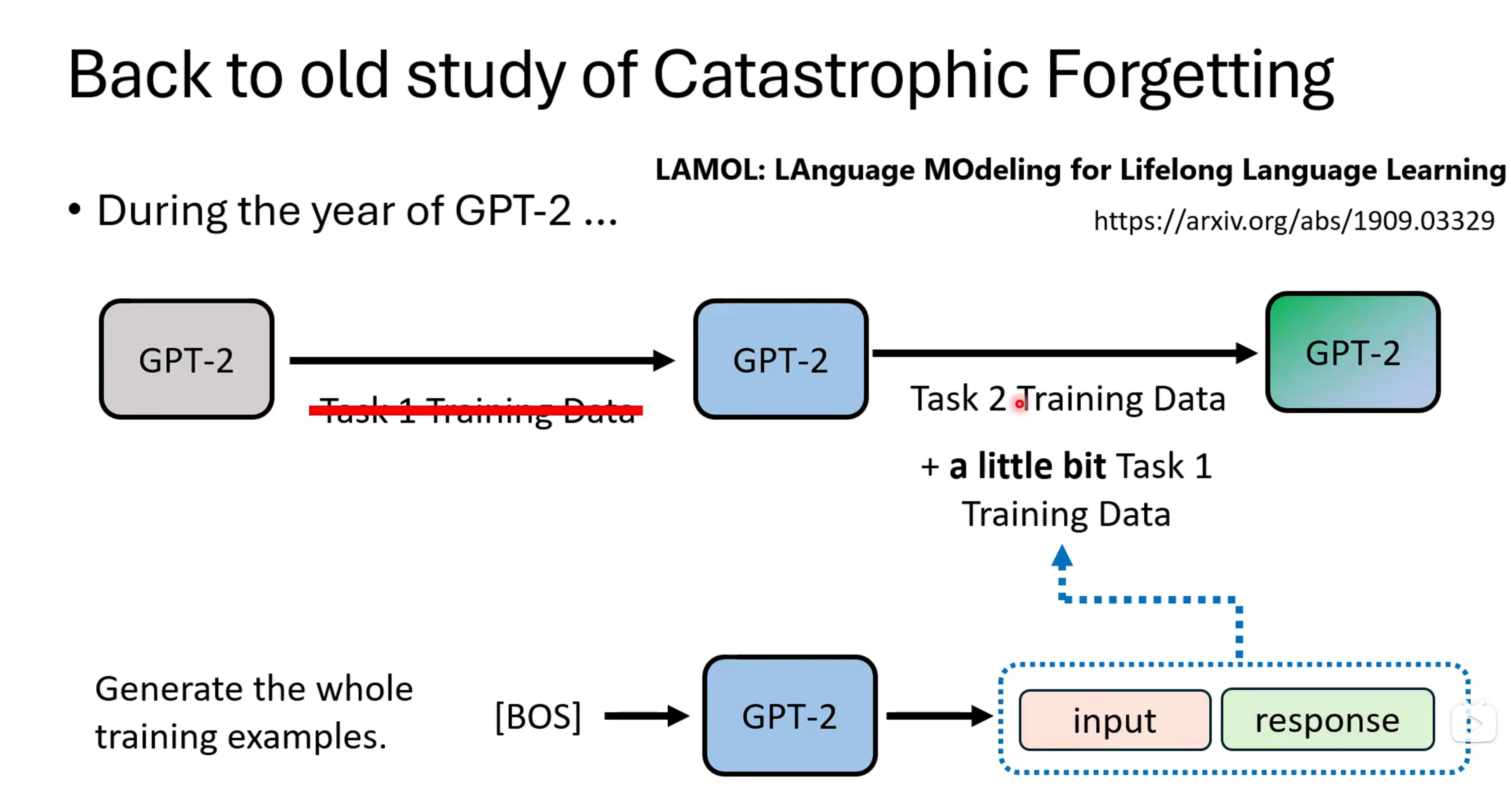
Lllam3的其中一种产生训练数据的方法:
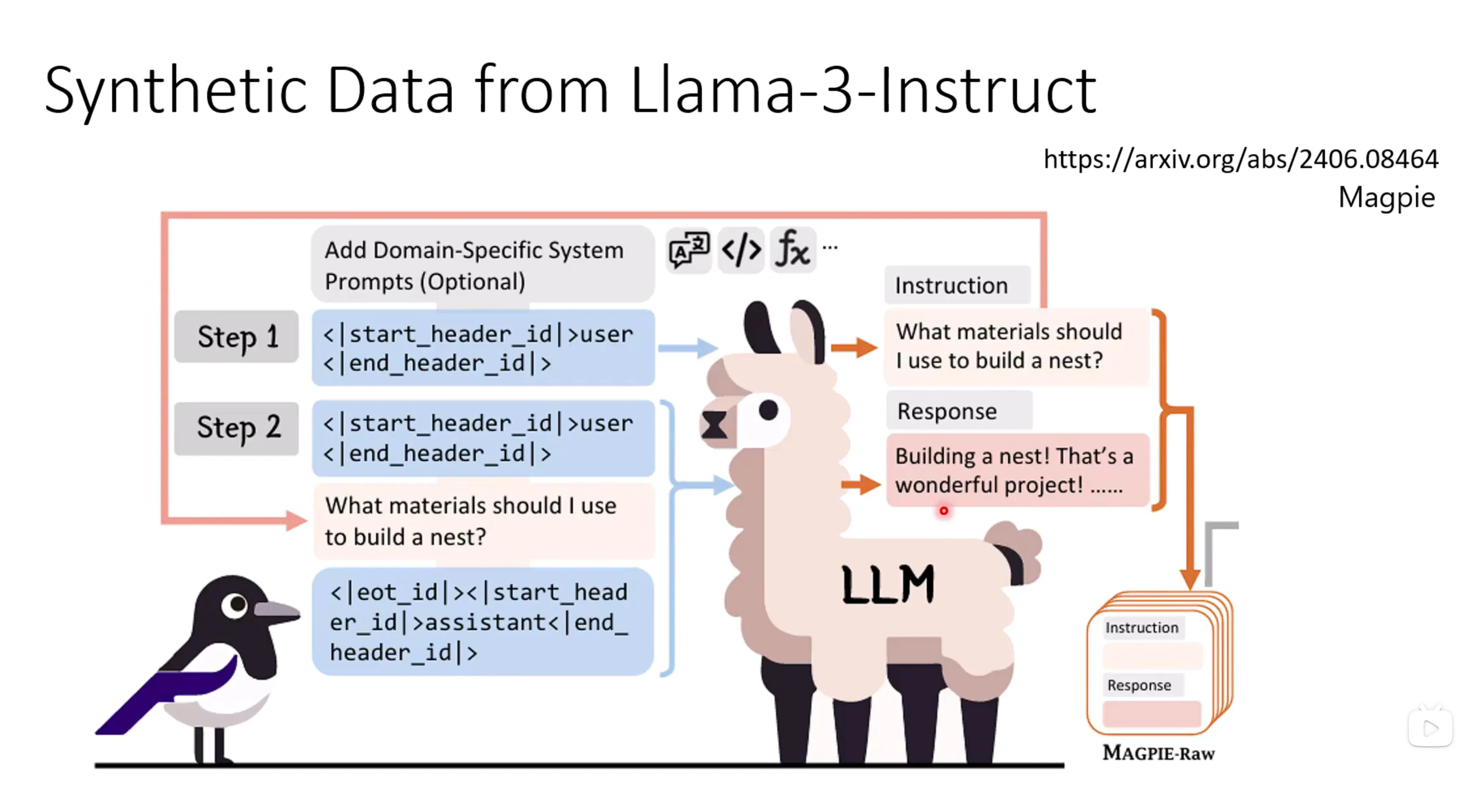
另一种方法是,在训练的时候不用人写出的正确的答案,而是用foundation model改写过后的答案作为答案,看起来就像是模型自己输出的答案了。
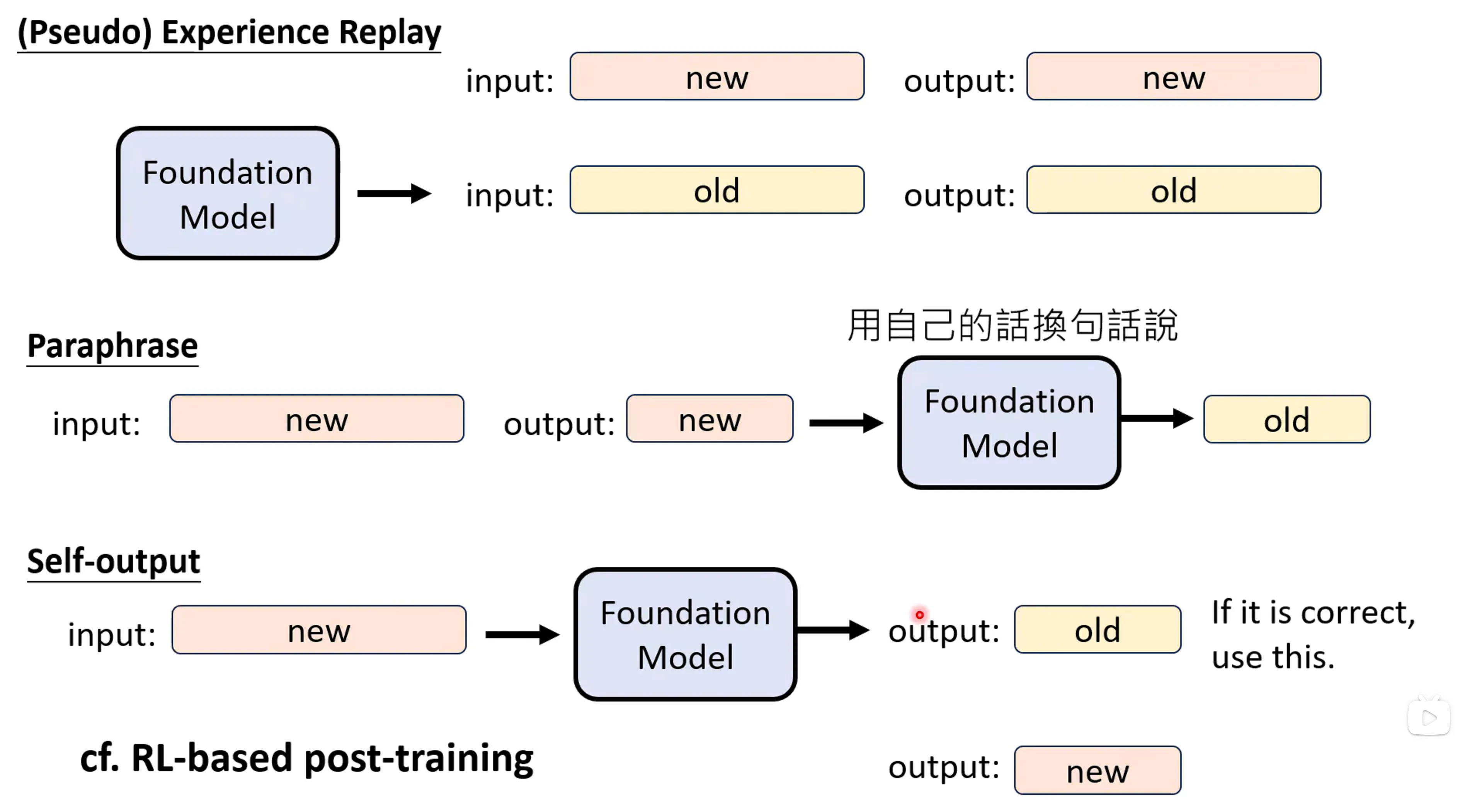
RL-based post-training和self-output很像,只不过可能self-output没有说降低几率的说法,作者认为RL-based post-training可能是一个比较好的防止遗忘的方法。另一种方法说如果用更强的Foundation Model去生成答案是否有帮助呢?有研究表明是有帮助的。用人类资料来教模型很容易让模型遗忘,反而效果更差。这种训练方式在语音上也是有效的。
感觉机器回答的方式和人回答的方式是有不一致的问题的。有方法是过滤掉一些foundation model很难产生的token,使其结果和机器给出的结果更像。

会进行深度思考的大型语言模型 DeepSeek-R1#
很多现在的大语言模型都有深度思考行为,比如ChatGPT o1/o3/04、DeepSeek r1、 Gemini2 Flash Thinking、Claude3.7 Sonnet(Extended Thinking)
深度思考模型会先有一个思考过程,在给出答案,会包含验证过程,做探索,以及开始规划。这个思考过程也通常被叫做推理(Reasoning),Inference 翻译为推论,但这两者完全不一样,使用这个模型做前向传递就是inference,而reasoning是指在产生答案的过程中有比较长的思考行为。
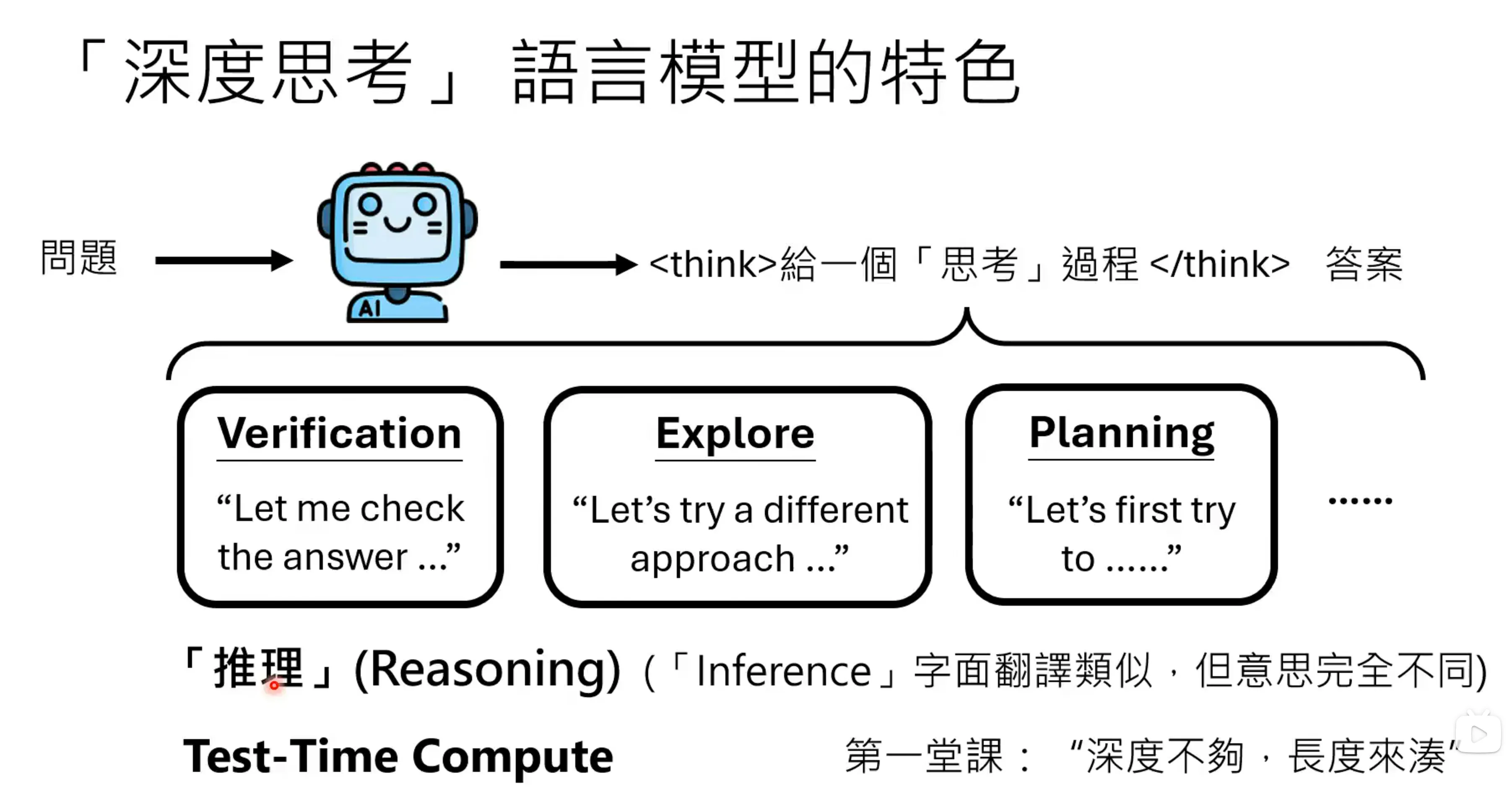
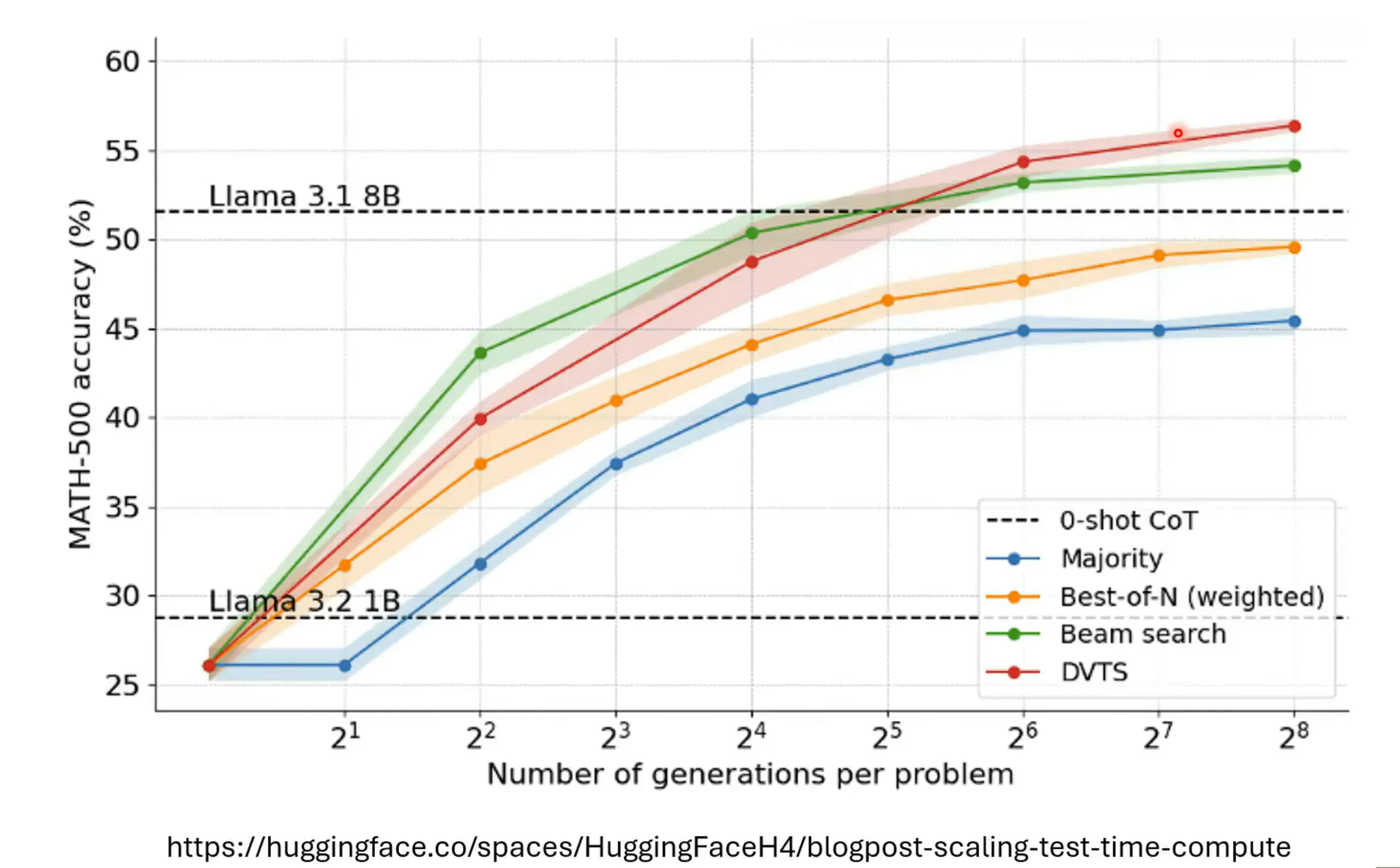
Test-time Scaling,思考越多结果越好,之前会把更多的时间放在蒙特卡洛research上,即给出更多的思考时间。Test-time compute 可以用更少的计算资源换取相同的结果,从而减少训练过程中的计算资源。
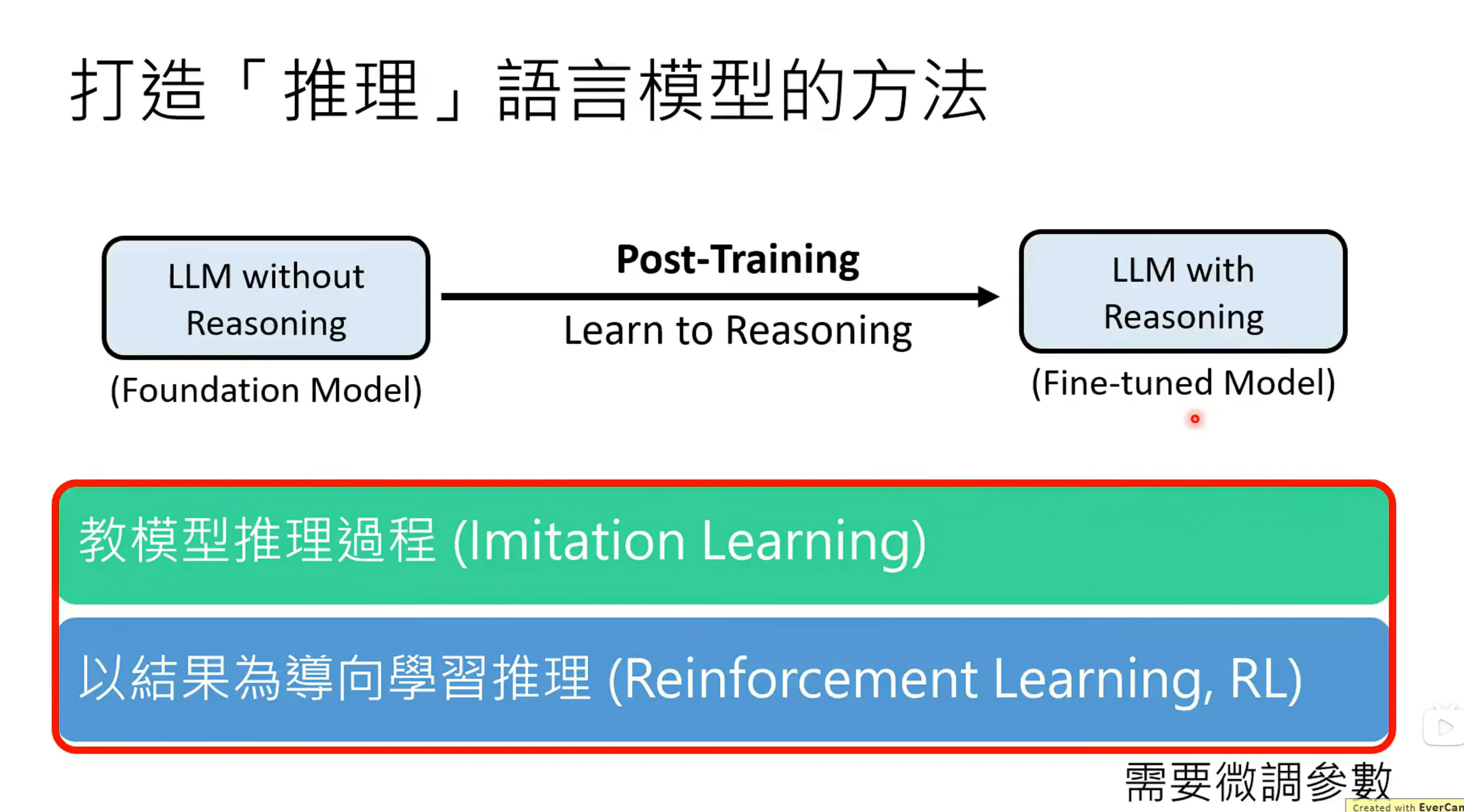
打造推理语言模型的方法,前两种不需要微调参数。

Chain-of-Though (CoT)#
22年最早被提出,最开始通过给定上下文的语言范例来进行输出,后面有zero-shot CoT方法,直接说Let‘s think step by step。 现在的叫Long CoT
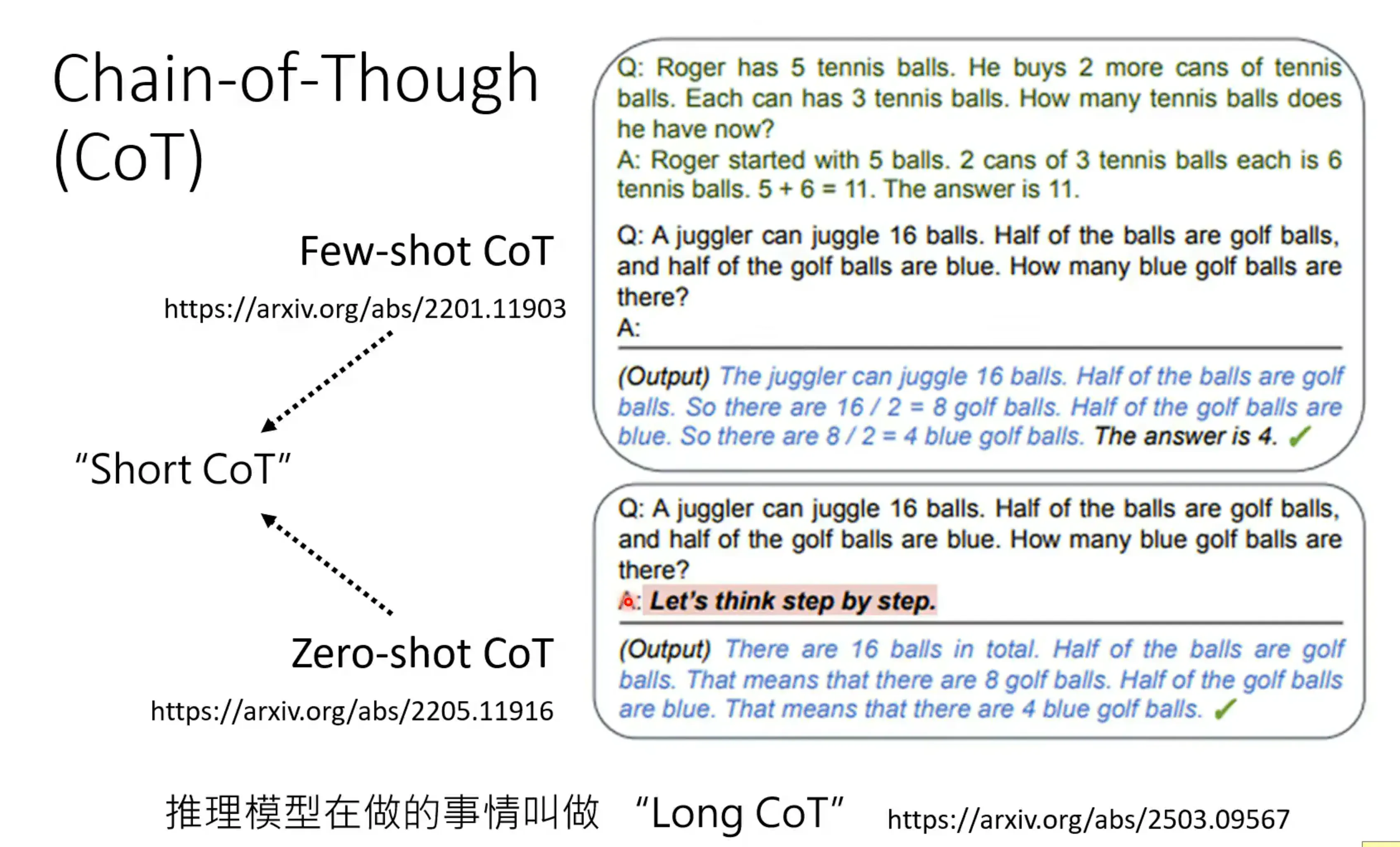
也有一种方式叫supervised CoT,通过人为的给定思考的过程,让模型去按步骤拆解,但不是所有的模型都有能力根据复杂指令做Long CoT,比如说Lamma3就不行:
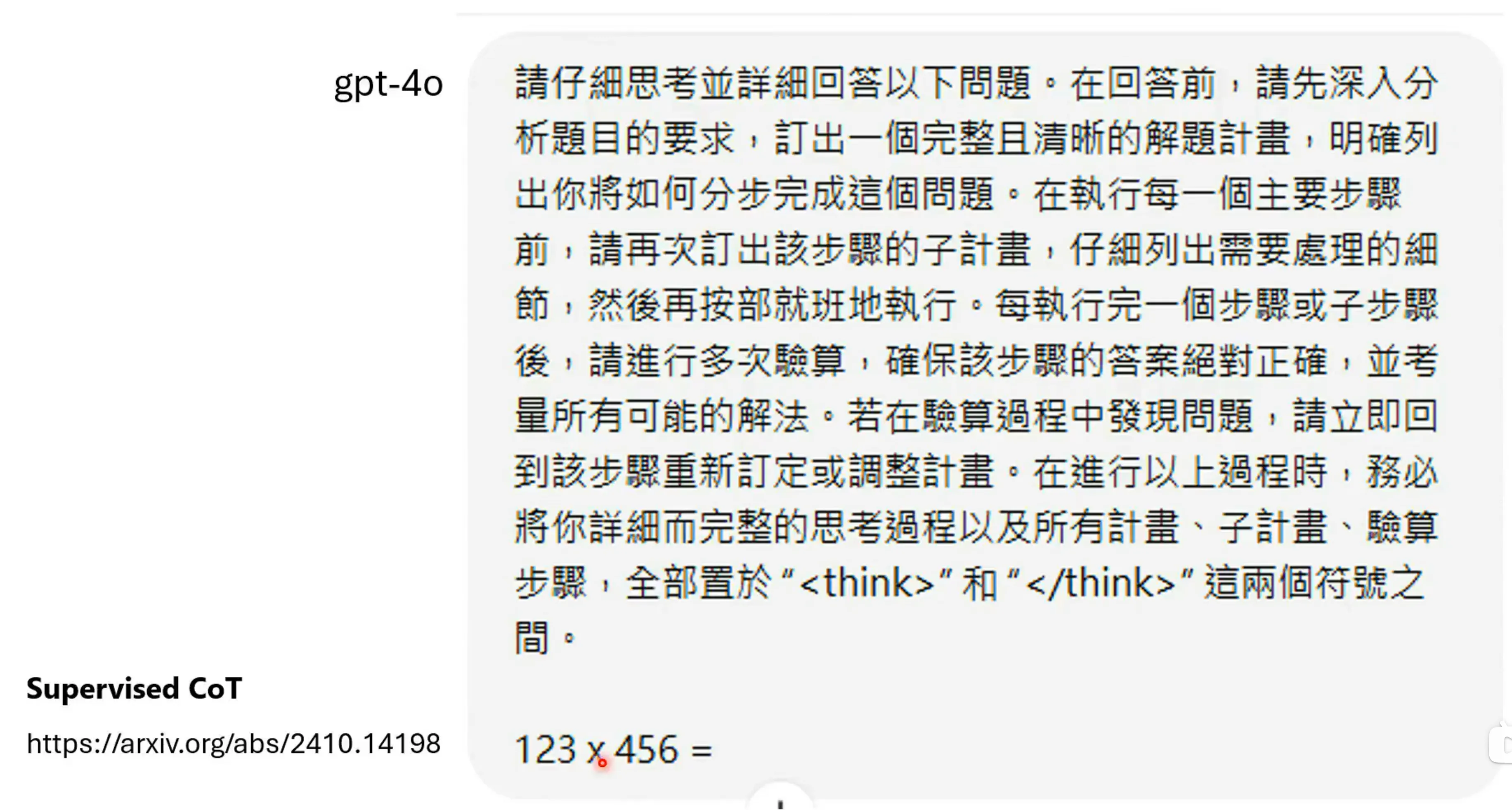
直接给模型推理的工作流程#
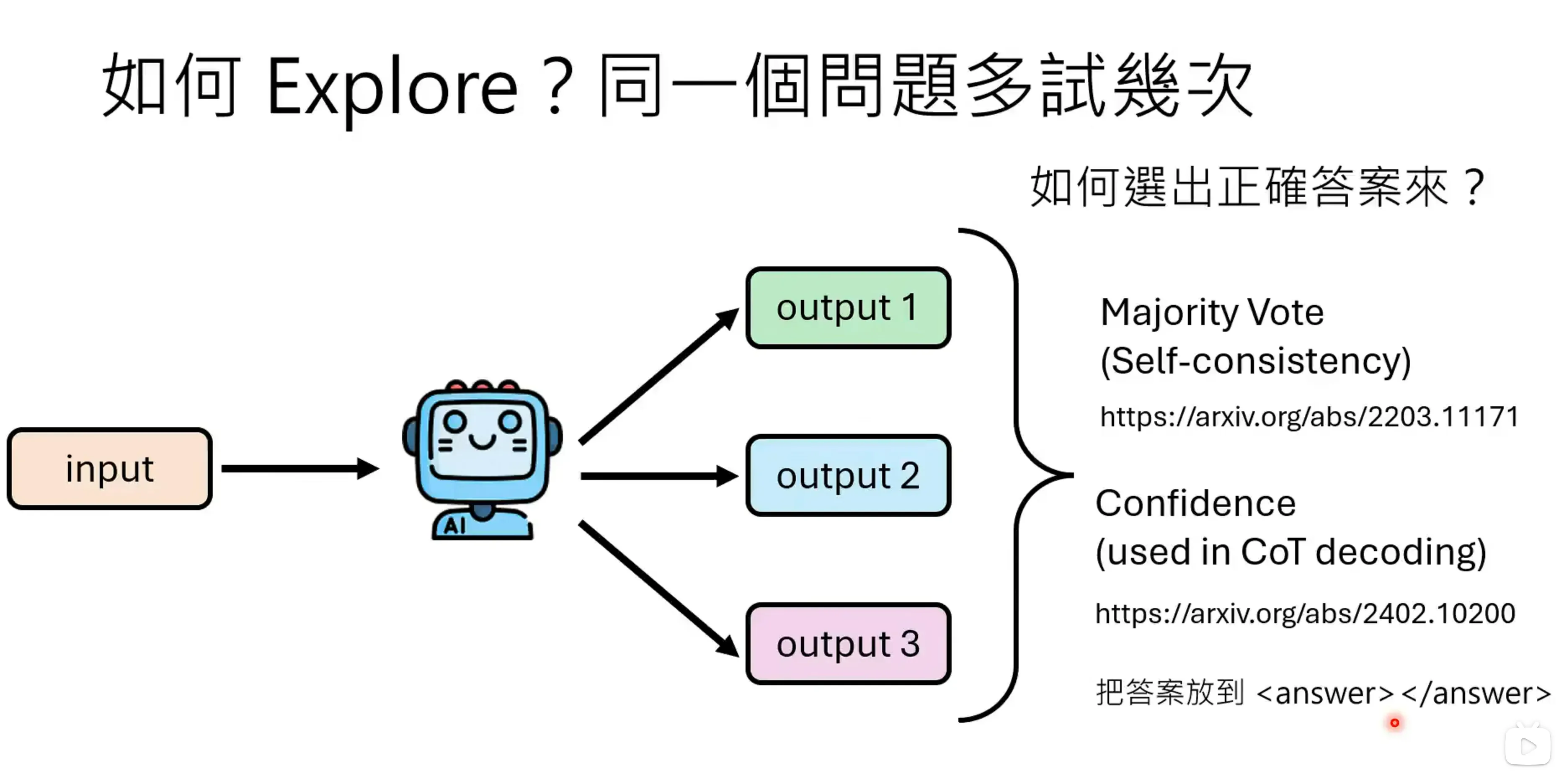
通过让模型多次回答一个问题,模型总是能给出正确的答案的,通过voting或者confidence的方法可以对输出的多个答案进行选择。Majority Vote。
另一个方法是引入一个verfication,这个也可以也是一个语言模型,用于对输出的结果进行验证,从N个可能的答案中选择最好的。
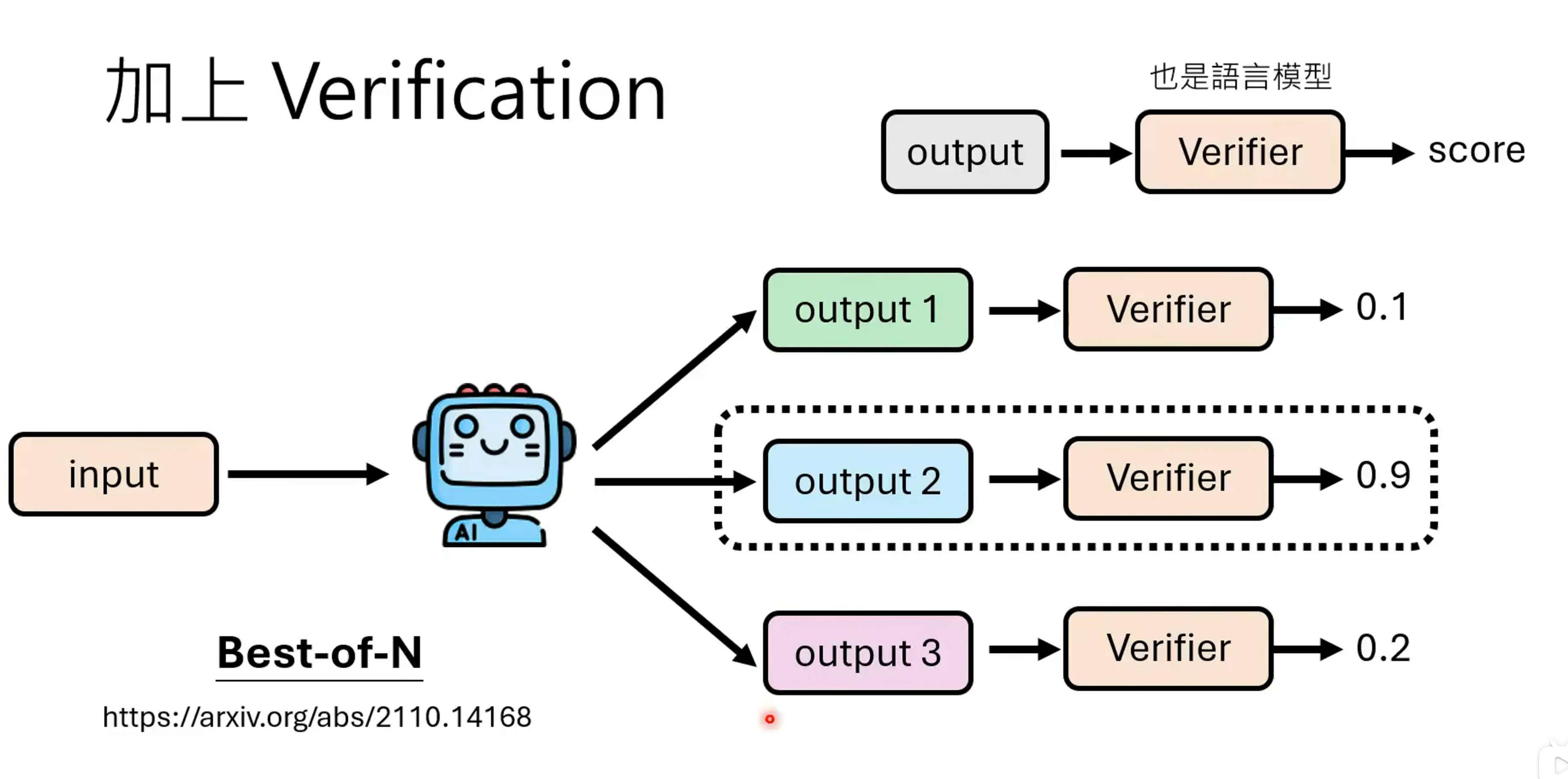 可以通过给定data 和ground truth来训练一个判别器。
可以通过给定data 和ground truth来训练一个判别器。
还有另一类的Sequential方法,让模型输出一次结果,再将结果输入得到第二次的结果,在循环的去得到下面的过程:
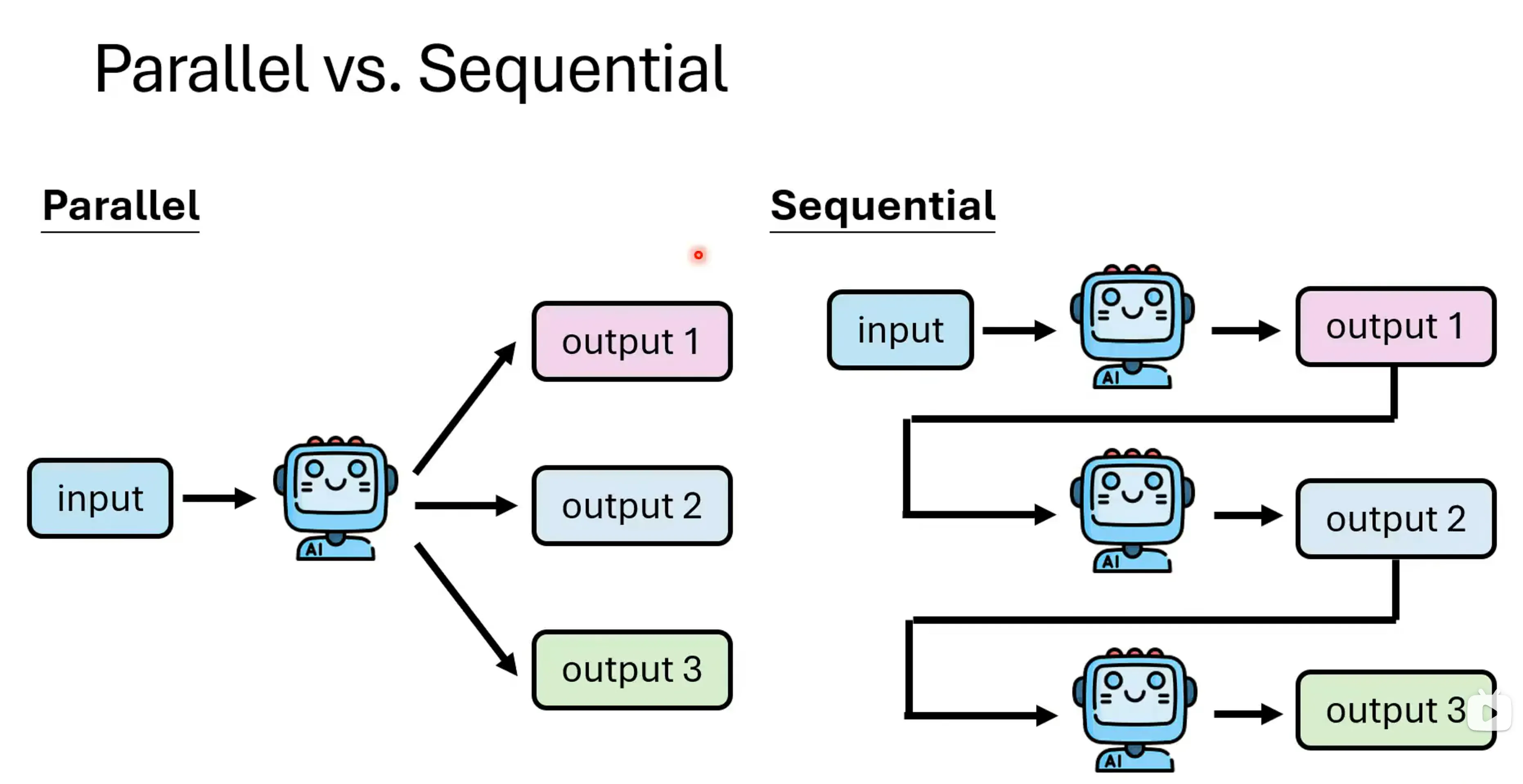 也可以将Parallel和Sequential混用
也可以将Parallel和Sequential混用
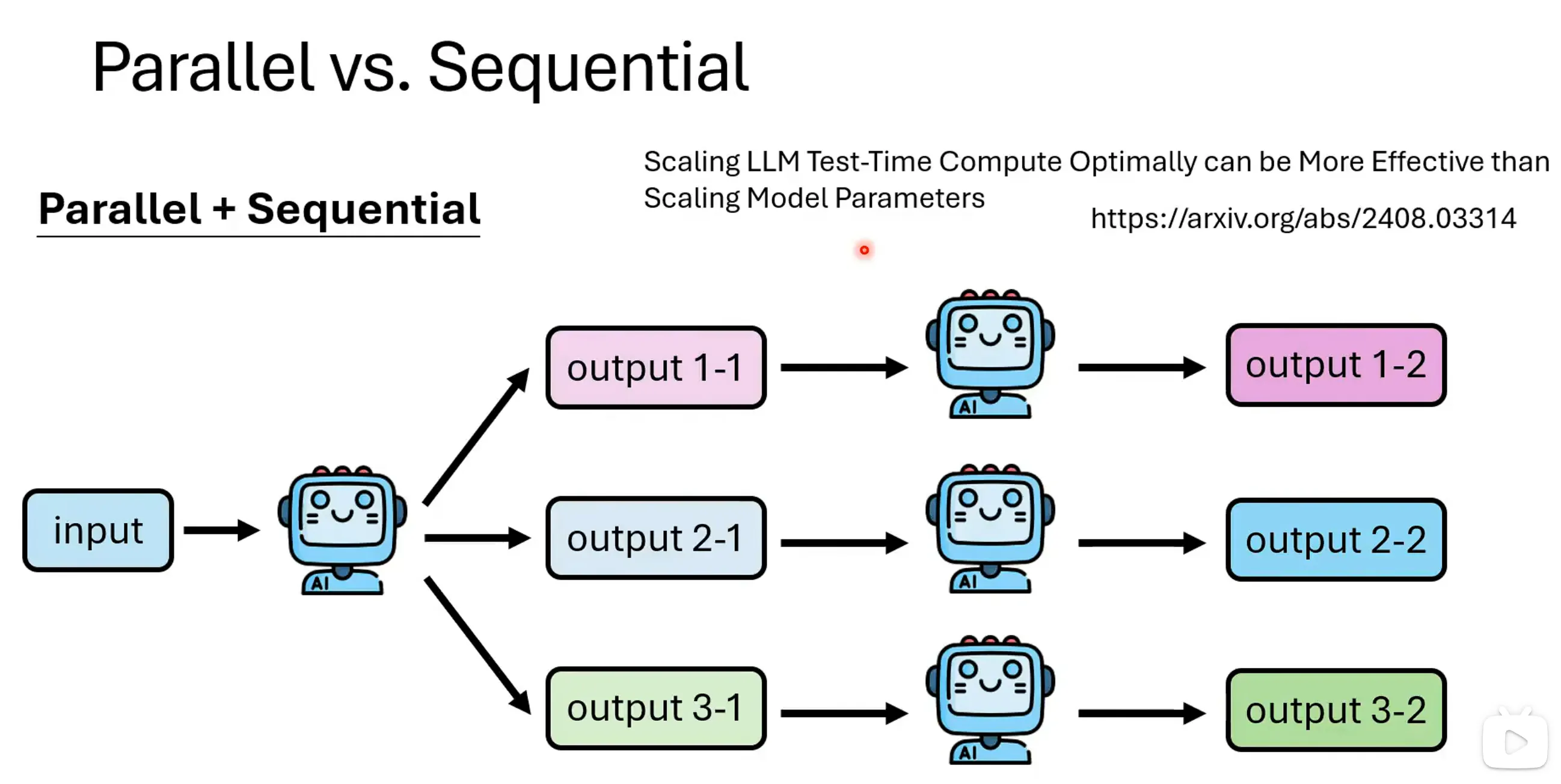
现在的深度思考模型,往往在中间的步骤就会进行验证,因此如果能对整个过程分成多个步骤,对每个步骤进行验证,在利用Parallel的方式似乎是一种解法:
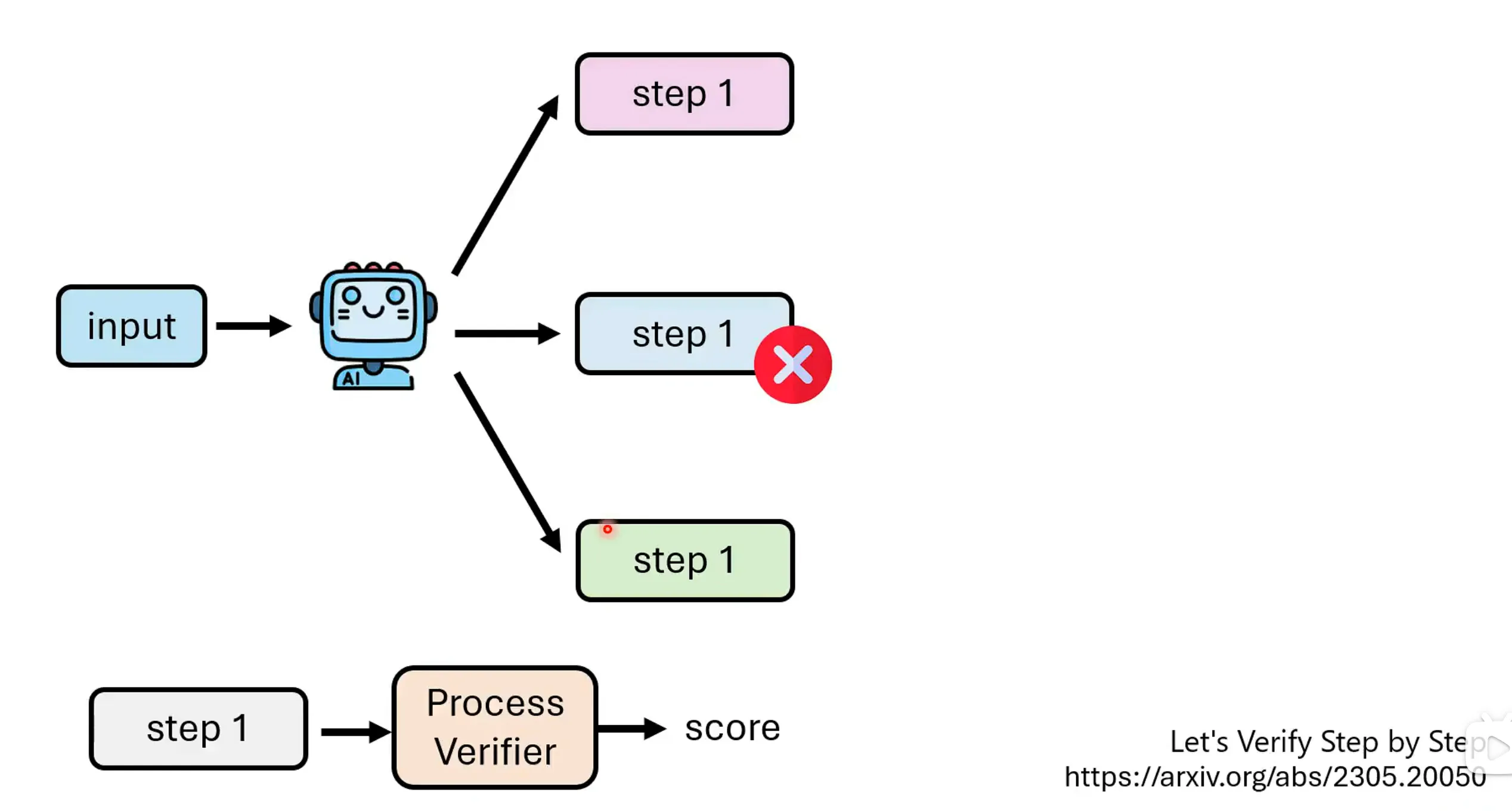 让语言模型逐步解决数学问题,每一个步骤的开头输出 <step> , 结尾输出</step>, 通过判断结尾的</step>输出,来终止后续步骤的生成。
让语言模型逐步解决数学问题,每一个步骤的开头输出 <step> , 结尾输出</step>, 通过判断结尾的</step>输出,来终止后续步骤的生成。
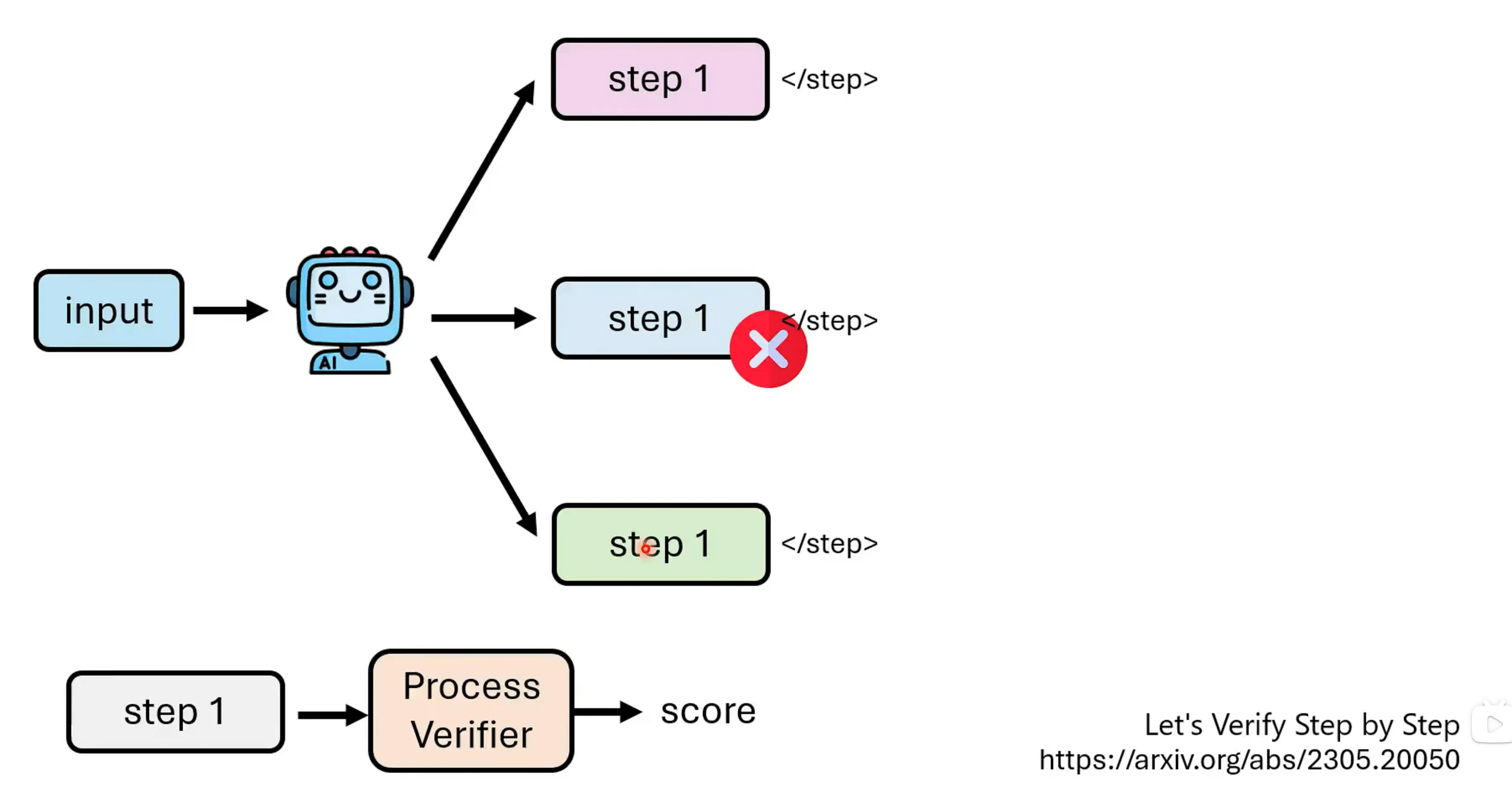 如何得到process verifier,由于我们有正确的答案,每次都解完,对于每个步骤多次的sample,都从第一步解起,统计得到正确答案的几率。
如何得到process verifier,由于我们有正确的答案,每次都解完,对于每个步骤多次的sample,都从第一步解起,统计得到正确答案的几率。
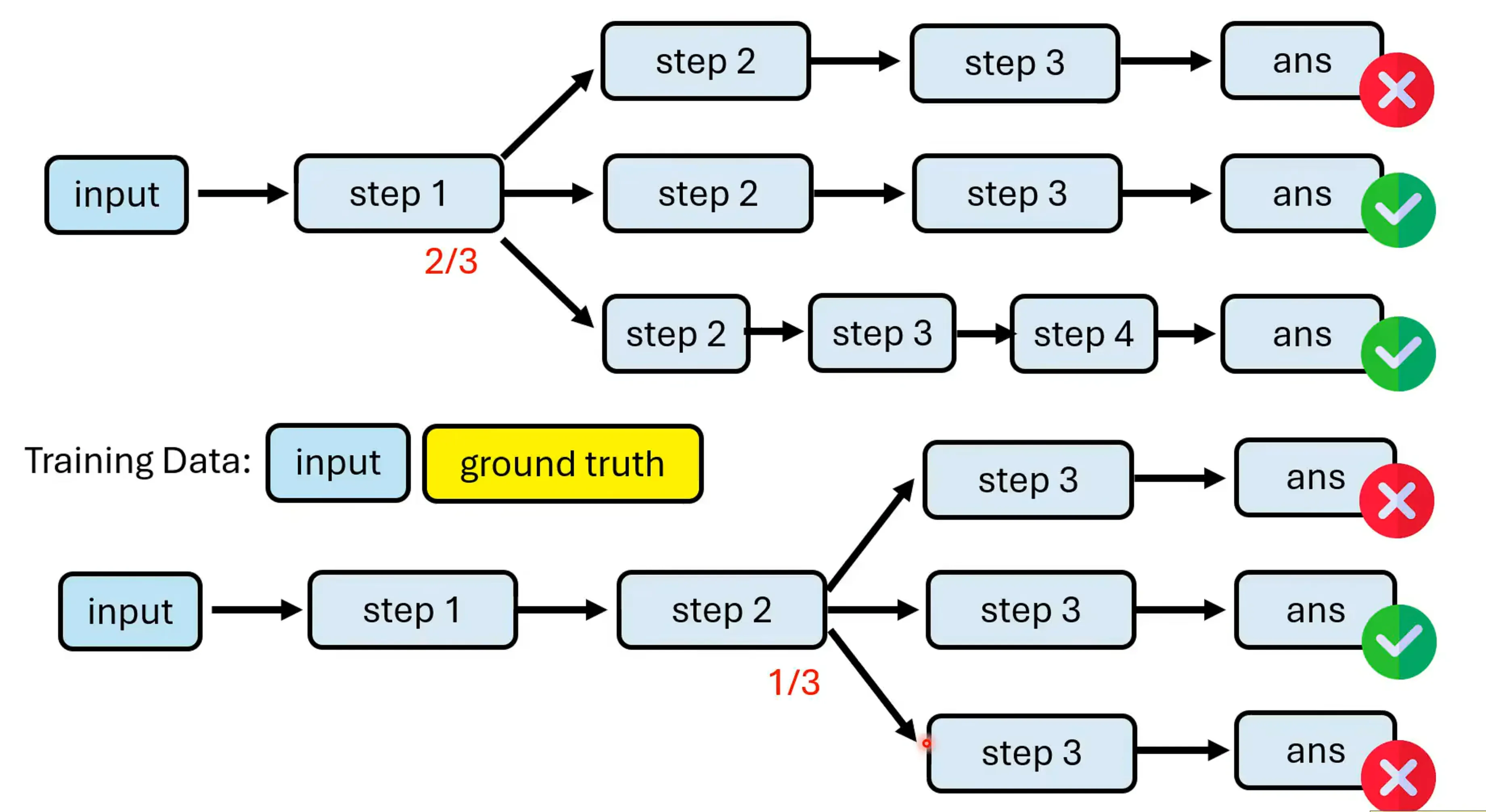
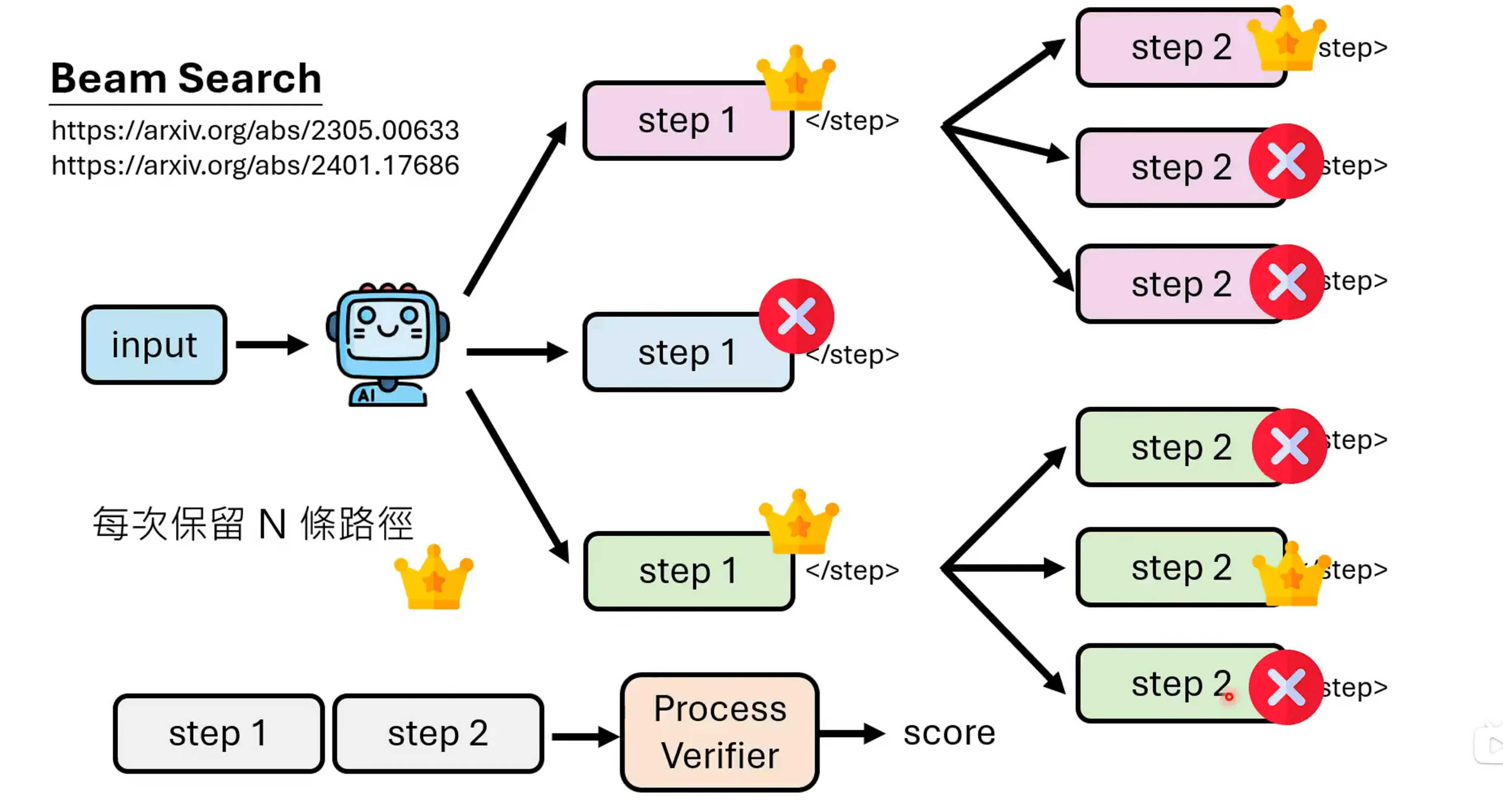
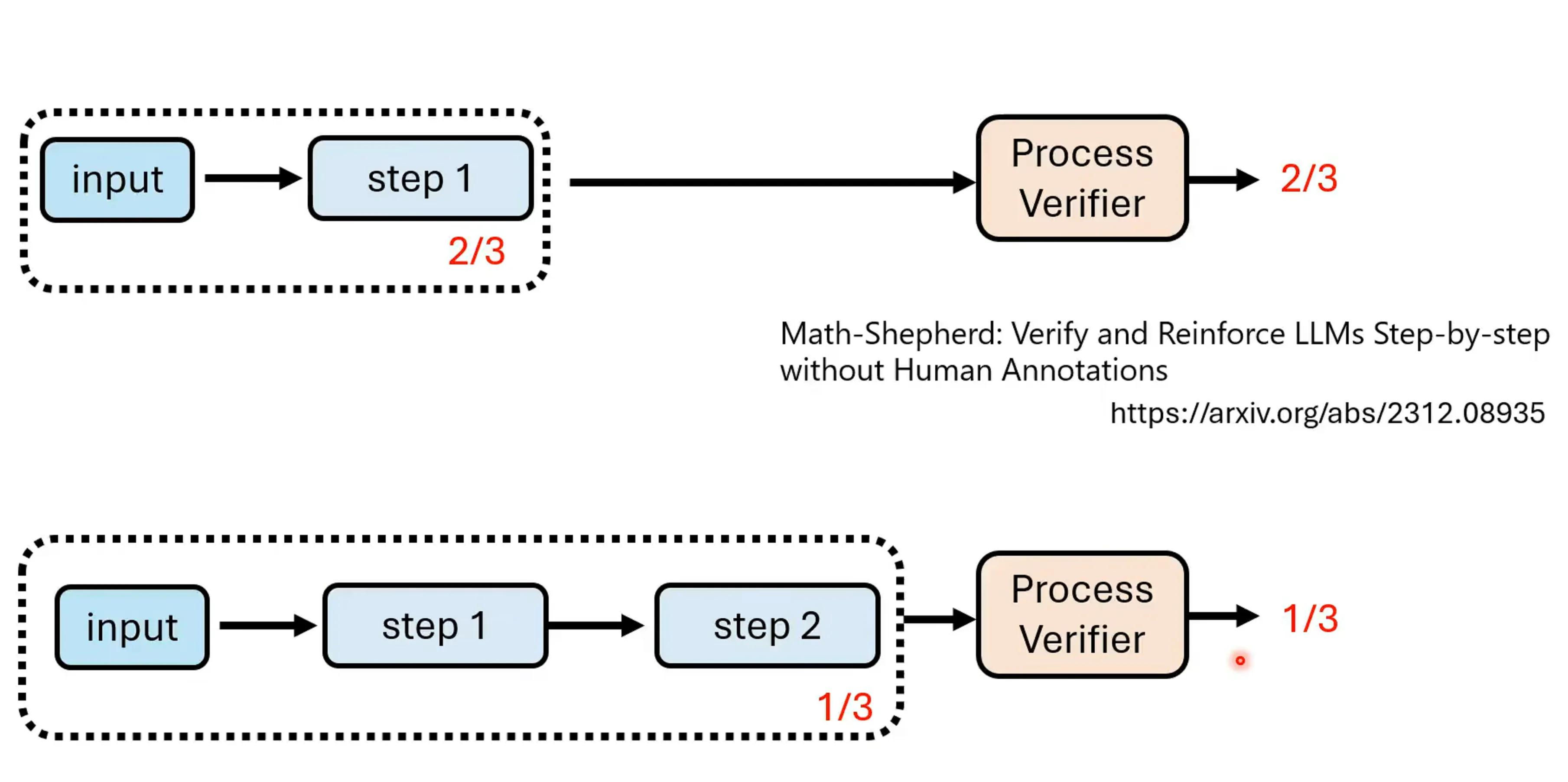 通常Process Verifier给出的是一个数值,有多条路径的情况下如何选择后续的路径,正确的可能性高于多少才进行选择呢?可以采用Beam Search的做法,每次可能保留N条最好的路径,把剩下的路径去掉。
通常Process Verifier给出的是一个数值,有多条路径的情况下如何选择后续的路径,正确的可能性高于多少才进行选择呢?可以采用Beam Search的做法,每次可能保留N条最好的路径,把剩下的路径去掉。
教模型推理的方法#
后面的这两个方法涉及到微调模型,有点像是上一接所讲的后训练过程,让没有reasoning能力的fundation model通过后训练变为具有Reasoning能力的LLM model(Fine-tuned)
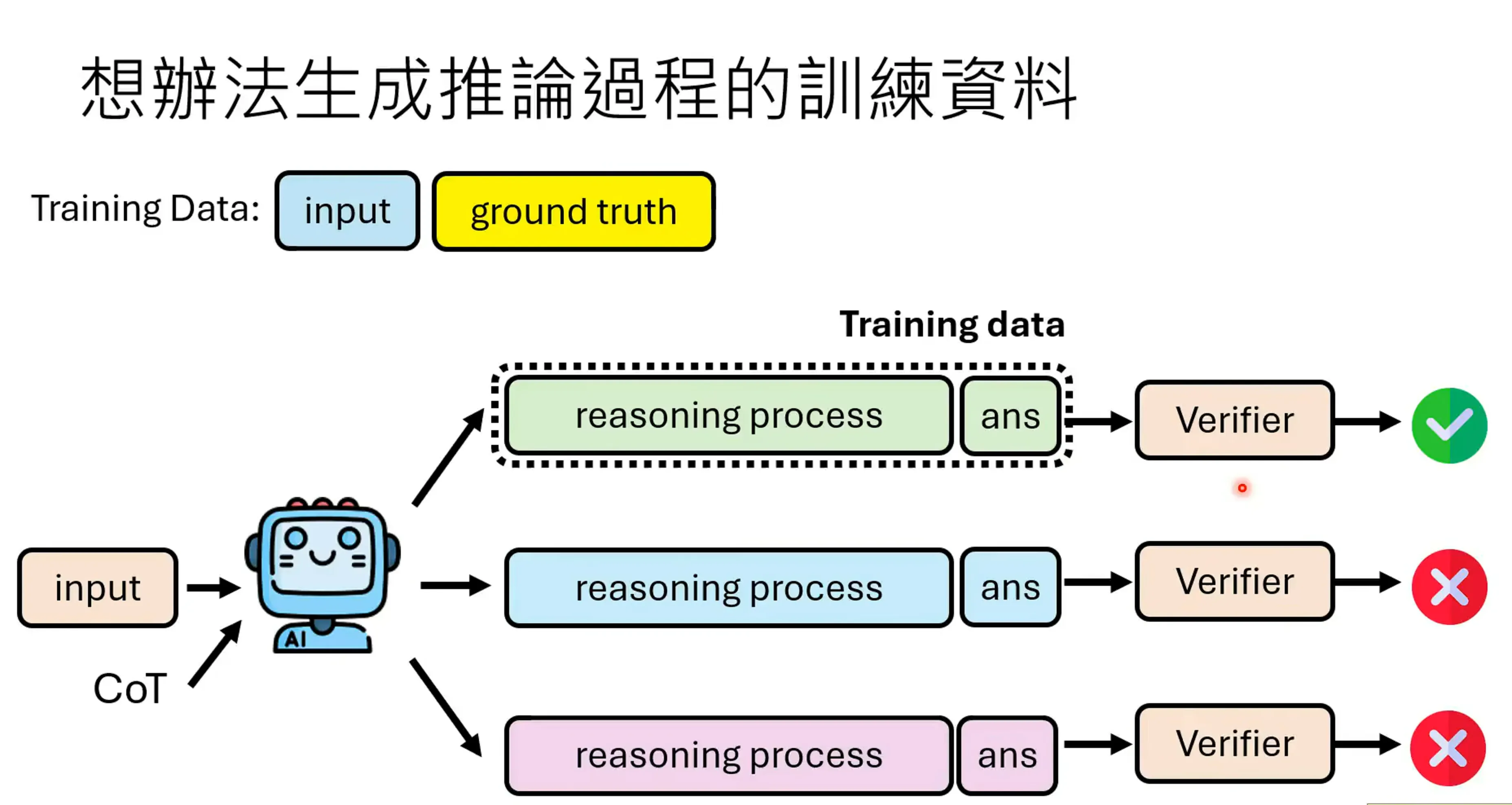
第一个方法是模仿学习,Lmitation Learning,模仿老师的行为。假设我们的训练资料不光有input 和groundtruth还有推理的过程。让模型也产生推论的过程。reasoning process的生成是个问题,用语言模型去生成resoning process 并生成ans,我们在其中再去选择正确的answer。对于有些问题可能比较难验证其是否正确,因此用一个verifier去验证也是一个比较好的方式(其他语言模型)。但我们没办法保证答案是对的,但是中间过程也是对的。
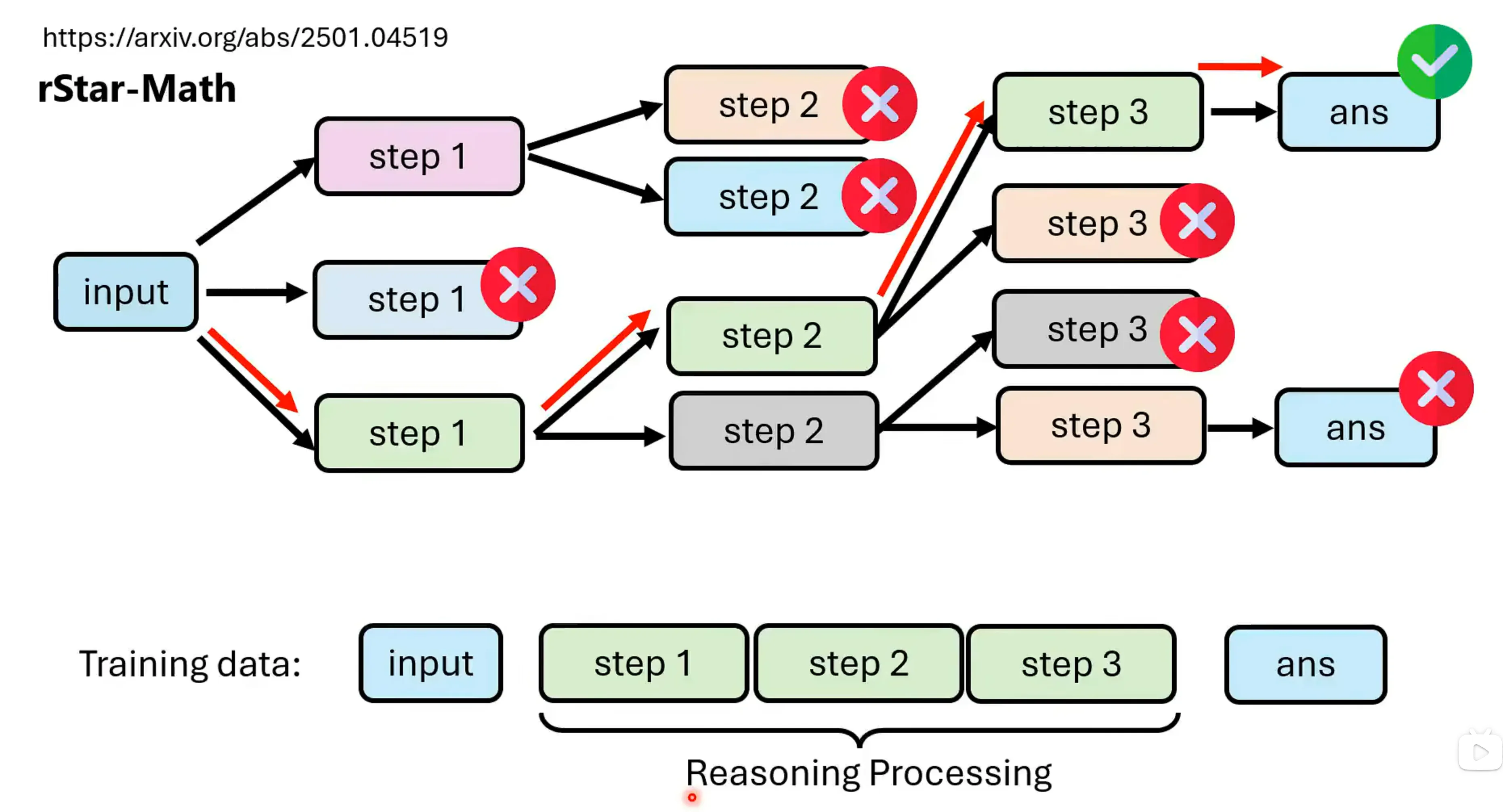
 因此有人也想出来用之前的树搜索,在结合每一步验证的方式去做中间思考过程的生成。其实这也是一种supervised learning的方式,但是实际上lmitation learning除了supervised learning的方式之外还有reforcement learning,所以步直接将模仿学习称为有监督学习。用类似DPO相关的做法。
因此有人也想出来用之前的树搜索,在结合每一步验证的方式去做中间思考过程的生成。其实这也是一种supervised learning的方式,但是实际上lmitation learning除了supervised learning的方式之外还有reforcement learning,所以步直接将模仿学习称为有监督学习。用类似DPO相关的做法。
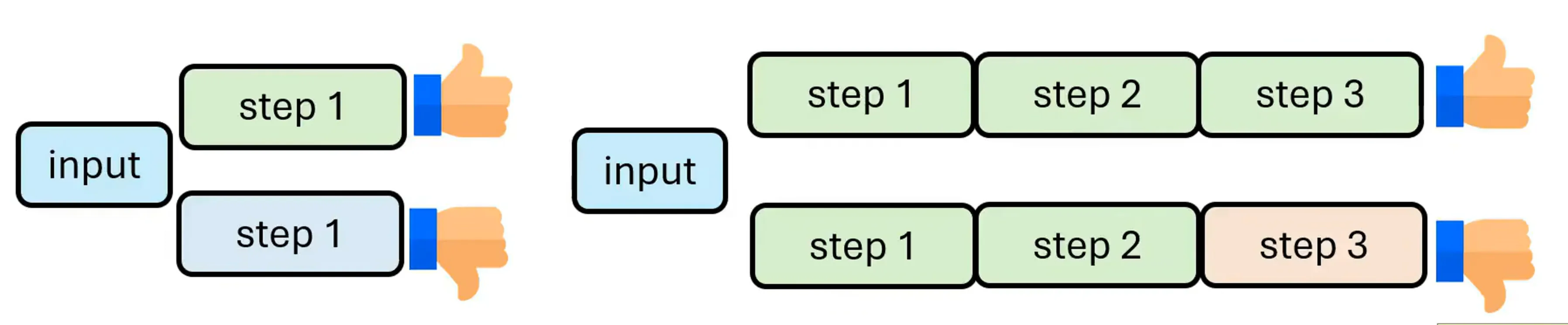
我们希望推理的过程每一步都是对的,但是推理过程真的需要每一步都是对的吗?只要他最终结果是对的,如果他能自己改正中间结果,这也是极好的。如果推论过程都是对的,他会不知道找自己的问题。
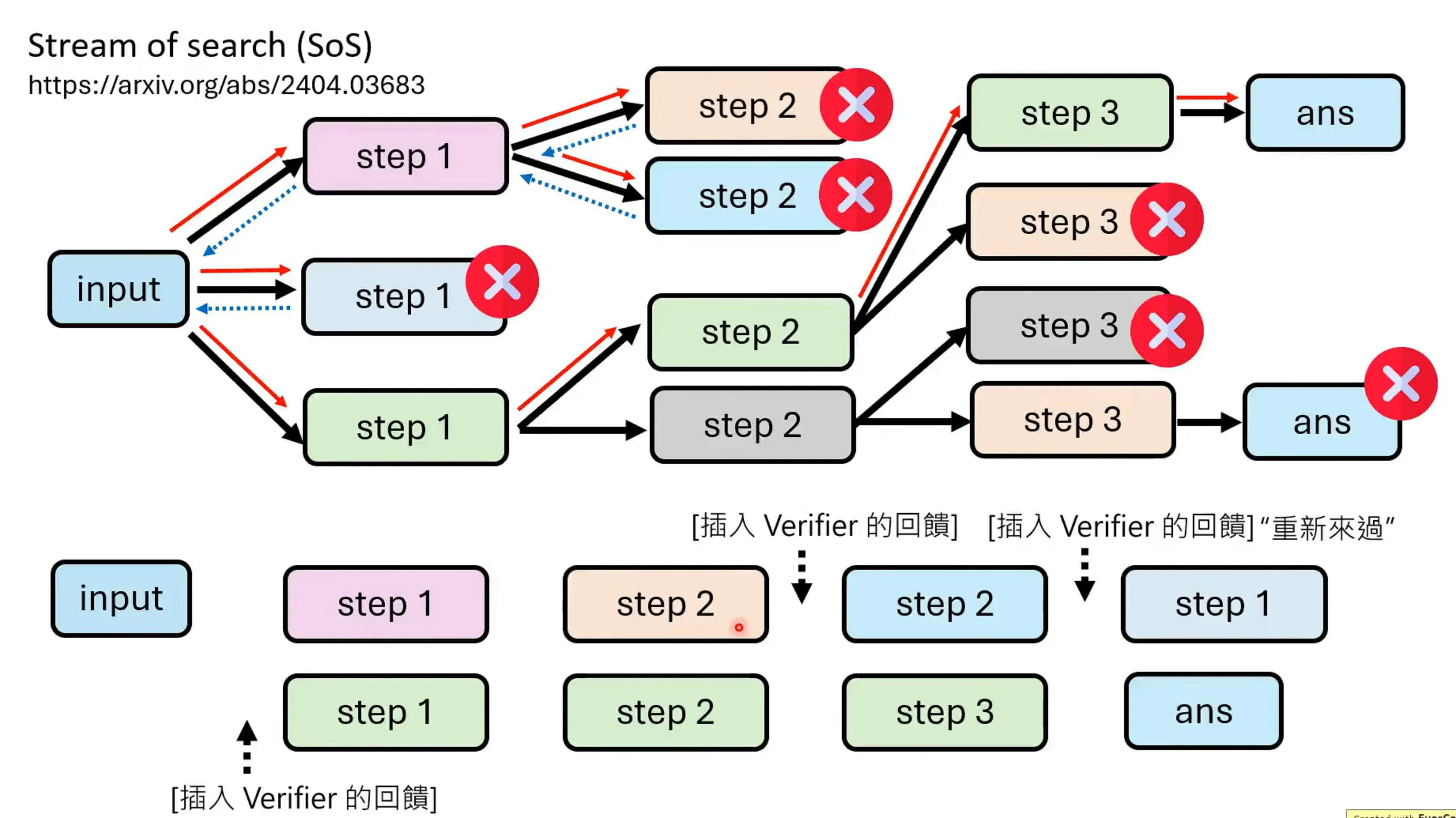 因此就有了journery learning的方法,让他去学习一些系列路径,包含不对的推理过程,最终得到正确的结果。
因此就有了journery learning的方法,让他去学习一些系列路径,包含不对的推理过程,最终得到正确的结果。
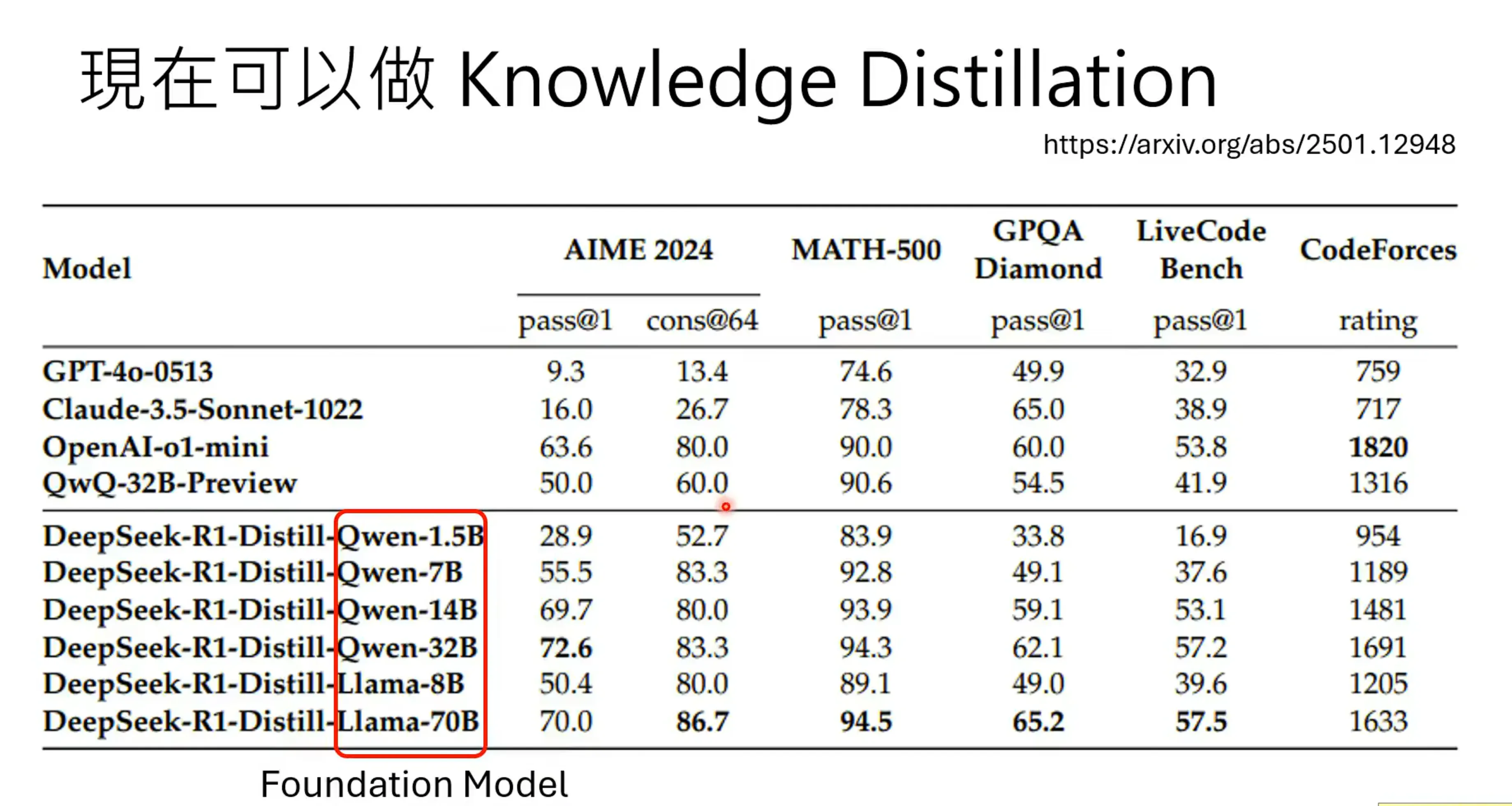
直接对Knowledge Distillation,对已有的Reasoning Model进行reasoning的学习,就可以得到不错的结果:
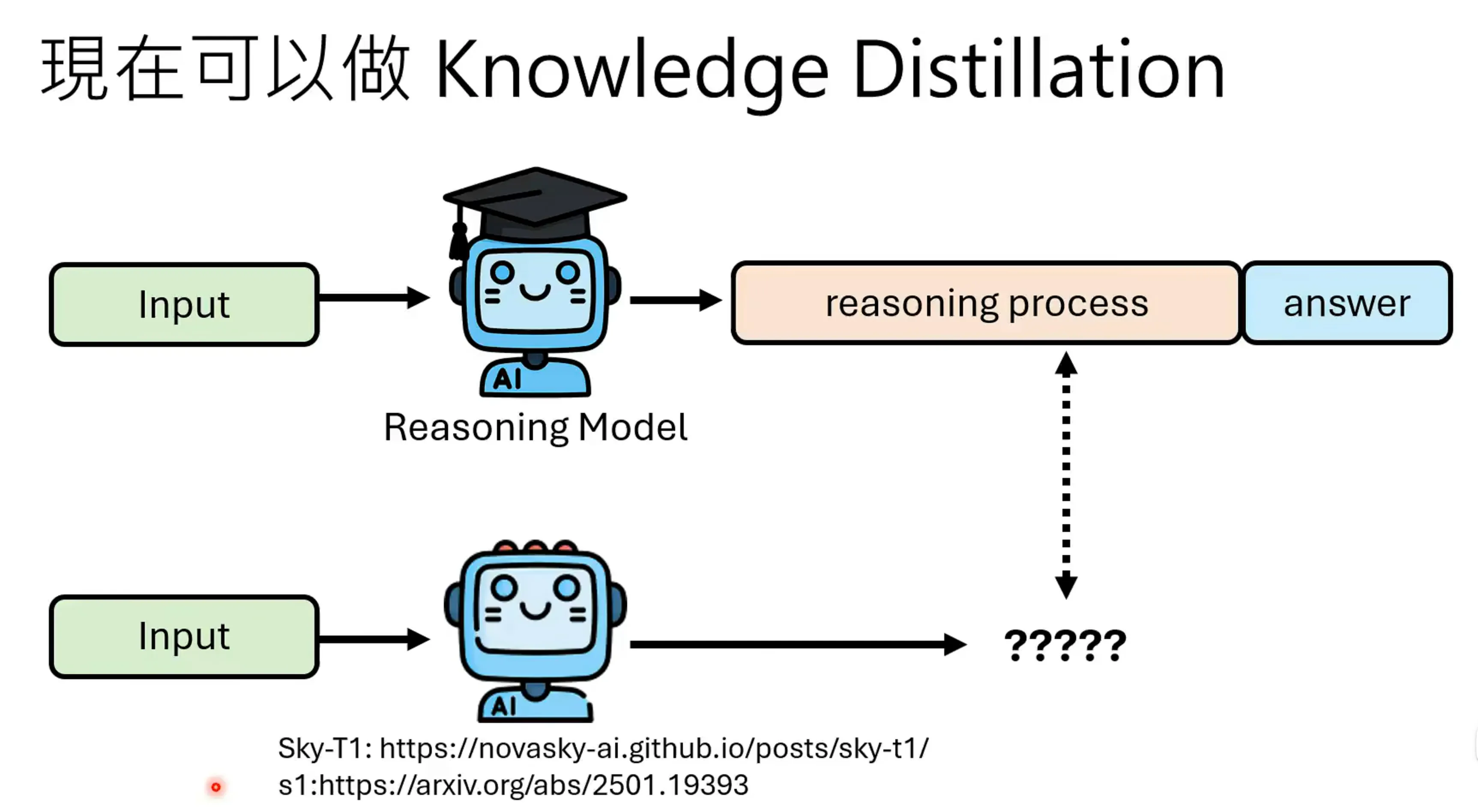
第二种方法是强化学习,以结果为导向教强化学习进行推理,这个也是deepseek-R1系列的做法。RL在学习过程中,Reasoning的过程不重要,答案结果是对的事最重要的。之前的方法我们也是对结果进行筛选,但我们也同时希望在reasoning的中间的过程中也是对的,但对于RL来说,我们并不管推论过程。
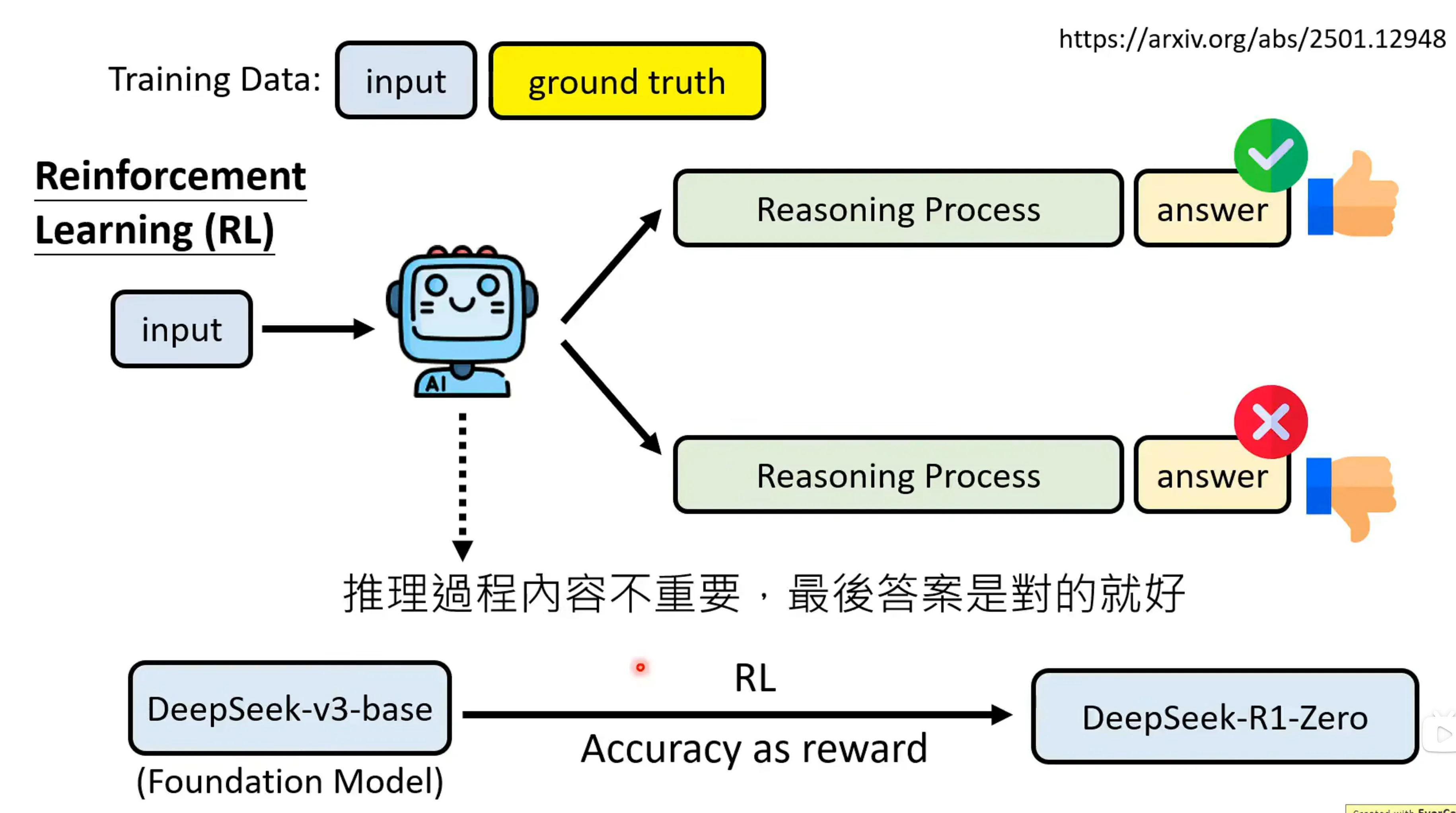 DeepSeek-R1-Zero就是用DeepSeek-V3-base进行post-training,并用准确率作为奖励。事实证明这种不管reasoning过程的方法是确实有用的。这四个方法彼此之间是没有冲突的。原则上是可以用majority vote来进一步强化的。R1-Zero只教了模型的结果,中间过程中做了什么可能会很混乱。
DeepSeek-R1-Zero就是用DeepSeek-V3-base进行post-training,并用准确率作为奖励。事实证明这种不管reasoning过程的方法是确实有用的。这四个方法彼此之间是没有冲突的。原则上是可以用majority vote来进一步强化的。R1-Zero只教了模型的结果,中间过程中做了什么可能会很混乱。
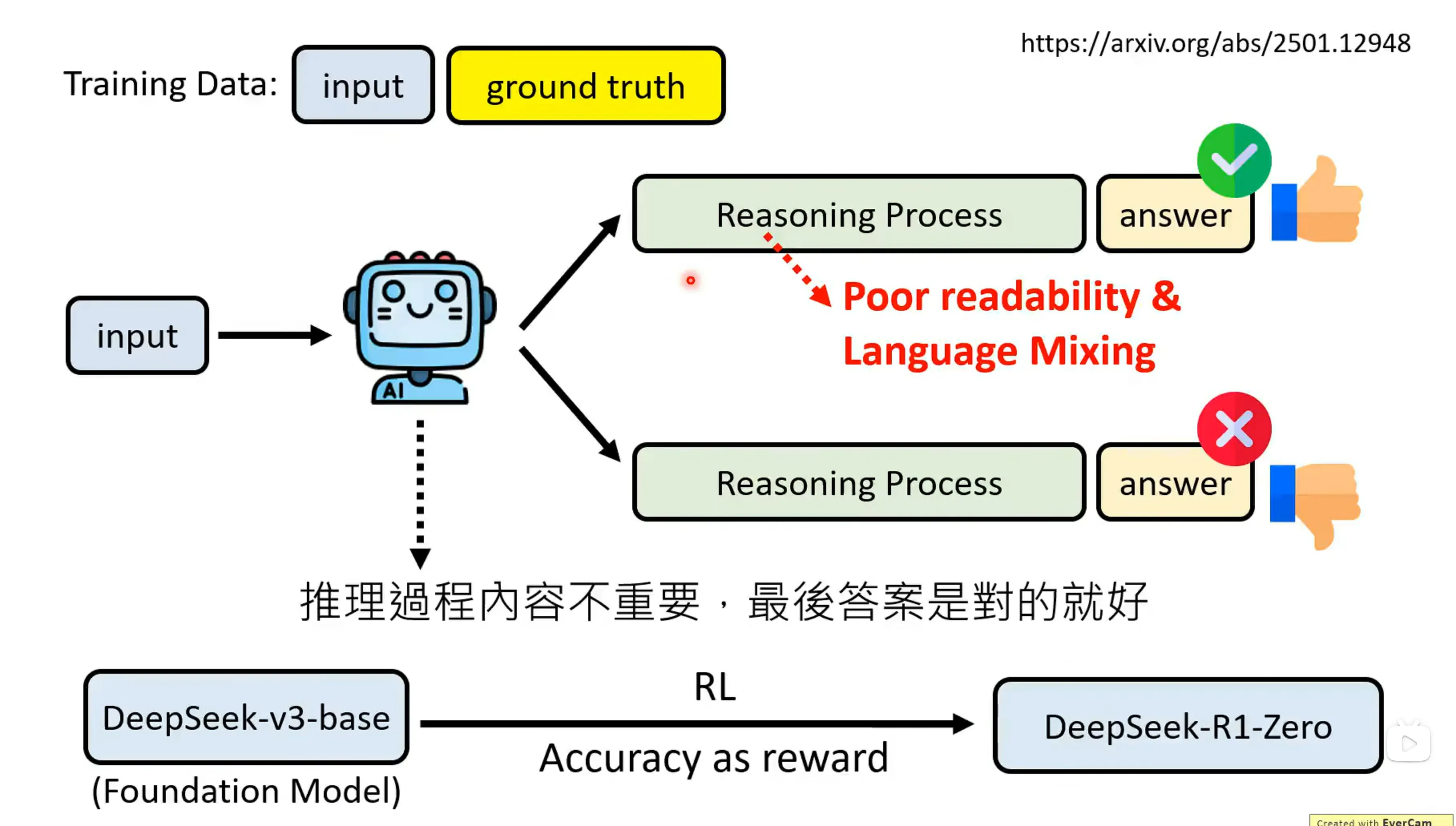
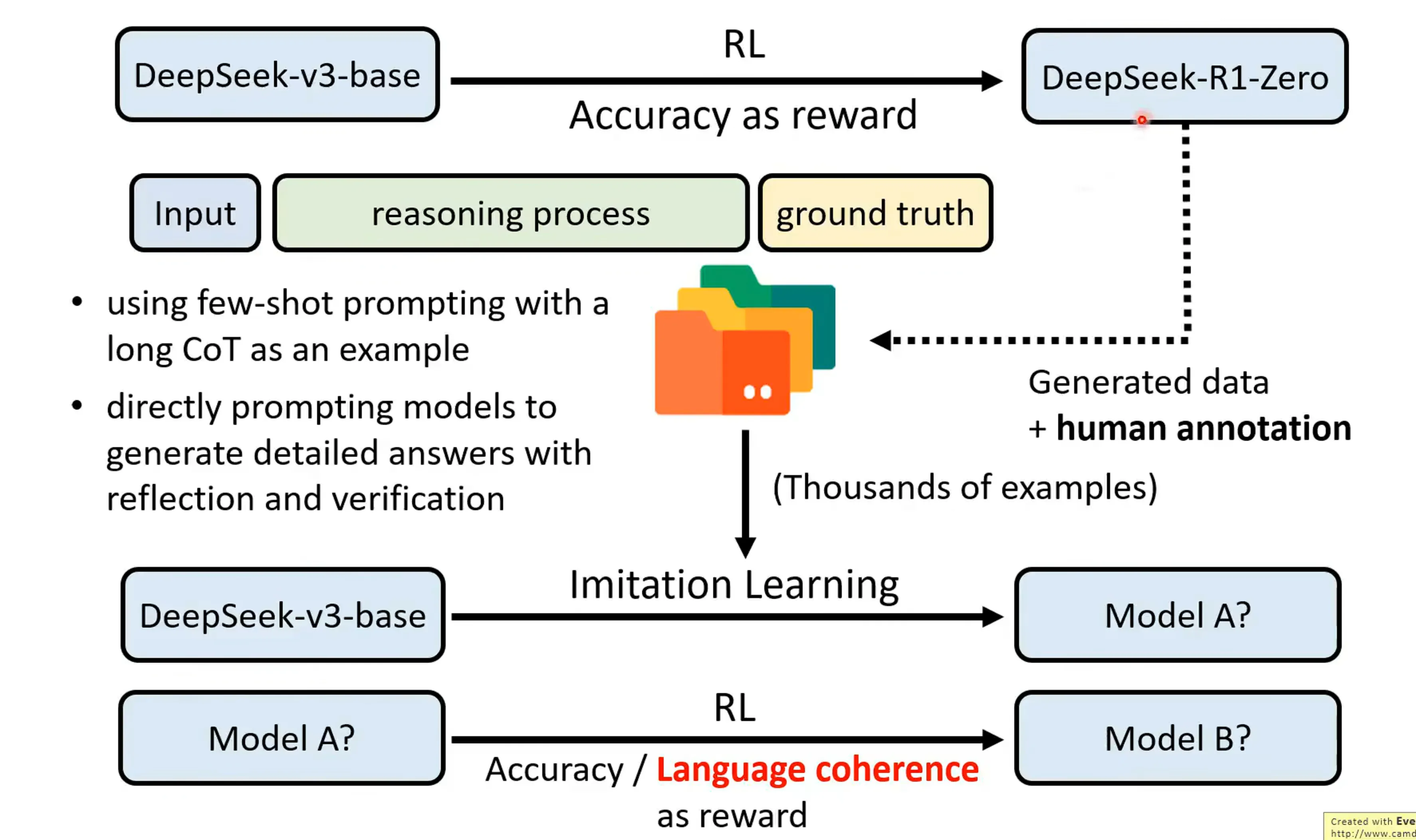
DeepSeek-R1打造的过程中实际上有很多流程,在第一步训练的过程中会人工进行筛选,并用Superviesed CoT的方式来进行训练。在训练modelA到modelB的过程中,会将Language的连续性作为一种reward,这回导致一定程度的性能下降,但是语言的连续性对于我们实际应用是很重要的。
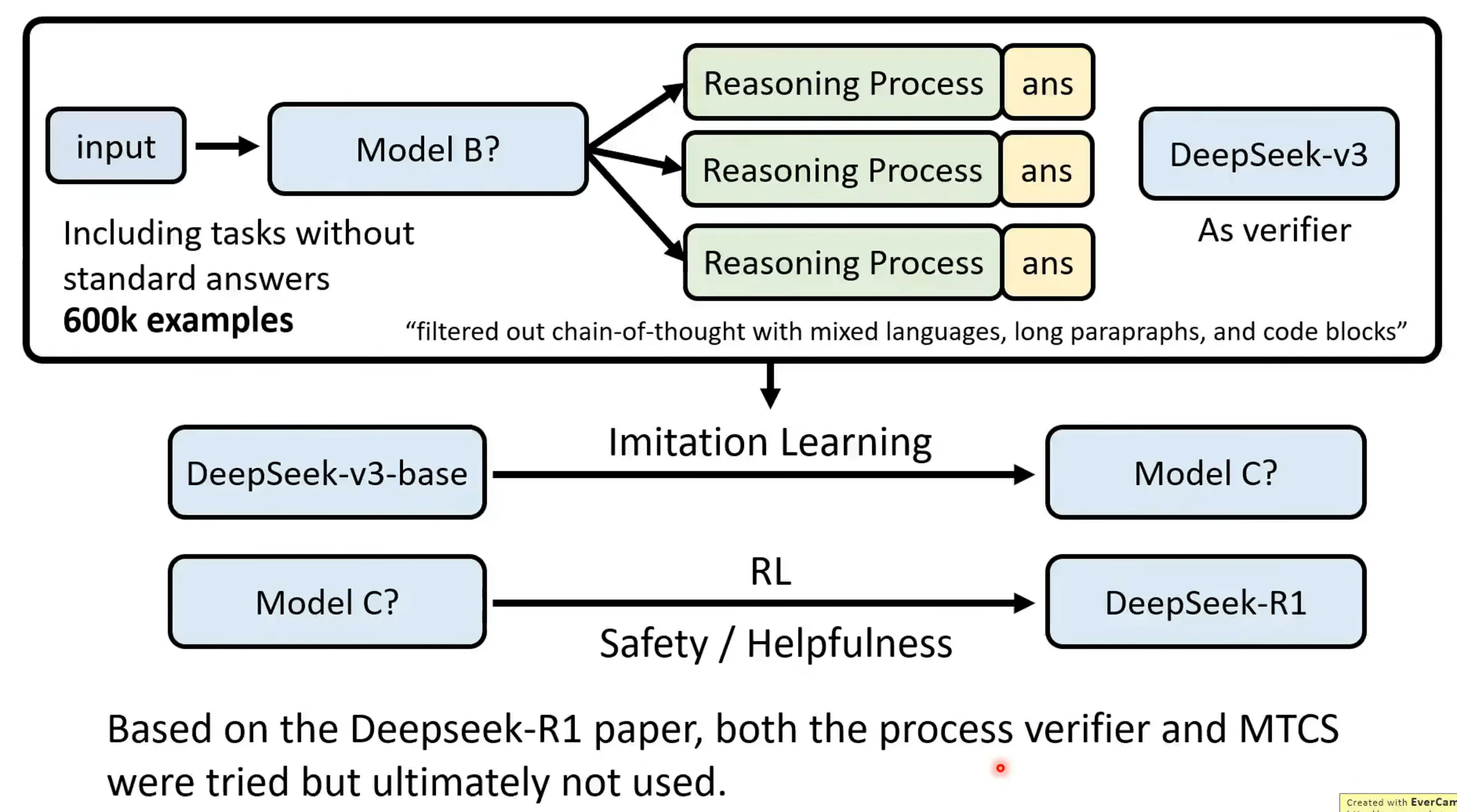
 Deep-Seek R1 reasoning有的时候的会有些混乱,因为它是由强化学习训练的,并没有在乎中间的过程。
Deep-Seek R1 reasoning有的时候的会有些混乱,因为它是由强化学习训练的,并没有在乎中间的过程。
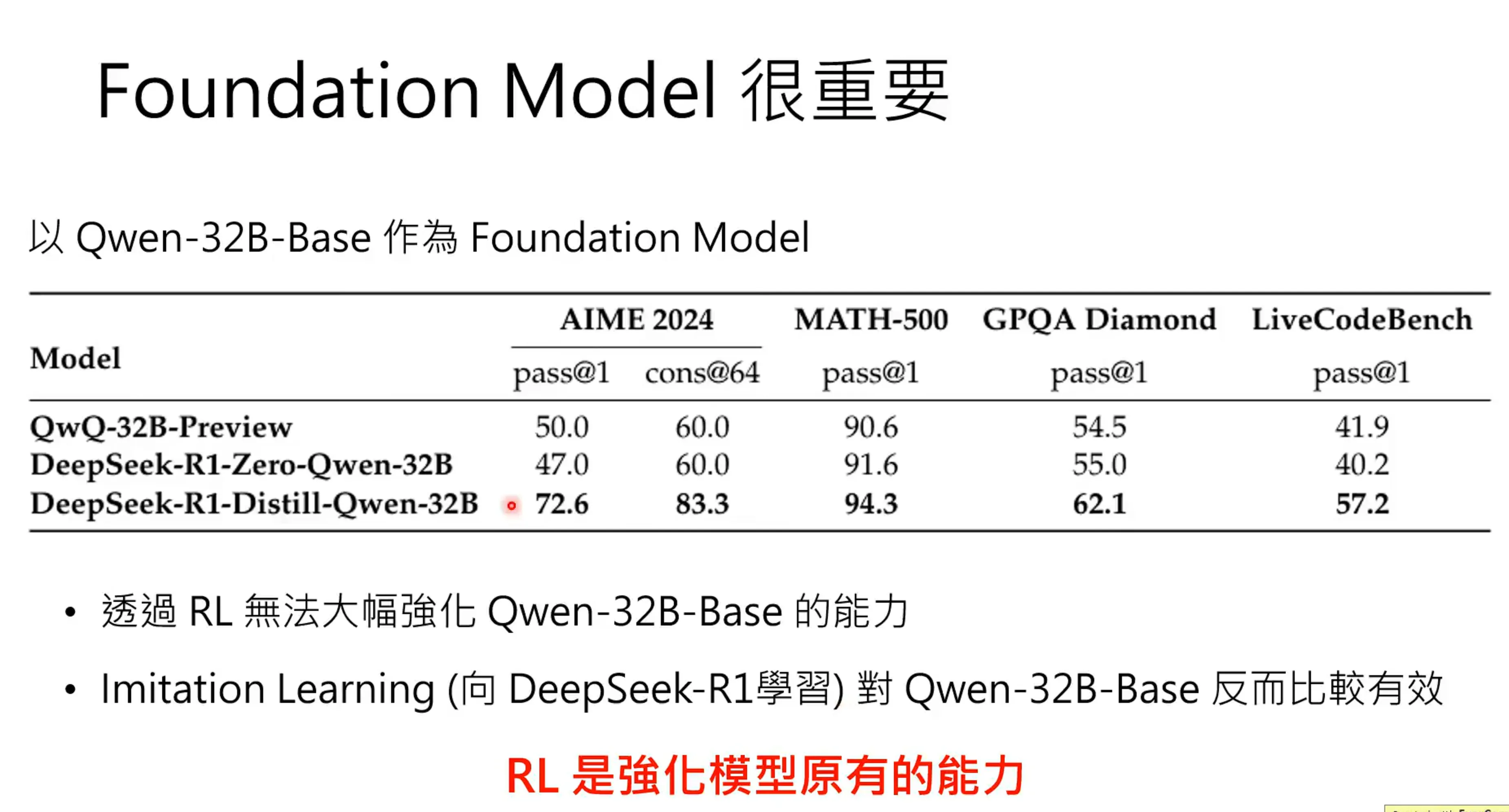 RL是强化模型原有的能力,也就是对于模型的正确的输出进行强化,这个前提是他得有足够多的正确的输出,如果原来的能力就不是很强,RL还是没办法激发reasoning的能力。其实deepseek-v3 base在做强化学习之前就有一定的reasoning的能力。
RL是强化模型原有的能力,也就是对于模型的正确的输出进行强化,这个前提是他得有足够多的正确的输出,如果原来的能力就不是很强,RL还是没办法激发reasoning的能力。其实deepseek-v3 base在做强化学习之前就有一定的reasoning的能力。

一个需要研究的方向就是让模型缩短整个推论的过程。
作业#
作业3理解LLM#
使用Gemma2-2b-it from google
Q1: 加入chat template和不加chat template对于coherence score的影响,
chat = [
{"role": "user", "content": question},
]实验结果表明使用正确的模版可以是的对话模型的输出质量显著提升,且模版能够维护多轮对话的上下文。
Q3: tokenization of a sentence 通过tokenizer.tokenize方法可以将句子进行token化,通过tokenizer.convert_tokens_to_ids方法可以将token转为id,并通过decode方法重新转为token,感觉是有个词表的概念的。不同的模型的词表可能是不同的,因为需要根据模型来加载tokenizer,tokenizer = AutoTokenizer.from_pretrained(“bert-base-cased”)
大模型中的top-k采样和top-p采样,大模型在利用auto aggressive预测下一个token的时候,如果只是贪心的选择概率最大的容易有问题,因此【top-k 采样思路】:在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
top-k 有一个缺陷,那就是“k 值取多少是最优的?”非常难确定。于是出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)。【top-p 采样:思路】:在每一步,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样(从高概率向低概率累加),而不考虑其他低概率的单词。这种方法也被称为核采样(nucleus sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分,可以抑制长尾问题。
还有一个temperature,在较低的温度下模型更具有确定性,较高的温度下变得不确定,反映了模型的创造力。top_p等于0创造性完全丧失,和top_k=1近似,变成一个确定性的结果。
loss的一个简单说明#
train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的)
train loss 不断下降,test loss趋于不变,说明网络过拟合;(max pool或者正则化)
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset)
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。(最不好的情况)